by community-syndication | Oct 31, 2006 | BizTalk Community Blogs via Syndication
Despite its flaws and bugs, Visual Source Safe continues to be the most popular source control program in the Microsoft realm. Many poeple I talk to are not aware some of its more useful functions such as “Pinning”. Understanding the use of pinning can be very useful in a multi-developer environment……(read more)
by community-syndication | Oct 31, 2006 | BizTalk Community Blogs via Syndication
When declaring complex types in XML schema definition, I have grown accustomed to suffix the type name with “_Type”. This allows me to easily distinguish a complex type from a global type when viewing the definition in a graphical design tool such as XML Spy. However, it has unintended consequences when incorporating such schema into a web service.
When using Microsoft’s Web Service proxy class generator (wsdl.exe) , the generator uses the type name for the names of the classes it generates. Which means you’ll end up with something like this:
WS.Employee_Type employee = new WS.Employee_Type();
Not as readable as this:
WS.Employee employee = new WS.Employee();
Also, avoid using the “any” type, as it produces a blank class. If you cannot avoid it, you must hand tweak the generated class to use a string type instead.

by community-syndication | Oct 31, 2006 | BizTalk Community Blogs via Syndication
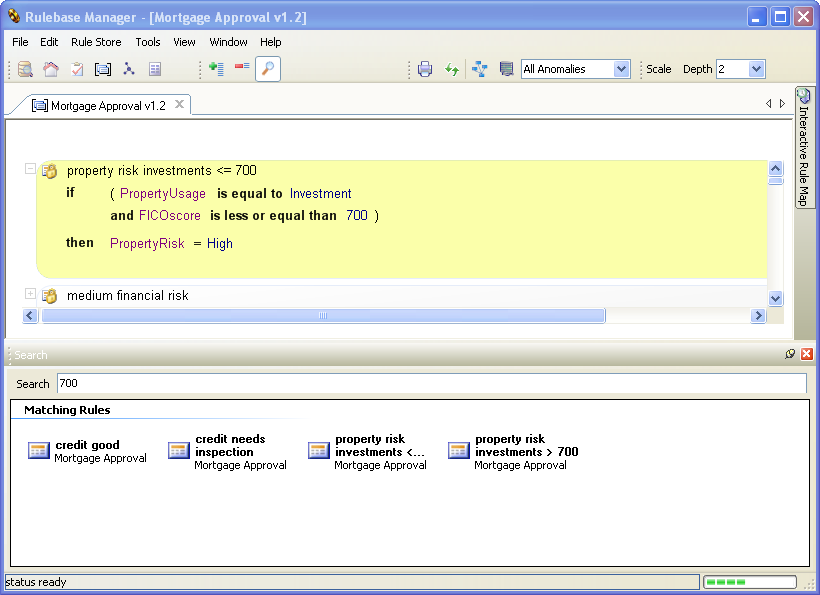
Acumen Business has just released the beta version of the new Policy Verificator that supports BizTalk 2006.
Major enhancements are made in the Interactive Rule Map (rule spider). There is a new free text search. And of course all the previous functions of Printing BizTalk Rules and Merging Vocabularies are available.

by community-syndication | Oct 31, 2006 | BizTalk Community Blogs via Syndication
A few months ago I
wrote about an issue with writing fully streaming custom decoding components for
BizTalk pipelines, which originated in limitations imposed by the disassembler components
(the XmlDisassembler component in particular) on the streams it received from the
decoding stage.
While doing some further work on custom decoding component I ran into what seems another
reason why you’ll need to do in memory buffering in some scenarios:
I think that for most purposes, all the components care about is that the position
of the stream can be queried; however, because of the mixed COM/.NET nature of the
BizTalk Messaging engine and some of the existing components, custom streams need
to be “partially” seekable. This is not so much because they are going to actually
try to move the position of the stream, but because they use the Seek() method of
the stream to discover the current position of it (instead of using the Position property)
as described here.
It does appear, unfortunately, that the disassembler will also require that your custom
stream class is able to determine the stream length; that is, that the Length property
is implemented and returns the correct value. If you don’t implement it, then an error
will be thrown during the disassembling. Furthermore, it appears that at some point
during the disassembling process something like this is tried:
int length = (int)stream.Length;
byte[] buffer = new byte[length];
stream.Read(buffer, 0, length);
Something that hints at this is that if you just return 0 from your Length implementation,
the disassembler tries to read 0 bytes from your stream (though I haven’t verified
this 100%, it might be something to watch out for).Anyway, just wanted to mention
that it appears it is important that your custom streams returned from your decoding
components are able to accurately return the stream length as it appears to the disassembler.
This can be hard in some scenarios without fully buffering the message in cases where
the length of the decoded data is different from the encoded data, because the component
cannot predict the resulting length before actually processing the entire stream.
by community-syndication | Oct 31, 2006 | BizTalk Community Blogs via Syndication
Acumen Business released the Policy Verificator version 1.1. An all new UI is designed what should significantly increase the usability issues from the initial release. Specially of interest is the inclusion of Datetime support for rule verification as well as support for the standard Microsoft Biztalk functions and predicates.
by community-syndication | Oct 31, 2006 | BizTalk Community Blogs via Syndication
I started of with log4j in my Java days, and was quick with adopting another fine .NET port: log4net.
