
by Sandro Pereira | Oct 30, 2018 | BizTalk Community Blogs via Syndication
And another whitepaper was published, this time an update to one of my classics: “Installing BizTalk Server 2016 in a Basic Multi-Computer Environment”!
There are many things to consider when planning this type of installation; often the network infrastructure already exists, and BizTalk Server must coexist with other network applications. This guide describes some of the considerations that apply to the various parts of a BizTalk Server installation in a basic multi-computer environment. This information will help you plan the installation and configuration of BizTalk Server 2016, applications and components on which it depends.

But this step-by-step guide is not only about installing BizTalk Server 2016, but it will also help you configure and optimize your environment.
What to expect about Installing BizTalk Server 2016 in a Basic Multi-Computer Environment whitepaper
This whitepaper will give you a detailed understanding of the following:
- BizTalk Server Installation scenario
- The need for a Domain Controller
- Preparing Computers for Installation
- Preparing and Install SQL Server 2016 machine
- Prepare and install prerequisites on BizTalk Server 2016 machine
- Testing environment connectivity
- Install and configure BizTalk Server 2016 machine
- Optimize the BizTalk Server 2016 environment.
Where I can download it
You can download the whitepaper here:
Once again, I would like to take this opportunity also to say thanks to Lex Hegt for helping me reviewing this whitepaper especially for the incredible work of him correcting my horrible English and in this way make the document and my thoughts being readable.
I hope you enjoy reading this paper and any comments or suggestions are welcome.
You can also find, download and enjoy several other free whitepapers of my own here:
You can download the Installing BizTalk Server 2016 in a Basic Multi-Computer Environment whitepaper here:
 Installing BizTalk Server 2016 in a Basic Multi-Computer Environment
Installing BizTalk Server 2016 in a Basic Multi-Computer Environment
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc. He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community. View all posts by Sandro Pereira
by Sandro Pereira | Oct 30, 2018 | BizTalk Community Blogs via Syndication
I recently published a new BizTalk Server Tips and Tricks article: “Automatically Generate Schemas from a Well-Formed XML instance” on my blog post series about “BizTalk Server Tips and Tricks” for developers, administrators or business users and I couldn’t resist on asking what about DTD?
Definition of DTD schemas
For who doesn’t know what DTD is, a DTD is a Document Type Definition that defines the structure and the legal elements and attributes of an XML document… So basically, it is the equivalent of what BizTalk Server uses to define how an XML document can be structured: XSD Schema. Nevertheless, there are many differences between DTD (Document Type Definition) and XSD (XML Schema Definition). In short, DTD provides less control on XML structure whereas XSD (XML schema) provides more control.
Some of you may wonder, who cares? No one uses DTD anymore, so why bother?
Yes, indeed DTD is not used very regularly nowadays, and it is very probable that you will never use it… unless… for example, you are working with RosettaNet or in the future, you will have the need to work with RosettaNet. Why? Because most of the RosettaNet Standards – PIP messages – are defined in the format of DTD format!
As I mentioned in my previous blog, there are several ways we can create an XML Schemas in BizTalk Server:
- Manually from the scratch
- From XDR Schema instance
- From a DTD instance
- From a well-formed XML instance
- Import them from a WCF Service or Web Service
- Or automatically generated them from LOB systems (from the adapters)
Generating schemas based on a DTD instance
Today we will be talking about automatically generating XML Schemas from a DTD instance.
To accomplish this we need to:
- In Solution Explorer, right-click a BizTalk project, point to Add, and then click Add Generated Items…

- In the Add Generated Items – <BizTalk ProjectName> dialog box, in the Templates section, click Generate Schemas, and then click Add

- In the Generate Schemas dialog box, in the Document type drop-down list, select DTD

- One of the problems, especially in brand new installations, is that sometimes this feature was not installed, and you will see DTD (Not Loaded) in the drop-down list. To install and use this feature you need to:
- Navigate to the “SDKUtilitiesSchema Generator” folder present in the BizTalk Server installation folder. Normally this will be “C:Program Files (x86)Microsoft BizTalk Server <version>SDKUtilitiesSchema Generator”
- And execute the InstallDTD.vbs script by double-clicking. This will install the “Microsoft.BizTalk.DTDToXSDGenerator.dll” DLL on the correct place. This basically means that it will copy this DLL to the “Developer ToolsSchema Editor Extensions” folder present in the BizTalk Server installation folder
- Or manually “Microsoft.BizTalk.DTDToXSDGenerator.dll” DLL to the “Developer ToolsSchema Editor Extensions” folder present in the BizTalk Server installation folder. Normally this will be “C:Program Files (x86)Microsoft BizTalk Server <version>Developer ToolsSchema Editor Extensions
- Close the Generate Schemas dialog box and do the previous steps again. Now you will be able to see that you can use the option DTD in the drop-down list

- In the Generate Schemas dialog box, click Browse, locate the file you want to import, click Open and then click OK
- A new schema, or sometimes at least two schemas are generated from the specified file, using the same name as that file with the .xsd extension, and opened in BizTalk Editor
Quick, simple and practical.
Stay tuned for new Tips and Tricks!
Author: Sandro Pereira
Sandro Pereira is an Azure MVP and works as an Integration consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc. View all posts by Sandro Pereira
by Gautam | Oct 28, 2018 | BizTalk Community Blogs via Syndication
Do you feel difficult to keep up to date on all the frequent updates and announcements in the Microsoft Integration platform?
Integration weekly update can be your solution. It’s a weekly update on the topics related to Integration – enterprise integration, robust & scalable messaging capabilities and Citizen Integration capabilities empowered by Microsoft platform to deliver value to the business.
If you want to receive these updates weekly, then don’t forget to Subscribe!
Feedback
Hope this would be helpful. Please feel free to reach out to me with your feedback and questions.

