
by Richard | Aug 11, 2009 | BizTalk Community Blogs via Syndication
Update 2012-03-28
When looking into BizTalk monitoring and overall governance tools for BizTalk, don’t miss BizTalk360. BizTalk 360 wasn’t available when this post was written and has some really compelling features.
Update 2010-09-30: BizMon is now owned and developed by Communicate Norway. They have renamed, and further developed the product, to IPM (Integration Monitoring Platform) – check it out here.
I’ll start this post by clarifying two important things
-
I am involved in the development and marketing of “BizMon”. Therefore I am biased and you have to decide for yourself if that affects the content of the post. As always it is best to try it for yourself and see if it is useful for you.
-
I have talked about BizTalk monitoring tools in a previous post and my goal then was then to start a an open source project. That did not happened and you can read why in the update to that post.
Why “monitoring” for BizTalk?
I have worked as a BizTalk developer for many years but it was not until I really got in to maintaining a large integration solution that I realized that the tools I really needed was not there. I found myself using the following “tools” and techniques over and over again.
- Open the BizTalk Administration Console and query for suspended messages, running instances, routing errors etc, etc.
But as I had to pull for this information it took time and discipline (two things I’m short of) to quickly find out when errors occurred.
- I used the HAT to try and find out when the last messages was sent and received on the different applications. This gave me a “guarantee” that things worked as I accepted and that the solution had a “pulse” – messages at least moved back and forward.
The problem is that the HAT tool is bad and it is hard to find what one is looking for (It is a bit better in BizTalk 2009 but it is still tricky to get useful information out of it.)
- Some of the integrations in our environment used BAM to track messages and their state.
The problem was that all solutions was developed by either myself or different consultants. This made it hard to get everyone to use the same tracking. It was also hard to convince management to go back and try and “instrument” old working integrations with BAM tracking.
At the same time as we had the “tools” and techniques mentioned above available, management had the following requirements for us.
-
Start working on fixing an error within 10 minutes after it occurred 24/7 all 365 days …
-
Be able to delegate simple monitoring task to support personnel (a help desk).
-
Not have to actively “pull” for information but be quickly altered of errors and get the information “pushed” to us.
The idea was that this would would save time as people don’t have to look for errors when everything is working fine. Time that people can use for other tasks …
- Enable reporting so we can provide systems owners and other interested people with information on how much data has been sent received to the systems and parties they care about.
All the above lead up to the realization that we needed some sort of tool.
What are the existing options for BizTalk monitoring tooling?
At the time we started looking for options all we could find was System Center Operations Manager (SCOM). We looked at SCOM BizTalk Management Pack and decided that for us this was not the right solution. It was too big, too complicated and it would be to hard to get it to the what we wanted to do.
>
> The decision to not use SCOM I think was right for us. We wanted something leaner and more specialized. I am however **_not saying _**that it is the right decision for you.
>
>
>
> If you are successfully suing SCOM to monitor BizTalk I would love to [hear about it](mailto:[email protected])!
>
>
What we ended up with
We ended up building BizMon. It does what we need and our help desk can now basically monitor about 100 different BizTalk application themselves. At the same time they do all the other support task they have to do. When something happens (and it does …) they are the first to know. Some easy tasks they can solve themselves, otherwise they make sure to notify the users and quickly call the developer that knows more and can help them.
Support personnel can now also setup custom reports that users can subscribe to, all based on BAM that they now easily can interject tracking points in existing solutions – both new and old ones.
As I said. This worked out out good and helped us. If you think that it could work for you as well – give it a try.
I am also really interested to how you have solved similar requirements as we had with your own tool or other solutions.
What else is there?
Recently FRENDS released a beta version of their FRENDS Helium product that looks promising could potentially solve a lot of the same issues that BizMon does and that I have discussed in this post.
Check it out and let us know what you think.
by Richard | Jun 16, 2009 | BizTalk Community Blogs via Syndication
Traditional SOAP Web Services might feel kind of old as more and more people move over to WCF. But a lot of integration projects still relay heavily on old fashion SOAP Web Services.
