by stephen-w-thomas | Nov 23, 2016 | Stephen's BizTalk and Integration Blog
I have been working heads down for a few weeks now with Windows Azure Logic Apps. While I have worked with them off and on for over a year now, it is amazing how far things have evolved in such a small amount of time. You can put together a rather complex EDI scenario in just a few hours with no up front hardware and licensing costs.
I have been creating Logic Apps both using the web designer and using Visual Studios 2015.
Recently I was trying to use the Transform Shape that is part of Azure Integration Accounts (still in Technical Preview). I was able to set all the properties and manually enter a map name Then I ran into issues.
I found if I switched to code view I was not able to get back to the Designer without manually removing the Transform Shape. I kept getting the following error: The ‘inputs’ of workflow run action ‘Transform_XML’ of type ‘Xslt’ is not valid. The workflow must be associated with an integration account to use the property ‘integrationAccount’.
What I was missing was setting the Integration Account for this Logic App. Using the web interface, it’s very easy to set the Integration Account. But I looked all over the JSON file and Visual Studios for how to set the Integration Account for a Logic App inside Visual Studios.
With the help of Jon Fancy, it turns out it is super simple. It is just like an Orchestration property.
To set the Integration Account for a Logic App inside Visual Studios do the following:
1. Ensure you have an Integration Account already created inside the subscription and Azure Location.
2. Make sure you set the Integration Account BEFORE trying to use any shaped that depend on it, like the Transform Shape.
3. Click anyplace in the white space of the Visual Studio Logic App.
4. Look inside the Property Windows for the Integration Account selection windows.
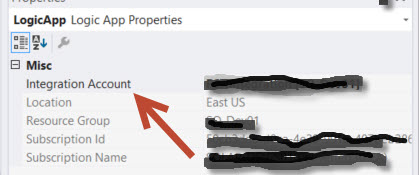
5. Select the Integration Account you want to use and save your Logic App.
It’s that simple!
Enjoy.

by michaelstephensonuk | Nov 17, 2016 | BizTalk Community Blogs via Syndication
Today we have so many technologies available when it comes to developing integration solutions. In some ways things are a lot easier and in other ways things are harder. One thing is for sure that in technology there has been a lot of change. For many organisations one thing that definitely has not changed is the challenges they face with the non-technical side of integration projects. You know for most companies, the technology you use for the implementation of the project isn’t that important when it comes to the decisive factor that determines success from failure. If you choose vendor A or vendor B, as long as your team know how to use the technology they will usually be able to build stuff successfully. With that said the thing organisations struggle with still is “how do we get the technology people to build something to do what we want it to do” and the IT organisation then has the challenge of how to live with that solution through its life span.
These are not technology problems, they are problems about communication, collaboration, documentation and allowing people the time to do stuff properly.
In my opinion two of the most common organisational challenges facing integration teams within a business today are:
- Shitty Requirements
Whenever I meet people around the world who are doing integration the one thing that seems to be a common challenge is that generally integration projects start off with a 1 line requirement. “I want to get this data from here to there”.
- Lack of Knowledge Sharing
The world of an IT department is generally a chaotic place so the idea of giving people time to do stuff properly is never really a thing for many organisations. Think of poor developers who barely finish writing code for one solution and then they are shipped to the next project and the department is generally surviving because of all of the information in people’s heads.
For many organisations the thing that is really needed is the ability to collaborate around projects in a way that brings people together and artefacts and information into one place. In some ways this is a big culture shift for some organisations and for others the problem is the lack of tooling. For quite a while now I have been a fan of combining TFS for source code, work items, and other stuff with Confluence and a few other tools but the challenge around the tooling is often licensing, procurement processes and the fragmented nature of using a number of different tools. Recently however I have been playing with Microsoft Teams and I think this is a really good package which I can see helping a lot of organisations. First off there are many ways your company could use it, but in this post I would like to talk about how it could help an integration team. Before going any further here are a couple of links which are useful:
How can my Integration Team Use Teams
First off in Microsoft Teams you could create a team and include people in your integration team. I would recommend not storing sensitive data in the teams area because what you want to do is open the transparency of your team so that your business users can work with you. Include your team members but your stakeholders and key business contacts should be included too. These are the people you will need to capture information from and you want them contributing to the team.
In terms of structuring your team in MS Teams I went for something like shown in the below picture.
Under the team you have Channels. I am thinking of using Channels for the following reasons:
- One for architecture related to the integration platform
- One for infrastructure related to the integration platform
- 1 Channel per interface or integration solution you develop
You may also choose to put in channels for guidance and training and other stuff like that.