by Sandro Pereira | Oct 25, 2018 | BizTalk Community Blogs via Syndication
BizTalk Pipeline Components Extensions Utility Pack community project for BizTalk Server 2016, once again, got a new update and it now has a new component that you can use in your custom BizTalk Server pipelines: Unzip File Pipeline Component.
Unzip File Pipeline Component
The Unzip File Pipeline Component for BizTalk Server can be used in a Received pipeline (Disassemble stage), and it allows you to receive a compress (zip/gzip) file and extract its contents into different XML messages.
- The capabilities are like those available in any compression software such as WinZip or 7-zip:
- This component doesn’t require any configurations.
This was an old component that I had that I now updated and improved to BizTalk Server 2016 with the help with my internal team at DevScope, in particular, Pedro Almeida.
You do not need to add a custom pipeline component to be used by the BizTalk Runtime to the Global Assembly Cache (GAC).
What is BizTalk Pipeline Components Extensions Utility Pack?
BizTalk Pipeline Components Extensions Utility Pack is a set of custom pipeline components (libraries) with several custom pipeline components that can be used in received and sent pipelines, which will provide an extension of BizTalk out-of-the-box pipeline capabilities.
The project is available on BizTalk Server Open Source Community repository on GitHub (https://github.com/BizTalkCommunity), and everyone can contribute with new pipeline components that can be extended or improve the existing BizTalk Server capabilities.