Using BizTalk generated Web Services however has a few issues and one needs to add a few extra steps and procedures to make them effective and easy to work with. This post aims to collect, link and discuss all those issues and solutions.
1. Building and deploying
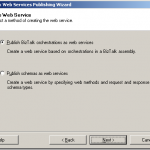
BizTalk Server includes the “BizTalk Web Services Publishing Wizard” tool that integrates with Visual Studio. This is basically a tool to generate a DSL based script for generating web services.
The wizard collects information about what schema or a orchestration to expose, namespaces, names of service and method, where on IIS to publish the service etc, etc.
The output of the tool is then a xml file (a “WebServiceDescription” file) that has all the collected values in it.
As a final step Visual Studio uses the newly created description file as input to a class called WebServiceBuilder in the .NET Framework. It is this class that is responsible for interpreting the description, configure and generate the service.
A common procedure is to use the wizard and click thru it and input values for every single deployment. This is of course slow, error prone and stupid.
What is much better is to take a copy of the generated “WebServiceDescription” file, save it to your source control system and then programmatically pass the file to the WebServiceBuilder class as part of your deployment process. Possible changes to the details of the service can then be done directly in the description file.
I have seen this approach save lots of time and problems related to deployment.
-
Paul Petrov has a great post on how to call the “WebServiceBuilder” class and pass the description file using C#.
http://geekswithblogs.net/paulp/archive/2006/05/22/79282.aspx
-
Michael Stephenson has a good post on how to used the “WebServiceBuilder” class via MSBuild.
http://geekswithblogs.net/michaelstephenson/archive/2006/09/16/91369.aspx
2. Fixing namespace
Another annoying problem (I’d would actually go so far as calling it a bug) is the problem with the bodyTypeAssemblyQualifiedName value in the generated Web Service class.
This causes BizTalk to skip looking up the actual message type for the incoming message. As no message type exists for the message is in BizTalk mapping and routing on message types etc will fail. It is a know problem and there are solutions to it. I would also recommend take the extra time need to make this small “post process step” be part of your deployment process (see how here).
3. Pre-compiling
By default the “WebServiceBuilder” class generates a web service without pre-compiling it. Usually this is not a problem. But in some cases were one really on the web service being online and give a quick response-message the performance problems in this approach can be a huge problem.
When generating the web service without pre-compiling it IIS has to compile the service and then keep the compiled service in memory. That means that when IIS releases the service from memory there is a latency before IIS re-compiled the service, loaded it into memory and executed it. This is a known problem and I have seen this “slow first hit” issue been a frequent question the different forums.
The solution is to use the aspnet_compiler.exe tool and pre-compile the service and the use those pre-compiled dlls as the service. IIS then never has to recompile it and will serve initial hits much faster.
Here is an example of how we defined a target to do this as part of our deployment process using MSBuild.
-
Pre-compile the service into a new folder
-
Clean out the “old” not compile service folder.
-
Copy the pre-complied service into the service folder
<Folder.CleanFolder Path="$(WebSiteServicePath)$(WebServiceName)"/>
<Folder.CopyFolder
Source="$(WebSiteServicePath)$(WebServiceName)Compiled"
Destination="$(WebSiteServicePath)$(WebServiceName)" />
-
Paul Petrov has two different articles here describing the process and also a different way that above on how to include the pre-compilation in you build process.
http://geekswithblogs.net/paulp/archive/2006/03/30/73900.aspx, http://geekswithblogs.net/paulp/archive/2006/04/19/75633.aspx
by Richard | May 28, 2009 | BizTalk Community Blogs via Syndication
There are integrations which only purpose is to move a file just as it is. No advanced routing. No orchestration processing. No transformation. Just a simple port-to-port messaging scenario.
It is however still a good idea to monitor these just as one would monitor a more complicated integration. We use BAM to monitor all our integrations and to measure how many messages that has been processed in a integration. Using BAM monitoring in a simple solution as the above however has its issues …
Setting up a simple test solution
-
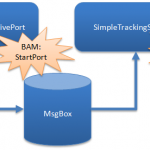
The solution will move a XML file between two port called “SimpleTrackingReceivePort” and “SimpleTrackingSendPort”.