But for work, we had to consider Microsofts Enterprise Instrumentation Framework (EIF). But a little more reading revealed that this package is getting replaced with the newly designed Enterprise Library. This framework not only contains Logging, but also a design pattern for Configuration, Data Access, Exception handling, Security, etc.
The Enterprise Library is all looking pretty o.k. but it seemed to be overly designed, over complicated and getting pretty slow. Also on migrating from one Microsoft packages to another: there is no migration path. And no support is mentioned for the future. Seems like this is going for a Corba-death: Beautifully designed, complicated to use, and slow.
For a comparison overview see Daniel Cazzulino’s EIF vs log4net feature comparison char
I always like fast and simple. So that takes me back to log4net. The only concern I have with log4net is that the latest view builds on Sourceforge all refer to beta releases that seems to be quite dated. But till so far I never had any issues with this latest beta release.
Scott Colestock also has been writing how log4net can be integrated with Biztalk 2004. So what else are we waiting for. Let me put in my 2 cents for some documentation on the conversionPattern:
The conversionPattern format
The conversion pattern is closely related to the conversion pattern of the printf function in C. A conversion pattern is composed of literal text and format control expressions called conversion specifiers.
You are free to insert any literal text within the conversion pattern.
Each conversion specifier starts with a percent sign (%) and is followed by optional format modifiers and a conversion character. The conversion character specifies the type of data, e.g. category, priority, date, thread name. The format modifiers control such things as field width, padding, left and right justification. The following is a simple example.
<appender name="FileAppender" type="log4net.Appender.FileAppender">
<file value="c:\\log\\My.log">
<appendtofile value="true">
<layout type="log4net.Layout.PatternLayout">
<conversionpattern value="%-5p [%t]: %m%n"/>
</layout>
</appender>
Then the statements
private static readonly log4net.ILog log = log4net.LogManager.GetLogger(typeof(MyType));
log.Debug("Message 1");
would yield the output
DEBUG [MyType]: Message 1
Note that there is no explicit separator between text and conversion specifiers. The pattern parser knows when it has reached the end of a conversion specifier when it reads a conversion character. In the example above the conversion specifier %-5p means the priority of the logging event should be left justified to a width of five characters. The recognized conversion characters are
| Conversion Character |
Effect |
| c |
Used to output the category of the logging event. The category conversion specifier can be optionally followed by precision specifier, that is a decimal constant in brackets.
If a precision specifier is given, then only the corresponding number of right most components of the category name will be printed. By default the category name is printed in full.
For example, for the category name “a.b.c” the pattern %c{2} will output “b.c”.
|
| C |
Used to output the fully qualified class name of the caller issuing the logging request. This conversion specifier can be optionally followed by precision specifier, that is a decimal constant in brackets.
If a precision specifier is given, then only the corresponding number of right most components of the class name will be printed. By default the class name is output in fully qualified form.
For example, for the class name “org.apache.xyz.SomeClass”, the pattern %C{1} will output “SomeClass”.
WARNING Generating the caller class information is slow. Thus, it’s use should be avoided unless execution speed is not an issue.
|
| d |
Used to output the date of the logging event. The date conversion specifier may be followed by a date format specifier enclosed between braces. For example, %d{HH:mm:ss,SSS} or %d{dd MMM yyyy HH:mm:ss,SSS}. If no date format specifier is given then ISO8601 format is assumed.
The date format specifier admits the same syntax as the time pattern string of the SimpleDateFormat. Although part of the standard JDK, the performance of SimpleDateFormat is quite poor.
For better results it is recommended to use the log4j date formatters. These can be specified using one of the strings “ABSOLUTE”, “DATE” and “ISO8601” for specifying AbsoluteTimeDateFormat, DateTimeDateFormat and respectively ISO8601DateFormat. For example, %d{ISO8601} or %d{ABSOLUTE}.
These dedicated date formatters perform significantly better than SimpleDateFormat.
|
| F |
Used to output the file name where the logging request was issued.
WARNING Generating caller location information is extremely slow. It’s use should be avoided unless execution speed is not an issue.
|
| l |
Used to output location information of the caller which generated the logging event.
The location information depends on the JVM implementation but usually consists of the fully qualified name of the calling method followed by the callers source the file name and line number between parentheses.
The location information can be very useful. However, it’s generation is extremely slow. It’s use should be avoided unless execution speed is not an issue.
|
| L |
Used to output the line number from where the logging request was issued.
WARNING Generating caller location information is extremely slow. It’s use should be avoided unless execution speed is not an issue.
|
| m |
Used to output the application supplied message associated with the logging event. |
| M |
Used to output the method name where the logging request was issued.
WARNING Generating caller location information is extremely slow. It’s use should be avoided unless execution speed is not an issue.
|
| n |
Outputs the platform dependent line separator character or characters.