At the moment it is only available for BizTalk Server 2016, but it will soon be compiled and available for previous versions of the product.
Where to download it?
You can download BizTalk Pipeline Components Extensions Utility Pack from GitHub here:
BizTalk Pipeline Components Extensions Utility Pack
GitHub
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc. He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community. View all posts by Sandro Pereira
by Senthil Kumar Palanisamy | Oct 25, 2018 | BizTalk Community Blogs via Syndication
Introduction
Custom widgets are powerful feature in BizTalk360, that allow the users to bring third-party integrations into BizTalk360. It will be useful to bring the custom solutions into the BizTalk environment as it allows to view integrated solutions in one single tool.
Custom widgets can be used for various purposes, below list constitute few important scenarios;
- Embed third-party portals like Power BI or internal portals
- Monitor BizTalk Artifact Statuses
- Display query results using Secure SQL Queries
In this article, we can see important best practices while creating Custom widgets.
Best Practices
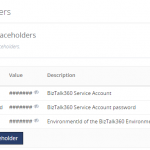
1. Hiding confidential information in Custom Widgets with Placeholders
Custom Widgets are created using API’s (e.g.: BizTalk360 or BizTalk Integration API), which might contain confidential information like the credentials of your BizTalk360 Service Account or API Authenticated credentials. Of course, you don’t want this information to be revealed in plain text in your widgets. To hide such confidential information, you can use Placeholders.
Beside using Placeholders to hide confidential information, you can also use them for providing frequently used data to your Custom Widgets. Think of for example the BizTalk360 “EnvironmentId”, which is a value which often needs to be provided to Custom Widgets. By creating a Placeholder for the “EnvironmentId”, you can easily re-use it and you don’t need to search for such values, each time you are creating a Custom Widget which needs such a value.
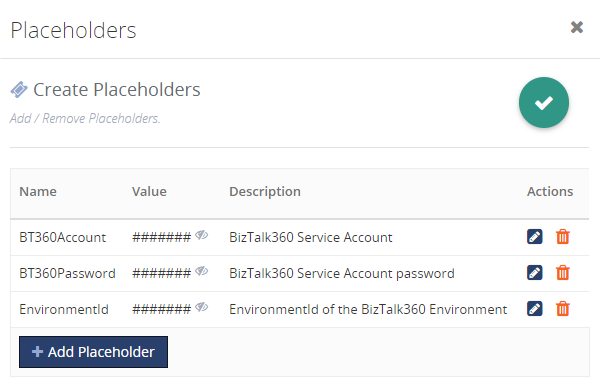
Read this article to know more about creating the place holders and how it can be used in widget.
2. Knockout JS Functions
Frequently, utility functions are used while binding the data to view. In these situations, the user can utilize the BizTalk360 referenced utility functions.
BizTalk Integration API methods returns its responses in XML format. To represent the data in client script(JavaScript/jQuery),it needs to be in JSON format.
x2js = new X2JS({ attributePrefix: '' });
bizTalkHostsList = function ()
{
var _this = this;
_this.getBizTalkHosts(function (data)
{
_this.bizTalkHosts(x2js.xml_str2json(data.queryResult));
});
};
When a view expects the API method to return the result as an array, occasionally a single record is produced. In this situation,the API result needs to be converted to an array.
x2js = new X2JS({attributePrefix: '', arrayAccessForm:"property",
arrayAccessFormPaths : ["root.records.record"]});
bizTalkSendPortsList = function () {
var _this = this;
_this.getbizTalkSendPorts(function (data)
{
var results = x2js.xml_str2json(data.queryResult);
if (Array.isArray(results.root.records.record))
_this.bizTalkSendPorts(results.root.records.record);
else {
_this.bizTalkSendPorts([results.root.records.record]);
}
});
};
3. BizTalk360 Styles and Icons
The styles of BizTalk360 can be used in custom widgets by inspecting the element in the BizTalk360 Application. You can take advantage of the listed styles and controls while creating the custom widgets.
CSS Styles
Utilize BizTalk360 in-built CSS in custom widget creation
- List the data in Table: table table-lists
- Scroll Bar: WidgetScroll
<div id=”WidgetScroll” style=”top:30px;” data-bind=”addScrollBar: WidgetScroll, scrollCallback: ‘false'”>
<table class=”table table-lists”>
</table>
</div>
- Success/Info Tag: Use the Success or Information tag based the data to be presented in the list
<span data-bind="text: HostType == 1 ? 'InProcess' : 'Isolated', css: HostType == 1 ? 'success-tag' : 'info-tag'">
</span>
Boot Strap
Boot Strap styles and tags could be used during widget creation. BizTalk360 uses Boot Strap styles to design the base layouts.
- Container Fluid
- row
- col-md-*
<div class="container-fluid">
<div class="row">
<div class="col-md-8"></div>
<div class="col-md-4"></div>
</div>
</div>
Font Awesome Icons
Users can represent status or any information in graphical way, you can use Font Awesome Icons.
- Success – fa fa-check-circle
- Error – fa fa-power-off
- Warning – fa fa-times-circle
KendoUI Controls
BizTalk360 uses KendoUI controls, users can utilize those controls in widget script
- Drop Down
- Grid
- Switch Box
- DateTime Picker
- Numeric Text Box
- Calendar
// View
<div class="form-group margin-t"> //Boot Strap Form Group
<div class="col-md-10"> // Boot Strap Column
<div class="col-md-offset-2">
<div class="alert alert-info" role="alert"> //Boot Strap Information
<b>Note :</b> Choose the environment and enable the servers for Event Log data to be collected.
</div>
<div class="form-horizontal">
<div class="form-group" data-bind="validationElement: selectedEnvironment">
<label class="col-md-3 control-label">Select Environment</label>
<div class="cus-select" style="text-align: left;">
<label>
<select data-bind="options: configuredEnvironments, optionsText: 'name', value: selectedEnvironment"
class="form-control" style="min-width:300px;"></select> // Kendo Dropdown
</label>
</div>
</div>
</div>
</div>
</div>
</div>
//ViewModel
selectedEnvironment.subscribe(onEnvironmentChanges, this); // change event to the environment
4. Embedding Third-Party Scripts
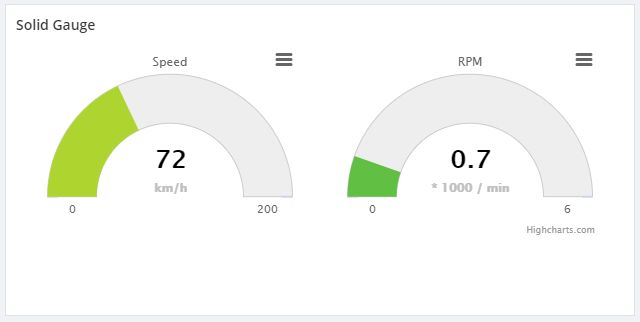
BizTalk360 uses a component called High Charts to represent data in graphical way. Also, some of our customers are using the custom widgets to represent their BizTalk Integration in graphical chart. BizTalk360 supports High Charts (Basic Widgets) with High Chart JS. To reference the third-party scripts, use the following JavaScript to reference the external libraries.
function injectScript(src) {
return new Promise((resolve, reject) => {
for (var i = 0; i < src.length; i++) {
var script = document.createElement('script');
script.src = src[i];
script.async = false; // This is required for synchronous execution
document.head.appendChild(script);
}
script.addEventListener('load', resolve);
script.addEventListener('error', () => reject('Error loading script.'));
script.addEventListener('abort', () => reject('Script loading aborted.'));
document.head.appendChild(script);
});
}
injectScript(['https://cdnjs.cloudflare.com/ajax/libs/highcharts/5.0.14/highcharts-more.js','https://cdnjs.cloudflare.com/ajax/libs/highcharts/5.0.14/js/modules/solid-gauge.js'])
Customer scenarios
Through our support channel, customers are explaining their scenarios which they require in their day to day activities. Here, we pick few common scenarios that will be useful in BizTalk Integration space.
Monitor Artifacts of a BizTalk application
BizTalk360 has the capability to monitor multiple application artifacts in a single alarm configuration. For instance, a specific group of users wants to monitor the status of specific application artifacts. To achieve this requirement, custom widget creation is one of the possible solutions. Create the custom widget to monitor an application artifacts status and associate the widget to dashboard. You can download the custom widget of monitoring the application artifacts.
Secure SQL Queries
Secure SQL query is an important feature to fetch data based on the user’s business demand. However, it is hard to create all the possible transaction results out of box from predefined widgets. Custom Widgets will help the BizTalk360 users to address this gap in BizTalk360.
Please follow the article how to create custom widgets using Secure SQL Queries.
Represent the data using Cross Domain API and High Charts
A user wants to represent BizTalk Integration Transaction details in the graphical chart. The Integration API is hosted cross domain. To access the cross-domain API Methods through client script, you need to use the XMLHTTPRequest method
function createCORSRequest(method, url) {
var xhr = new XMLHttpRequest();
if ("withCredentials" in xhr) {
// XHR for Chrome/Firefox/Opera/Safari.
xhr.open(method, url, true);
} else if (typeof XDomainRequest != "undefined") {
// XDomainRequest for IE.
xhr = new XDomainRequest();
xhr.open(method, url);
} else {
// CORS not supported
xhr = null;
return xhr;
}
//Make the actual CORS request
function makeCorsRequest(url,method) {
var xhr = createCORSRequest(method, url);
if (!xhr) {
alert('CORS not supported');
return;
}
// Response handlers
xhr.onload = function() {
var resultData = xhr.responseText;
expectedResults(x2js.xml_str2json( JSON.parse(resultData).MonitorQueryResult).root.records.record);
}
xhr.onerror = function() {
alert('Woops, there was an error making the request.')
}
xhr.send();
}
makeCorsRequest(‘https://YOURCROSSDOMAIN/SERVICENAME’,'GET');
In this case, the user wants to represent the data in High Charts solid-gauge pattern . For that, you can use the above mentioned suggestion “Embed Third-Party Script”.
Conclusion
Custom widget is a useful feature to bring the customized solution in a dashboard. Hope this article will be helpful to get start the custom widgets creation. Get started with the free 30 days trial. For any queries/feedback please write to us support@biztalk360.com.
Author: Senthil Kumar Palanisamy
Senthil Kumar Palanisamy is the Technical Lead at BizTalk360 having 14 years of experience in Microsoft Technologies. Worked various products across domains like Health Care, Energy and Retail. View all posts by Senthil Kumar Palanisamy
by Sandro Pereira | Oct 23, 2018 | BizTalk Community Blogs via Syndication
Welcome back to my blog post series “BizTalk Server Tips and Tricks” for developers, administrators or business users.
There are several ways we can create an XML Schema in BizTalk Server:
- Manually from scratch
- From XDR Schema instance
- From a DTD instance
- From a well-formed XML instance
- Import them from a WCF Service or Web Service
- Automatically generated them from LOB systems (from the adapters)
Today, we will be talking about automatically generating XML Schemas from a well-formed XML instance. To accomplish this we need to perform the following steps:
- In Solution Explorer, right-click a BizTalk project, point to Add, and then click Add Generated Items…