-
Both port have PassThru pipelines configured.
-
The XML file does not have a installed schema. Remember we are just moving the file not actually doing anything with it.
-
A BAM tracking definition with one milestone called “StartPort” will be used. This will be mapped to the “PortStartTime” property on both the receiving and sending port .
Our tracking profile configuration will like below. Dead simple.
So – what’s the problem?
Let us drop a XML message looking some like this.
<?xml version="1.0" encoding="UTF-16"?>
<SimpleTest>
<SimpleContent Text="This is a test" />
</SimpleTest>
Remember that there is not a schema installed so we do not really have to worry about the structure of the file. It should just be “a file” to BizTalk and everything should be transferred between the ports. Even if we drop a executable or whatever – it should just be transferred. Nothing should read or examine the file as it’s just a pass thru!
As soon as BAM tracking is configured on a port that is however not the case. Lets take a look at the file we receive on the other end of our integration.
<SimpleTest>
<SimpleContent Text="This is a test" />
</SimpleTest>
BizTalk now removed our XML declaration! Basically it treated the message as a XML message and parsed the message as such while tracking it. It’ will also add the dreaded Byte-Order-Mark and fail any non-valid XML messages. The problem is that this is not the behavior what one expects and causes receiving systems that rely on the XML declaration to fail!
As we also don’t have a installed schema it is not possible to use a XMLTransmit pipeline to add the XML declaration and remove the BOM.
What to do?
If you’d like to track a XML based message using BAM make sure you have the schema installed … Even if you are just using PassThru.
Is it a bug or just something one should expect? In my opinion it is at least very annoying!
by Richard | Mar 19, 2009 | BizTalk Community Blogs via Syndication
I attended a session the other day at TechDays here in Sweden with Microsoft Escalation Engineer Niklas Engfelt. The session was about troubleshooting BizTalk and Niklas of course showed the wonderful MsgBoxViewer (MBV) tool by Jean-Pierre Auconie. If you haven’t tested and looked deeper into this tool you need to do so. It’s great!
I worked with the tool before but now I wanted to schedule the tool and to have MBV-reports e-mailed to relevant persons within the company on a weekly basis. This is quite easy to accomplish as MBV comes in two version. One GUI-based (shown below) version and one command-line based.
The command-line version is of course perfect for scheduling using the Windows Task Scheduler.
If you feel uncomfortable running all the queries (there is a lot of them) on a schedule you can pick some you find important and configure the tool to only run those. Jean-Pierre has a post on how to do just that here.
After MBV has completed all its queries and done its magic it will produce a html-report in the working folder (that’s the folder in the “Start in” field in the scheduled task example above).
We then use a tool called AutoMailer NT (cost €20 – there is a 30 days trial) to:
-
Poll the working folder for a *.html report file.
-
Compress the file (using zip).
-
Send the report to a configured list of recipients.
-
Delete the report file.
The AutoMailer NT installation is a bit rough (don’t miss to the ****separate download (!) of the trial certificate). But once you have everything working it’s great to have a fresh MBV report in you inbox every Monday telling you how your BizTalk environment is doing and possible issues to attend to.
by Richard | Feb 17, 2009 | BizTalk Community Blogs via Syndication
During my years of BizTalk development I’ve been warned of a couple of scenarios that the product wouldn’t handle very well. Yesterday another of those scenarios turned out to kind of false and, if done right, not really a problem at all.
The scenario I’m talking about is a batch import of data to SQL Server using the SQL adapter. In my case the data is received as a flat text file containing a large number of rows. These rows should the be places inside a database table as one table-row per row in the flat file.
The common way of dealing with batch incoming data like this is to split (aka disassemble) it in the receive port using the Flat File Disassembler pipeline component (for a good example – look here). Disassembling the data when receiving it is usually good practice to avoid running into OutOfMemoryException when dealing with big messages.
Sometimes the requirements also forces one into reading each row to a separate message to be able to route and handle each messages in a unique way depending of it’s content. If that so – this is a not a good post for you. In this post I’ll discuss the scenario were all the data just needs to go as fast as possible from the text file into a single database table. No orchestration or anything, just a simple batch import.
