In our series of Guest Bloggers, we are pleased to announce Ahmed Taha, from LinkDev, Egypt! Ahmed is not new to the community as he has already hosted some Integration Monday sessions and loves to visit real-world events as well. We thought that his last Integration Monday session would make a good read, so he converted that session to this blog post. You can view this Integration Monday session from the Integration user Group web site. A warm welcome to Ahmed!
Introduction
A few years ago, I had an extremely challenging requirement in a BizTalk project that was integrating the customer’s system with several web services from disparate external backend systems. These systems had different communication protocols, message formats, and throughput limits.
The latter requirement was extremely challenging to implement, and it is actually not a very common one. However, it is worth noting that lately, I have been seeing this requirement, stated more often in new customers’ request for proposal (RFP) documents.
Landscape
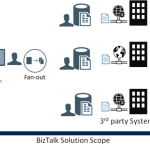
First, let me paint a complete picture for you, with the overall landscape.

As a first stage, the flow starts with an upstream system that has multiple input channels for entering and storing user entities into a staging data store.
In the second stage, the integration scope starts by polling user entity batches from the staging data store. Next, a fan-out approach is conducted, to scatter each single user entity into multiple requests, one for each web service, from a wide range of external web services.
Afterwards, the response data from each web service is stored separately in a dedicated table entity inside the same database, in a fragmented manner.
At the third and final stage, a mission-critical downstream system is continuously analysing these fragmented data for all the users, to perform critical data processing needed for decision making, as well as provide near real-time reporting from the aggregation of the response data.
Customer Requirements
The following are some of the key generic requirements:
- The entire process will be performed continuously, governed by a set of pre-defined business rules that determines if already fetched data fragment is stale, and needs to be refreshed
- The upstream staging data store will usually contain a large volume of user entities, and the upstream system input is expected to be of high throughput
- There are also some business rules that govern the routing logic, to decide which external systems need to be invoked, based on selected user criteria
So far, these above-mentioned requirements could easily be implemented as a BizTalk messaging solution, along with Business Rules Engine (BRE) policies to apply the governing business rules. For a robust messaging solution, I would highly recommend that you leverage the powerful BRE pipeline framework. Check my article on BRE pipeline framework.
Now, here comes the more challenging set of requirements, and if you are like me, you would be excited for having a good challenge, every now and then:
- Each of these back-end web services allowed for a maximum throughput (i.e. transactions per minute) which must not be exceeded, subsequent requests beyond that limit will fail
- At the same time, the integration solution must not invoke the services at rates that are way below the defined throughput limit, to maintain the overall efficiency of the solution

- These throughput limits should be configurable and could be variable based on specified time ranges, days of the week, date ranges, or a combination from all these options. BRE DB-facts were used for this requirement, coupled with a web-based control panel for the configurable DB values. The DB prefixes shown below denotes the BRE DB-facts.
 To come up with the right solution, some research was necessary. During that research, few different approaches were tried:
To come up with the right solution, some research was necessary. During that research, few different approaches were tried:
- Throttling Aggregator Orchestration
- Throttling Pipeline Component
Both approaches are described below.
First Approach – Throttling Aggregator Orchestration
Using an orchestration might be the first thing to come to your mind, in order to control and throttle the incoming messages in a stateful manner using the orchestration canvas.
This is a straight-forward implementation of an aggregator orchestration, which will run as a singleton orchestration instance for each defined back-end system.
To implement the actual throttling effect, the orchestration will simply include a delay shape that introduces the required latency in-between the incoming requests, in order to achieve the required throughput for a given back-end system.
For instance, a back-end system with a throughput limit of (6) requests per minute, will require the delay shape to induce a (10) second delay before every request in its corresponding orchestration instance.