- In the Add Generated Items – <BizTalk ProjectName> dialog box, in the Templates section, click Generate Schemas, and then click Add

- In the Generate Schemas dialog box, in the Document type drop-down list, select Well-Formed XML

- One of the problems, especially in brand new installations, is that sometimes this feature was not installed, and you will see Well-Formed XML (Not Loaded) in the drop-down list. To install and use this feature you need to:
- Start a Windows Explorer and navigate to the “SDKUtilitiesSchema Generator” folder present in the BizTalk Server installation folder;
- Normally it will be “C:Program Files (x86)Microsoft BizTalk Server <version>SDKUtilitiesSchema Generator”
- Execute the InstallWFX.vbs script by double-clicking. This will install the “Microsoft.BizTalk.WFXToXSDGenerator.dll” DLL on the correct place
- That basically means, it will copy this DLL to the “Developer ToolsSchema Editor Extensions” folder present in the BizTalk Server installation folder
- Or manually copy “Microsoft.BizTalk.WFXToXSDGenerator.dll” DLL to the “Developer ToolsSchema Editor Extensions” folder, present in the BizTalk Server installation folder
- Normally, it will be “C:Program Files (x86)Microsoft BizTalk Server <version>Developer ToolsSchema Editor Extensions
- Close the Generate Schemas dialog box and do the previous steps again, and now you will be able to see that you already can use the option Well-Formed XML in the drop-down list.

- In the Generate Schemas dialog box, click Browse, locate the file you want to import, click Open and then click OK

- A new schema, or sometimes at least two schemas are generated from the specified file, using the same name as that file with the .xsd extension, and opened in BizTalk Editor
TIP: Before you generate the schemas, rename the XML instance file that you will be using to the proper name you want to give to the Schemas, this will save you time because the Generator Wizard will:
- Give the same name of the specified file with the .xsd extension
- Or will add a sequence to the same name of the specified file with the .xsd extension
In the end, as a best practice, you should rectify or rename the schemas generated to something with context and that will be easy to identify:
If you want it to be perfect, then for each schema, you should change not only the name of the file, but also the Type Name property of each schema.

Initially, this value was set as “myfilename_0”.
The problem of renaming the filename and/or the Type Name property is that once you try to compile it will give you errors because some schemas will be referring files that no longer exist (were renamed):
To solve this, we need to:
- Open the Schema and select the Schema node at the top of the schema tree view
- In the Properties window, in the Advanced category, in the value portion of the Imports property, click the ellipsis (…) button
- In the Imports dialog box, in the Import Schema list, delete the XSD Import line, import the correct one and then click OK