This conversion character offers practically the same performance as using non-portable line separator strings such as “\n”, or “\r\n”. Thus, it is the preferred way of specifying a line separator.
|
| p |
Used to output the priority of the logging event. |
| r |
Used to output the number of milliseconds elapsed since the start of the application until the creation of the logging event. |
| t |
Used to output the name of the thread that generated the logging event. |
| x |
Used to output the NDC (nested diagnostic context) associated with the thread that generated the logging event. |
| X |
Used to output the MDC (mapped diagnostic context) associated with the thread that generated the logging event. The X conversion character must be followed by the key for the map placed between braces, as in %X{clientNumber} where clientNumber is the key. The value in the MDC corresponding to the key will be output.
|
| % |
The sequence %% outputs a single percent sign. |
By default the relevant information is output as is. However, with the aid of format modifiers it is possible to change the minimum field width, the maximum field width and justification.
The optional format modifier is placed between the percent sign and the conversion character.
The first optional format modifier is the left justification flag which is just the minus (-) character. Then comes the optional minimum field width modifier. This is a decimal constant that represents the minimum number of characters to output. If the data item requires fewer characters, it is padded on either the left or the right until the minimum width is reached. The default is to pad on the left (right justify) but you can specify right padding with the left justification flag. The padding character is space. If the data item is larger than the minimum field width, the field is expanded to accommodate the data. The value is never truncated.
This behavior can be changed using the maximum field width modifier which is designated by a period followed by a decimal constant. If the data item is longer than the maximum field, then the extra characters are removed from the beginning of the data item and not from the end. For example, it the maximum field width is eight and the data item is ten characters long, then the first two characters of the data item are dropped. This behavior deviates from the printf function in C where truncation is done from the end.
Below are various format modifier examples for the category conversion specifier.
| Format modifier |
left justify |
minimum width |
maximum width |
comment |
| %20c |
false |
20 |
none |
Left pad with spaces if the category name is less than 20 characters long. |
| %-20c |
true |
20 |
none |
Right pad with spaces if the category name is less than 20 characters long. |
| %.30c |
NA |
none |
30 |
Truncate from the beginning if the category name is longer than 30 characters. |
| %20.30c |
false |
20 |
30 |
Left pad with spaces if the category name is shorter than 20 characters. However, if category name is longer than 30 characters, then truncate from the beginning. |
| %-20.30c |
true |
20 |
30 |
Right pad with spaces if the category name is shorter than 20 characters. However, if category name is longer than 30 characters, then truncate from the beginning. |
Below are some examples of conversion patterns.
- %r [%t] %-5p %c %x – %m\n
- This is essentially the TTCC layout.
- %-6r [%15.15t] %-5p %30.30c %x – %m\n
- Similar to the TTCC layout except that the relative time is right padded if less than 6 digits, thread name is right padded if less than 15 characters and truncated if longer and the category name is left padded if shorter than 30 characters and truncated if longer.
References:
by community-syndication | Oct 31, 2006 | BizTalk Community Blogs via Syndication
The book (by Scott Woodgate, Stephen Mohr, Brian Loesgen ISBN 0-672-32598-5) seems to be getting into it’s final stage. There was a page advertisement in the MSDN magazine of November 2004 (Vol 19 NO 11 Page 108) offering a 30% discount for ordering the book from SamsPublishing.com (plus free shipping).
On Sams website I could not find any link or discount coupon. I opened an issue with Customer Service and they are contacting the Sams Marketing to inquire how we can get the 30% discount.
Update (18 Oct 2004):
I received an email from the Sams Marketing with the following information: In order to get the 30% discount you have to use the coupon code BIZTALK (note it must be all caps!). You enter the coupon code on the ‘Payment Method’ page in the order process. A review of the discount will be shown on the ‘Place Order’ page. The offer is valid till the Dec 15.
In a couple of days Sams website will provide a direct link.
by community-syndication | Oct 31, 2006 | BizTalk Community Blogs via Syndication
The BizTalk Vocabulary Upgrader has gone into beta.
The Vocabulary Upgrader enables to replace multiple references to different versions of a vocabulary to a single vocabulary version.
Have a look at the documentation, screenshots, getting started guide.
The tool is submitted to the Microsoft BizTalk Developers competition.
by community-syndication | Oct 31, 2006 | BizTalk Community Blogs via Syndication
Scott Woodgate published the list of Biztalk Competition Winners. The vocabulary upgrader got mentioned at point F!
The Vocabulary Upgrader is also available at Acumen Business. Also available on this site is the automatic Business Rule Verification;
the Policy Verificator.
by community-syndication | Oct 31, 2006 | BizTalk Community Blogs via Syndication
Log4net development is showing signs of life! After a long period of silence the 1.2.9 Beta has been released. Some highlights of the list of new features:
- New logging contexts
- GlobalContext
- ThreadContext
- LogicalThreadContext
- LoggingEvent
- .NET string formatting syntax
- Customizable levels
- RollingFileAppender roll once
- SmtpAppender authentication
- … and more