What’s in a Channel
The cool thing about a channel is you have a few customization options about what you can have in the channel. Out of the box you get the following:
- Conversations – This is a bit like a slack/yammer style conversation thread
- Files – This is a place to upload documents related to the channel
- Notes – This is a one note work book for the channel
Those are some really handy things, you can also add other tabs to your channel like the below graphic:
My first thoughts for this are that you could use a SharePoint side as a tab to link to a site where you might store any sensitive stuff. You could also use planner as a light weight task board of to do stuff related to the channel. You could maybe link to Team Services for more complex planning.
In general the basic channel provides a way to have conversations, documents and stuff in a single place for a related context. Halleluiah, if we could have no more projects managed via email then the world would be a far less stressful place.
Channel Per Interface?
I mentioned above a few general channels for the bigger areas such as architecture and infrastructure, but one of the biggest wins could be a channel per interface. Imagine we had an interface which did a B2B style integration with a partner to send a list of customer marketing preferences so they could do out sources marketing for us. Think how many companies you may have worked with who may have delivered such an interface and they will often have an interface catalogue but it is usually just a spreadsheet list of interfaces they have (or more often it doesn’t exist), but if you asked the question “tell me everything about this interface”. Well I would guess in Average Company Inc, the answer would be to make you sit with 1 person who is the subject matter expert on it, they 2 more people who are stakeholders and know a bit about it. If your lucky there might also be some documents but I bet they get emailed to you and there are probably a few other documents which kind of say the same stuff but in a different way.
With MS Teams having 1 channel per interface means this list can be out interface catalogue, but it can also be the holder for everything about that interface. Lets have a look at what we could do:
Conversations
First off with conversations, imagine all discussion about the interface happens in 1 place. No more email threads. The conversation would still be available 2 years in the future when the original people on the project have left and the new people can see the history of discussion around the interface. Below shows some example conversations. Given this is just me but the example comments are from a real project. In many projects the history of the journey of how a project/interface got from start to implementation is a goldmine of knowledge which often leaves the organisation when the project is over. This can be avoided by using conversations.
Files
Files provides a simple place for any documentation which relates to the interface. Ideally any internal documentation produced by the team would be in the One Note notes which we will talk about in a minute. Often documentation is produced before your team is involved or gets supplied by vendors and its often a challenge to find where to keep it. This file store with the interface is a great option.
Below is an example:
You might ask why MS Teams and why not SharePoint. First off im not a big fan of documents. They are often old and obsolete and incorrect. I much prefer the wiki, one note and confluence style of approach. That said documents do still exist on projects. Keeping them close to the context where they are used just means they don’t get lost or forgotten about. I think using SharePoint if you need the added security etc that it brings is fair enough but for many cases its probably a bit over the top and just adds more steps to maintaining effective documentation.
Notes
Having a One Note workbook in the team is really cool. Im a big fan of using this for elaborating on the interface, flushing out requirements and then maintaining this for the support team and dev team for the long term. One Note encourages it to be light weight and effective documentation. This is a view of how we can use it. The page structure could look like below:
I think this is a minimum set of pages which will help you structure your information effectively.
The high level requirements page can just be a table of requirements which are teased out of stakeholders and taken from conversations in the team space. It might look like below:
The features and scenarios page would help us to write gherkin style stories of what we want the interface to do. These stories should be simple enough for everyone in the team to understand.
Next we might have message specifications. They could be json, xml, flat file, edi, etc. The key thing is to include sample messages and definitions of the messages so we know data is in the correct formats.
When it comes to the architecture element of your interface, I am a fan of the context, containers and components approach as a lightweight way of expressing the architecture of an interface. Although the diagrams below probably could be flushed out a bit more they will do for this example. In the One Note page I can start with some simple pen drawn diagrams to illustrate the key points. This is shown below.
Later when the project starts to stabilise I might choose to draw the diagrams in a more formal way using Visio or Lucidchart but certainly early in the project you spend lots of time redrawing the diagram as things evolve so lets keep it simple and use pen. You can open the One Note page in the full One Note client to get the richer drawing experience.
In the interface design section we can again elaborate on the interface further and include some specifics on the implementation. Again in the early stages I can just use pen drawn diagrams if I want and later replace them.
In the code and deployment pages id simple document what it does and how to deploy it. Im also a fan of using videos so we can do a video walk through of the code and upload it to the files section and provide a link to watch a walk through.
In the support page this will be a 2 way set of documentation between your ops/DevOps team and everyone else who is a stakeholder around support aspects of the interface. Everyone should be able to contribute from things developers learn in development and ops people also learn post go live. An example is below:
The notes should really be the living documentation to support the interface through its lifecycle.
Plan
I like the idea of being able to have planning options associated with the interface. I have some options here. First off for a higher level plan I can link to a Team Services project and see this at team level, but another option I really like is Planner. If your not familiar with it then this is a feature in Office 365 which is a bit like Trello. It gives me a basic task board and if I consider this to be at interface level it’s a great way to keep an eye on tasks at that level. You could include delivery tasks, bugs, technical debt clean up and loads of things specific to this interface. I think this is especially important post go live for the initial release of the interface as it gives you a place to keep tasks that may not be done until some future time as an optimisation activity.