- Alternatively, open the schema file in Notepad (Notepad ++ or other text editors) and rectify the path and filename
Quick, simple and practical!
Stay tuned for new tips and tricks!
Author: Sandro Pereira
Sandro Pereira is an Azure MVP and works as an Integration consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc. View all posts by Sandro Pereira
by Gautam | Oct 21, 2018 | BizTalk Community Blogs via Syndication
Do you feel difficult to keep up to date on all the frequent updates and announcements in the Microsoft Integration platform?
Integration weekly update can be your solution. It’s a weekly update on the topics related to Integration – enterprise integration, robust & scalable messaging capabilities and Citizen Integration capabilities empowered by Microsoft platform to deliver value to the business.
If you want to receive these updates weekly, then don’t forget to Subscribe!
Feedback
Hope this would be helpful. Please feel free to reach out to me with your feedback and questions.
by Ahmed Taha | Oct 18, 2018 | BizTalk Community Blogs via Syndication
In our series of Guest Bloggers, we are pleased to announce Ahmed Taha, from LinkDev, Egypt! Ahmed is not new to the community as he has already hosted some Integration Monday sessions and loves to visit real-world events as well. We thought that his last Integration Monday session would make a good read, so he converted that session to this blog post. You can view this Integration Monday session from the Integration user Group web site. A warm welcome to Ahmed!
Introduction
A few years ago, I had an extremely challenging requirement in a BizTalk project that was integrating the customer’s system with several web services from disparate external backend systems. These systems had different communication protocols, message formats, and throughput limits.
The latter requirement was extremely challenging to implement, and it is actually not a very common one. However, it is worth noting that lately, I have been seeing this requirement, stated more often in new customers’ request for proposal (RFP) documents.
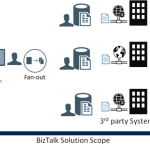
Landscape
First, let me paint a complete picture for you, with the overall landscape.

As a first stage, the flow starts with an upstream system that has multiple input channels for entering and storing user entities into a staging data store.
In the second stage, the integration scope starts by polling user entity batches from the staging data store. Next, a fan-out approach is conducted, to scatter each single user entity into multiple requests, one for each web service, from a wide range of external web services.
Afterwards, the response data from each web service is stored separately in a dedicated table entity inside the same database, in a fragmented manner.
At the third and final stage, a mission-critical downstream system is continuously analysing these fragmented data for all the users, to perform critical data processing needed for decision making, as well as provide near real-time reporting from the aggregation of the response data.
Customer Requirements
The following are some of the key generic requirements:
- The entire process will be performed continuously, governed by a set of pre-defined business rules that determines if already fetched data fragment is stale, and needs to be refreshed
- The upstream staging data store will usually contain a large volume of user entities, and the upstream system input is expected to be of high throughput
- There are also some business rules that govern the routing logic, to decide which external systems need to be invoked, based on selected user criteria
So far, these above-mentioned requirements could easily be implemented as a BizTalk messaging solution, along with Business Rules Engine (BRE) policies to apply the governing business rules. For a robust messaging solution, I would highly recommend that you leverage the powerful BRE pipeline framework. Check my article on BRE pipeline framework.
Now, here comes the more challenging set of requirements, and if you are like me, you would be excited for having a good challenge, every now and then:
- Each of these back-end web services allowed for a maximum throughput (i.e. transactions per minute) which must not be exceeded, subsequent requests beyond that limit will fail
- At the same time, the integration solution must not invoke the services at rates that are way below the defined throughput limit, to maintain the overall efficiency of the solution

- These throughput limits should be configurable and could be variable based on specified time ranges, days of the week, date ranges, or a combination from all these options. BRE DB-facts were used for this requirement, coupled with a web-based control panel for the configurable DB values. The DB prefixes shown below denotes the BRE DB-facts.
 To come up with the right solution, some research was necessary. During that research, few different approaches were tried:
To come up with the right solution, some research was necessary. During that research, few different approaches were tried:
- Throttling Aggregator Orchestration
- Throttling Pipeline Component
Both approaches are described below.
First Approach – Throttling Aggregator Orchestration
Using an orchestration might be the first thing to come to your mind, in order to control and throttle the incoming messages in a stateful manner using the orchestration canvas.
This is a straight-forward implementation of an aggregator orchestration, which will run as a singleton orchestration instance for each defined back-end system.
To implement the actual throttling effect, the orchestration will simply include a delay shape that introduces the required latency in-between the incoming requests, in order to achieve the required throughput for a given back-end system.
For instance, a back-end system with a throughput limit of (6) requests per minute, will require the delay shape to induce a (10) second delay before every request in its corresponding orchestration instance.

Let’s have a look at the overall message flow. It starts with a polling receive location, where a pipeline component applies the required business rules and enriches the message context with throttling-related & routing-related information, before scattering the polled request into multiple requests, one for each designated back-end service.
A singleton orchestration for each system will apply the required throttling. You will notice that the orchestration is leveraging BRE & DB-facts to get the DB configured throttling information for the given back-end system. Memory cache is used to enhance the performance by minimizing the overhead impact of the BRE DB-facts during the BRE policy call.
While the orchestration approach works well, there are some caveats you should be aware of:
- Orchestration Delay shape is not very accurate when it comes to high precision, small delay values
- Orchestration persistence points will add extra latency which, in turn, lower the overall throughput outcome even further than intended
- Zombie messages are an inevitable byproduct of aggregator orchestrations, this will happen if the orchestration is designed to terminate after an idle time, or gracefully terminates after encountering errors
- Generally, production-grade orchestrations tend to be very complex and large in size, which will consequently affect its readability and maintainability
Second Approach – Throttling Pipeline Component
In order to avoid the above-mentioned caveats of using an aggregator orchestration, instead, you can leverage a pipeline component at the back-end system’s send port that will introduce the necessary latency, right before sending away the message to the designated service. This way you can achieve the required throughput outcome for a given back-end system.
The induced latency could be implemented using the Thread.Sleep() method, or as an infinite While loop that breaks after the required delay period has elapsed. I tried them both, with similar results, although I would personally be very much hesitant to use a while(true) loop in production.
The pipeline component approach is what I actually used for my final solution, as it has the flexibility and control I needed, without any additional latency, affecting the throughput outcome, coming from platform overheads that is beyond my control. After all, it’s my code and it can be optimized as much as possible.