Let’s have a look at the overall message flow. It starts with a polling receive location, where a pipeline component applies the required business rules and enriches the message context with throttling-related & routing-related information, before scattering the polled request into multiple requests, one for each designated back-end service.
A singleton orchestration for each system will apply the required throttling. You will notice that the orchestration is leveraging BRE & DB-facts to get the DB configured throttling information for the given back-end system. Memory cache is used to enhance the performance by minimizing the overhead impact of the BRE DB-facts during the BRE policy call.
While the orchestration approach works well, there are some caveats you should be aware of:
- Orchestration Delay shape is not very accurate when it comes to high precision, small delay values
- Orchestration persistence points will add extra latency which, in turn, lower the overall throughput outcome even further than intended
- Zombie messages are an inevitable byproduct of aggregator orchestrations, this will happen if the orchestration is designed to terminate after an idle time, or gracefully terminates after encountering errors
- Generally, production-grade orchestrations tend to be very complex and large in size, which will consequently affect its readability and maintainability
Second Approach – Throttling Pipeline Component
In order to avoid the above-mentioned caveats of using an aggregator orchestration, instead, you can leverage a pipeline component at the back-end system’s send port that will introduce the necessary latency, right before sending away the message to the designated service. This way you can achieve the required throughput outcome for a given back-end system.
The induced latency could be implemented using the Thread.Sleep() method, or as an infinite While loop that breaks after the required delay period has elapsed. I tried them both, with similar results, although I would personally be very much hesitant to use a while(true) loop in production.
The pipeline component approach is what I actually used for my final solution, as it has the flexibility and control I needed, without any additional latency, affecting the throughput outcome, coming from platform overheads that is beyond my control. After all, it’s my code and it can be optimized as much as possible.

Throttling Pipeline Component Send Port Settings
Another important part of this approach is to apply the following configurations that will disable concurrent processing of messages for the throttled send ports. This way, messages are processed sequentially, one message at a time, under the full control of your throttling pipeline component. This requirement could be achieved by configuring the throttled send ports.
- Retry must be disabled on the throttled send ports
- Ordered Delivery must be enabled on the throttled send ports
- Cluster Hosts for the throttled send ports in a highly available BizTalk solution

BizTalk Throttling General Tips
1. Efficient Throttling solutions should minimize or completely avoid message box hops. It should be applied at the edges of the solution. This is because message box hops itself will cause additional latency, which will impact the reached throughput outcome. In fact, the optimum position for the throttling component is at send port edge, right before sending the message to the back-end system. It could also be applied in receive end, but again, you will be at the mercy of the message box hops latency and performance.
 2. Applying the throttling component directly on a back-end system (2-way) send port will include the service response time as an additional overhead in-between the throttled requests. This will slow down the message frequency and impact the reached throughput outcome. Check the below diagram, where a back-end system takes (10) seconds to process a single request, because of the enforced ordered delivery of messages. Message (2) request will not be processed by the send port until Message (1) response is returned back by the system.
2. Applying the throttling component directly on a back-end system (2-way) send port will include the service response time as an additional overhead in-between the throttled requests. This will slow down the message frequency and impact the reached throughput outcome. Check the below diagram, where a back-end system takes (10) seconds to process a single request, because of the enforced ordered delivery of messages. Message (2) request will not be processed by the send port until Message (1) response is returned back by the system.
 3. As mentioned earlier in the requirements section, the solution had to be efficient, that is, it needed to leverage the maximum allowed throughput limits by the back-end systems, without any additional latency. Therefore, I had to go against my first tip for avoiding message box hops, as I had to apply the throttling component and port settings on another send port with a loop-back adapter, right before eventually routing the message to the actual back-end service send port.
3. As mentioned earlier in the requirements section, the solution had to be efficient, that is, it needed to leverage the maximum allowed throughput limits by the back-end systems, without any additional latency. Therefore, I had to go against my first tip for avoiding message box hops, as I had to apply the throttling component and port settings on another send port with a loop-back adapter, right before eventually routing the message to the actual back-end service send port.