In the below picture it shows the simple task board for Planner created directly from our Team channel
Power BI
One of the challenges of changing the culture is how to get people in contributing to the team, one of the best ways to do this is to connect and reporting or MI related to the interface to the Team channel. MS Teams lets you have multiple Power BI tabs in the channel and you can then bring in team dashboards. In the below picture I have chosen to bring in a UAT and Production dashboard for the interface as this lets the team see how things are performing in test and live.
I mean how cool is that!!
What about Cross Functional Teams
If you watched me talk at Integrate in 2016 you may remember how I talked about how organisations are changing from having centralised integration teams to cross functional teams which means those doing integration are all over the organisation. Well the reality of it is that that approach takes all of the non technical challenges organisations face and makes them worse. Possibly having multiple teams doing their own thing in their own way.
With MS Teams you can treat the Integration Team as a virtual team which is comprised of people who are in different delivery teams. What you want is them working in a manner with respect to integration that is aligned and allows for teams to create, change and disappear without knowledge leaving the organisation or your interfaces becoming orphaned. Using MS Teams to collaborate as a virtual team is a great way to support your organisation doing cross functional team based development while allowing your integration specialists to have visibility and to apply governance across those teams.
Conclusion
Im really excited about how I think MS Teams could be applied by integration teams to help solve some of the problems we face with many customers and organisations which fall into the culture, communication and collaboration space which lets face it has a much bigger impact on the overall success of your project than anything technical will.
Id love to hear how others are looking to use it.

by Nino Crudele | Nov 16, 2016 | BizTalk Community Blogs via Syndication
I’m preparing two next events, one in Italy and one in Belgium and this article wants to explain what I’m going to present and to speak about.
In the last months, I have been focused in many activities like, improve my knowledge, study new Azure stacks, improve GrabCaster with new features.
Microsoft is doing a lot of stuff around Azure, I’m impressed by the number of new features I see now in the portal and not just Microsoft but the entire IT world is producing any kind of new framework and pattern.
The IT world is changed, most of the companies now are more and more closed to use open source and I’m very happy about that.
The Cloud is now able to proposes so many options about IaaS or Application, Services and Data and more.
In my opinion Microsoft Azure now is the leader about services and integration, I’m not saying that because I’m Microsoft MVP or because I like to be closed to Microsoft, I think that because I’m not able to see the same offering in the other platforms.
Holistic education is a philosophy of education based on the premise that each person finds identity, meaning, and purpose in life through connections to the community, to the natural world, and to humanitarian values such as compassion and peace.
I think now we need to speak about holistic Integration because each technology in now able to find his identity, meaning, and purpose in the world of technology through connections to the others.
I normally use and mix all of the stacks like Service Fabric, Azure Functions, Logic App, GrabCaster, API management, Redis Cache and more together because I’m not able to achieve the best result using one only and each of these stack is absolutely specialized for a specific area.
Azure Function is something we can define as Nano Service oriented, very light and usable, very similar and, in the same time, very different from Azure Fabric for many reasons.
With Azure Fabric we have a concept of full reliable elastic scaling approach, Azure function is something we use for specific Nano tasks, but obviously we can extend the using of Functions to drive and manage specific logic in cloud.
I normally use GrabCaster for fast hybrid integration and to manage complex remotely event handling issues in on premise environment, and GrabCaster uses all the Microsoft Azure stacks to extend the capabilities and the results are impressive.
Logic App is now the workflow engine in the cloud, used to strictly correlate processes and services in the cloud, Microsoft is extending a lot this stack and we are able now to interconnect and consume the different Azure entities in fast way.
About messaging Service Bus is an ultra-mature stack but I know that Microsoft is preparing something fantastic, I can’t say anything more on that but, believe me, you will be happy.
Another interesting area is the Enterprise Integration Pack which is a complete stack we can use for EDI, VERTE and B2B, I’m waiting some more details regarding the pricing but it is awesome for fast VERTE and B2B integration.
Last and but not the least BizTalk Server which is going to the 2016 version, he is mature, solid and absolutely reliable and I have many nice surprises about BizTalk Server to present at the events.
Holistic is something characterized by the belief that the parts of something are intimately interconnected and explicable only by reference to the whole.
I always like to say…
We need to have a look to the whole if we want to be able to understand the single one.
If you are interesting to learn more about cloud then the Microsoft Academy is the best place for.
My next events will be:
WPC 2016 in Milan, the most important event in Italy about IT
You can register here.
At BTUG.be in Microsoft Belgium with the Belgium BizTalk User Group, I’m very to be there, the Belgium BizTalk User Group has many strong integration animals and great experts and I’m sure it will be a fantastic opportunity to share knowledge and good beer.
You can register here.
Looking forward to see you in one of these events.