Throttling Pipeline Component Send Port Settings
Another important part of this approach is to apply the following configurations that will disable concurrent processing of messages for the throttled send ports. This way, messages are processed sequentially, one message at a time, under the full control of your throttling pipeline component. This requirement could be achieved by configuring the throttled send ports.
- Retry must be disabled on the throttled send ports
- Ordered Delivery must be enabled on the throttled send ports
- Cluster Hosts for the throttled send ports in a highly available BizTalk solution

BizTalk Throttling General Tips
1. Efficient Throttling solutions should minimize or completely avoid message box hops. It should be applied at the edges of the solution. This is because message box hops itself will cause additional latency, which will impact the reached throughput outcome. In fact, the optimum position for the throttling component is at send port edge, right before sending the message to the back-end system. It could also be applied in receive end, but again, you will be at the mercy of the message box hops latency and performance.
 2. Applying the throttling component directly on a back-end system (2-way) send port will include the service response time as an additional overhead in-between the throttled requests. This will slow down the message frequency and impact the reached throughput outcome. Check the below diagram, where a back-end system takes (10) seconds to process a single request, because of the enforced ordered delivery of messages. Message (2) request will not be processed by the send port until Message (1) response is returned back by the system.
2. Applying the throttling component directly on a back-end system (2-way) send port will include the service response time as an additional overhead in-between the throttled requests. This will slow down the message frequency and impact the reached throughput outcome. Check the below diagram, where a back-end system takes (10) seconds to process a single request, because of the enforced ordered delivery of messages. Message (2) request will not be processed by the send port until Message (1) response is returned back by the system.
 3. As mentioned earlier in the requirements section, the solution had to be efficient, that is, it needed to leverage the maximum allowed throughput limits by the back-end systems, without any additional latency. Therefore, I had to go against my first tip for avoiding message box hops, as I had to apply the throttling component and port settings on another send port with a loop-back adapter, right before eventually routing the message to the actual back-end service send port.
3. As mentioned earlier in the requirements section, the solution had to be efficient, that is, it needed to leverage the maximum allowed throughput limits by the back-end systems, without any additional latency. Therefore, I had to go against my first tip for avoiding message box hops, as I had to apply the throttling component and port settings on another send port with a loop-back adapter, right before eventually routing the message to the actual back-end service send port.

4. It is very important that you make sure that the BizTalk built-in throttling does not kick-in and impact the overall solution throughout. Interestingly, this will initially slow down your system, and after the root cause has been alleviated and the built-in throttling subsides, some of the remaining messages could bombard the back-end systems at higher rates. The root cause for BizTalk throttling will be different for each solution, so you will need to conduct a comprehensive end-to-end load testing under realistic loads to identify and fine-tune BizTalk throttling thresholds in the BizTalk Host settings.
5. Following the previous tip, load testing will also allow you to find & fix the weak points in your BizTalk artifacts, for instance, it could be an unoptimized code snippet in a pipeline component, or in a map. In my case it was the performance of the loop back adapter I used, which I had to replace.
6. HTTP performance optimization in BizTalk Host configuration settings (BTSNTSvc.exe.config), will only control the maximum concurrent connections for HTTP-based adapters. However, it will not work for achieving specific throughput. That is, the number of requests allowed per time unit. Don’t forget the “per time unit” part. In other words, (5) requests per (1) minute, is not the same as, (5) requests per (1) second, is not the same as, (5) concurrent requests, within any given time window.
Lessons Learned
- BizTalk built-in throttling is a cleverly designed feature that is used to protect the platform from being overwhelmed under large loads. However, it is not designed to achieve exact throughput values
- Achieving controlled, accurate throttling is extremely challenging, especially when the latency is required to be at a minimum, it will also require intensive testing and fine tuning that might vary for each solution
- The throttling solution will introduce an inevitable latency to the solution, which could be minimized to negligible values. If you leverage the pipeline component approach with an optimized code, and conducted the necessary fine-tuning for BizTalk Server, the overhead for each request can be as low as 5 -10 milliseconds
- For guaranteed upper limit throughput only, you could apply the throttling component directly on the back-end system’s send port. This will completely avoid the extra message box hop, and you will not need the loop-back send port to apply the throttling, like I did.
Final Thoughts
The proliferation of API management
Nowadays, there is an awareness of API management tools. More and more organizations are leveraging API management to shield their back-end systems from huge loads, to apply the organization’s internal policies or to gain financial value from their data assets – API economy.

If the BizTalk published services and its underlying operations are as granular as the back-end ones, you could alternatively use an API management platform, in front of BizTalk, to apply the required throttling.
Are we bending the platform?
Is this controlled throttling implementation bending the platform into doing something that it is not supposed to be doing? – To answer this question, we need to have a closer look into the BizTalk platform design.
On the one hand, precise throttling is simply not baked into the platform, this is what most BizTalk experts and the Microsoft Product Group will acknowledge, which is true!
On the other hand, it is important not to forget that the BizTalk message box is an implementation of a Message Queue, supporting the store and forward messaging pattern.