4. It is very important that you make sure that the BizTalk built-in throttling does not kick-in and impact the overall solution throughout. Interestingly, this will initially slow down your system, and after the root cause has been alleviated and the built-in throttling subsides, some of the remaining messages could bombard the back-end systems at higher rates. The root cause for BizTalk throttling will be different for each solution, so you will need to conduct a comprehensive end-to-end load testing under realistic loads to identify and fine-tune BizTalk throttling thresholds in the BizTalk Host settings.
5. Following the previous tip, load testing will also allow you to find & fix the weak points in your BizTalk artifacts, for instance, it could be an unoptimized code snippet in a pipeline component, or in a map. In my case it was the performance of the loop back adapter I used, which I had to replace.
6. HTTP performance optimization in BizTalk Host configuration settings (BTSNTSvc.exe.config), will only control the maximum concurrent connections for HTTP-based adapters. However, it will not work for achieving specific throughput. That is, the number of requests allowed per time unit. Don’t forget the “per time unit” part. In other words, (5) requests per (1) minute, is not the same as, (5) requests per (1) second, is not the same as, (5) concurrent requests, within any given time window.
Lessons Learned
- BizTalk built-in throttling is a cleverly designed feature that is used to protect the platform from being overwhelmed under large loads. However, it is not designed to achieve exact throughput values
- Achieving controlled, accurate throttling is extremely challenging, especially when the latency is required to be at a minimum, it will also require intensive testing and fine tuning that might vary for each solution
- The throttling solution will introduce an inevitable latency to the solution, which could be minimized to negligible values. If you leverage the pipeline component approach with an optimized code, and conducted the necessary fine-tuning for BizTalk Server, the overhead for each request can be as low as 5 -10 milliseconds
- For guaranteed upper limit throughput only, you could apply the throttling component directly on the back-end system’s send port. This will completely avoid the extra message box hop, and you will not need the loop-back send port to apply the throttling, like I did.
Final Thoughts
The proliferation of API management
Nowadays, there is an awareness of API management tools. More and more organizations are leveraging API management to shield their back-end systems from huge loads, to apply the organization’s internal policies or to gain financial value from their data assets – API economy.

If the BizTalk published services and its underlying operations are as granular as the back-end ones, you could alternatively use an API management platform, in front of BizTalk, to apply the required throttling.
Are we bending the platform?
Is this controlled throttling implementation bending the platform into doing something that it is not supposed to be doing? – To answer this question, we need to have a closer look into the BizTalk platform design.
On the one hand, precise throttling is simply not baked into the platform, this is what most BizTalk experts and the Microsoft Product Group will acknowledge, which is true!
On the other hand, it is important not to forget that the BizTalk message box is an implementation of a Message Queue, supporting the store and forward messaging pattern.

Moreover, the send port service window feature incarnates message delayed delivery capability, by keeping the messages queued in the message box until the predefined time window is reached, before delivering the message.
 If you have an even closer look into the message box database, specifically into the BizTalk host queue table, you will see that our Throttled Send Ports are simply work-in-progress messages and they are treated the same way as the scheduled messages using the built-in service window feature, albeit the start Window time is set the past; so far so good!
If you have an even closer look into the message box database, specifically into the BizTalk host queue table, you will see that our Throttled Send Ports are simply work-in-progress messages and they are treated the same way as the scheduled messages using the built-in service window feature, albeit the start Window time is set the past; so far so good!
 Moreover, the difference between the service window scheduling in the receive location and the send port shows another important hint. As seen below, unlike the receive location with its advanced scheduling options, the scheduling option for the send port only supports a time window range within a single day.
Moreover, the difference between the service window scheduling in the receive location and the send port shows another important hint. As seen below, unlike the receive location with its advanced scheduling options, the scheduling option for the send port only supports a time window range within a single day.
 This intended limitation in the user interface hints that scheduled messages are not designed to stay in BizTalk message box for longer periods of time, in order not to overwhelm the message box.
This intended limitation in the user interface hints that scheduled messages are not designed to stay in BizTalk message box for longer periods of time, in order not to overwhelm the message box.
This perfectly resonates with how Dan Rosanova eloquently described Message box work-in-progress items: “This aspect of BizTalk is critical, as it is not designed to hold too much information for too long, but to pass the information on and move it out of the message box.” – Dan Rosanova – Microsoft BizTalk Server 2010 Patterns, Packt Publishing (October 28, 2011).
Consequently, if the back-end systems throughput limits will be high enough, to the point where it won’t let work-in-progress messages stay put in the message box for longer periods of time, then you will be achieving controlled throttling within the platform design boundaries.
Finally, controlled throttling in BizTalk Server should not be taken lightly., If you take into consideration all the previous guidelines, caveats, and conduct proper testing, you can achieve controlled throttling in BizTalk Server with confidence, and most importantly, without bending the platform.