Moreover, the send port service window feature incarnates message delayed delivery capability, by keeping the messages queued in the message box until the predefined time window is reached, before delivering the message.
 If you have an even closer look into the message box database, specifically into the BizTalk host queue table, you will see that our Throttled Send Ports are simply work-in-progress messages and they are treated the same way as the scheduled messages using the built-in service window feature, albeit the start Window time is set the past; so far so good!
If you have an even closer look into the message box database, specifically into the BizTalk host queue table, you will see that our Throttled Send Ports are simply work-in-progress messages and they are treated the same way as the scheduled messages using the built-in service window feature, albeit the start Window time is set the past; so far so good!
 Moreover, the difference between the service window scheduling in the receive location and the send port shows another important hint. As seen below, unlike the receive location with its advanced scheduling options, the scheduling option for the send port only supports a time window range within a single day.
Moreover, the difference between the service window scheduling in the receive location and the send port shows another important hint. As seen below, unlike the receive location with its advanced scheduling options, the scheduling option for the send port only supports a time window range within a single day.
 This intended limitation in the user interface hints that scheduled messages are not designed to stay in BizTalk message box for longer periods of time, in order not to overwhelm the message box.
This intended limitation in the user interface hints that scheduled messages are not designed to stay in BizTalk message box for longer periods of time, in order not to overwhelm the message box.
This perfectly resonates with how Dan Rosanova eloquently described Message box work-in-progress items: “This aspect of BizTalk is critical, as it is not designed to hold too much information for too long, but to pass the information on and move it out of the message box.” – Dan Rosanova – Microsoft BizTalk Server 2010 Patterns, Packt Publishing (October 28, 2011).
Consequently, if the back-end systems throughput limits will be high enough, to the point where it won’t let work-in-progress messages stay put in the message box for longer periods of time, then you will be achieving controlled throttling within the platform design boundaries.
Finally, controlled throttling in BizTalk Server should not be taken lightly., If you take into consideration all the previous guidelines, caveats, and conduct proper testing, you can achieve controlled throttling in BizTalk Server with confidence, and most importantly, without bending the platform.
Author: Ahmed Taha
Technical Architect with 10 years of hands-on experience in Microsoft Stack; .Net windows applications, web applications, BizTalk Server, SharePoint, SQL Server, SSIS, SSRS, and Integration with Azure Service Bus, and Logic Apps. BizTalk Server SME, conducting Integration POCs and demos for customers, provide consultancy and support for existing Integration projects in the Gulf, and Africa regions. View all posts by Ahmed Taha
by Sandro Pereira | Oct 17, 2018 | BizTalk Community Blogs via Syndication
Happy to announce that today I decided to publish another release on my Mapper Extensions UtilityPack project. This time I decided to release 2 new BizTalk Database Functoids:
- Adv Database Lookup Functoid: Use the Adv Database Lookup functoid to extract information from a database and store it as a Microsoft ActiveX Data Objects (ADO) recordset. This functoid requires the following 3 inputs: a database connection string, table name and a WHERE clause.
- Adv Value Extractor: Use the Adv Value Extrator functoid to extract the appropriate column value from a recordset returned by the Adv Database Lookup functoid. This functoid requires two inputs parameters: a link to the Database Lookup functoid and a column name.
Basically, they have the same functionality as the default Database Lookup Functoid and Value Extractor Functoid but they have a slightly different implementation.
Unlike the default Database Lookup Functoid that have 4 input parameters
- A lookup value
- A database connection string
- A table name
- A column name for the lookup value.
The limitation of this Functoid is that you cannot have multiple conditions, like WHERE SalesPersonID = “A” and System = “B” because of the nature of how this functoid was created
The Adv Database Lookup Functoid have the goal to suppress this limitation, it will allow 3 inputs:
- A database connection string
- A table name
- A WHERE clause.
In the where condition you will be able to set all the conditions you want, including a combination of AND’s and OR’s.
The Adv Value Extractor Functoid has the exact same functionality that the default Value Extractor Functoid but prepared and optimized to work with the Adv Database Lookup Functoid.
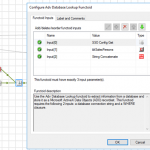
Adv Database Lookup Functoid
Use the Adv Database Lookup functoid to extract information from a database and store it as a Microsoft ActiveX Data Objects (ADO) recordset.
Parameters
The functoid takes three mandatory input parameters:
- Parameter 1: An ActiveX Data Objects .NET (ADO.NET) connection string for a compliant data source in which to search. ODBC data sources (including DSN sources) are not supported.
- Provider=SQLOLEDB.1;Integrated Security=SSPI;Persist Security Info=False;Initial Catalog=DatabaseName;Data Source=SQLServerName
- Parameter 2: The name of the table in the database in which to search;
- Parameter 3: WHERE clause (without the WHERE)
- SourceSystemID like ‘A’ AND SSSalesPersonID = 1
The output of the functoid will be an ADO recordset.

Adv Value Extractor Functoid
Use the Adv Value Extrator functoid to extract the appropriate column value from a recordset returned by the Adv Database Lookup functoid. This functoid requires two inputs parameters: a link to the Database Lookup functoid and a column name.
Parameters
The functoid takes two mandatory input parameters:
- Parameter 1: An ADO recordset, which is the output of the Database Lookup functoid. This recordset never contains more than one database row.
- Parameter 2: The name of a column from which to extract a value for output.
The output of the functoid will be the value of that column on the database table.

BizTalk Mapper Extensions UtilityPack: Project Description
BizTalk Mapper Extensions UtilityPack is a set of libraries with several useful functoids to include and use it in a map, which will provide an extension of BizTalk Mapper capabilities.
Where to download?
You can download this functoid along with all the existing one on the BizTalk Mapper Extensions UtilityPack here:
BizTalk Mapper Extensions UtilityPack
GitHub
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc. He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community. View all posts by Sandro Pereira
by Rochelle Saldanha | Oct 16, 2018 | BizTalk Community Blogs via Syndication
Notifications are an established concept for alerting users. By default, a number of external notification channels are inbuilt into BizTalk360. The only step you need to do, is to configure these notification channels with the appropriate URL, Access Token value (for Slack) and Authentication settings (for ServiceNow and WebHook), and Teams WebHook Connector (for Microsoft Teams). What this means for you, is that if you are already using either of these channels in your organization, it becomes easier to receive alerts from BizTalk360 right into these channels.
Since previous versions of BizTalk360, the notifications from BizTalk360 can be sent through various channels like:
Besides the above mentioned channels, BizTalk360 also provides an easy to use API, to enable you to create notification channels for connecting to your own systems. Read more about creating your own custom notification channels in our Documentation portal.
Now, integration with PowerShell allows you to execute a PowerShell script, each time an alarm is triggered when the threshold is crossed.
This was one of the features most requested by customers, as a nice to have requirement, as it would enable them to perform some tasks via a PowerShell script, each time the alarm was triggered.
Steps to implement the PowerShell Notification Channel
It only takes a few steps to use the PowerShell Notification Channel:
- Create the PowerShell script
- Configuring the PowerShell Notification Channel in BizTalk360
Both steps are explained below.
Create the PowerShell script
- Create the script in the PowerShell ISE or a plain text editor such as Notepad and save it with a .PS1 file extension (for example, myscript.ps1)
- Run the script by entering the full path to the script (c:/scripts/myscript.ps1), or if it’s in the current directory, prefix it with a period followed by a slash ( ./myscript.ps1 )
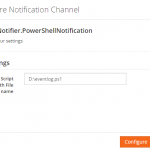
Configuring the PowerShell Notification Channel in BizTalk360
- You can find the Powershell Notification Channel under Settings > Monitoring and Notification > Manage Notification Channels. Select Notifier.PowerShellNotification
- Click “Configure” to open the configuration panel

During the configuration, provide the path along with the file name where the PowerShell script is present.
- In the Alarm section (Monitoring -> Manage Alarms), when you edit the alarm, enable the PowerShell notifications channel using the slider.
Note: Unless you wish to override the script provided in the settings page, there is no need to provide the path once again

Whenever a violation appears for the given alarm, this will trigger the notification channel and it will hit the PowerShell script.
Here, in the sample PowerShell script(Restart.ps1), we have included some basic code to restart the BizTalk360 Analytics service, but you can include more complex code to perform any actions via a Powershell script.
Customer Scenarios
- Use case 1: Automatically disable a receive location, such as when suspended instances hit a certain threshold
Consider the following setup – Microsoft CRM plugins, connected to a Receive Location are failing periodically. When they are down, the customer gets flooded with suspended instances. To prevent this from happening, the user wants to Disable the Receive Location.
This is how we can implement this using BizTalk360.
- Configure the PowerShell notification Channel
- First, create a Threshold alarm and setup the notification channel to be PowerShell, providing the script name if you wish to override the default Powershell script provided
- Then, in Manage Mapping, select the alarm and the artifact – Suspended Instances and put our threshold which causes the alarm to trigger

Now when the alarm triggers, along with the default email notification, the PowerShell script which disables the receive location mentioned in the script, will be run. Any errors will be logged in the PowerShell notification channel log (External.log).
- Use case 2: Stopping Host Instances, in case of too many running instances
A customer uses Data Monitoring for monitoring running instances of a particular orchestration in BizTalk. Sometimes it occurs that the application generates more messages than the downstream system can handle. To prevent damage, the Host Instances which serve the BizTalk application, need to be stopped to be able to identify the root cause.
The PowerShell notification channel not just works with Threshold alarms, but also based on Data Monitors. In above scenario, a Message Box Data Monitor has been setup, but you could also trigger PowerShell scripts based on the other categories of Data Monitoring. This could make the PowerShell notification channel to a strong extension of your tool set.
- Use case 3: We could fire a PowerShell script to restart IIS
We can implement these scenarios using BizTalk360 using similar steps as scenario1 but now the Alarm will be a Threshold alarm, not on Application artifacts but in BizTalk Environment -> Web Endpoint Monitoring.
Like scenario1 the alarm will have PowerShell notification enabled and when the Web end-point is triggered when the response is not fast enough, the Powershell script will run and restart the windows service (This should be programmed in the .ps1 file)
So, I hope these scenarios gave you a good idea of how the PowerShell notification channel can help you. This can also be considered as an action to be carried out if the alarms are triggered.
Author: Rochelle Saldanha
Rochelle Saldanha is currently working in the Customer Support & Client Relationship Teams at BizTalk360. She loves travelling and watching movies. View all posts by Rochelle Saldanha