So, what’s The problem with the batch import scenario?
When I implemented similar batch import scenarios in the past I tried to practice good practice and split the data into separate files that I then filtered to the SQL adapter send port, one by one.
- The received flat file files has been split into thousands of small little message that one by one are sent to the SQL adapter send port.
- The SQL adapter then parses each message into a SQL script that executes a store procedure and the message is finally inserted to the target database.
“So what’s the problem?” you then ask? It’s slow! It’s very slow! Each message gets stored a couple of times in the BizTalk database and each message is sent inside it’s own DTC transaction against the target database. And all this adds up …
And after reading this this interview by Richard Seroter with Alan Smith I also felt I was the only one having the problem either …
There are quite a few people asking about using BizTalk for heavy database integration, taking flat files, inserting the data in databases and processing it. SQL Server Integration Services (SSIS) does a much better job than BizTalk at this, and is worth looking at in those scenarios. BizTalk still has its uses for that type of work, but is limited be performance. The worst case I saw was a client who had a daily batch that took 36 hours to process using BizTalk, and about 15 minutes using SSIS. On another project I worked on they had used BizTalk for all the message based integration, and SSIS for the data batching, and it worked really well.
>
>
Note: As I’ll described later in this post my import scenario went from something like 3-4 hours to 2 minutes (importing 10 MB). Alan talks about a 36 hours (!) import. I don’t know anything more about the scenario he mentions and it might not even be solved using the technique discussed below. Hopefully Alan might comment on the post and give us more details. 😉
How can we get better performing imports using BizTalk?
As the import scenario we described doesn’t involve any orchestration but is a pure messaging scenario and we do all the transformation on the ports we don’t really have to worry about OutOfMemoeyExceptions even though the message is quite big.
**Large message transformation.** In previous versions of BizTalk Server, mapping of documents always occurred in-memory. While in-memory mapping provides the best performance, it can quickly consume resources when large documents are mapped. In BizTalk Server 2006, large messages will be mapped by the new large message transformation engine, which buffers message data to the file system, keeping the memory consumption flat. ([Source](http://www.microsoft.com/technet/prodtechnol/biztalk/2006/evaluate/overview/default.mspx))
>
>
Another reason for splitting the message was for it to work with the SQL adapter. When setting up the SQL adapter to work with a store procedure the adapter expects a message that looks something like the below.
<ns0:ImportDataSP_Request xmlns:ns0="http://FastSqlServerBatchImport.Schemas.SQL_ImportDataSP">
<ImportData Name="Name 1" Value="1"></ImportData>
</ns0:ImportDataSP_Request>
This tells us that the store procedure called is “ImportData” with “Name 1” as the value for the “Name” parameter and “1” as the value for the parameter called “Value” in the stored procedure. So each little separate message would get mapped on the send port into something like this.
What I however didn’t know until I read this post was that the message I send to the SQL adapter port just as well could look like this!
<ns0:ImportDataSP_Request xmlns:ns0="http://FastSqlServerBatchImport.Schemas.SQL_ImportDataSP">
<!-- TWO rows!!! -->
<ImportData Name="Name 1" Value="1"></ImportData>
<ImportData Name="Name 2" Value="2"></ImportData>
</ns0:ImportDataSP_Request>
So basically we can have as many store procedure calls as we want in one single file that then can send to the SQL adapter send port!
Eureka!) __This means that we don’t have to split the incoming file! We can keep it as one big single file and just transform it to a huge file containing separate nodes that we send to the SQL Adapter send port! The SQL adapter will then parse this into separate store procedure calls for us.
__
Is it really any faster?
As the technique above drastically reduced the amount of database communication needed I knew it’d be much faster. Some initial testing shows that an import of a file containing somewhere around 55 000 rows (about 10 MB) into our article database went from 3-4 hours to under two minutes!
See for yourself!
In this sample solution I have a text file containing 2 600 rows. I’ve then created two separate projects in a solutions. One that splits the messages into separate messages (called “SlowImport”) and one that just transforms it and send it as one message to the send port (called “FastImport”). One takes 1:50 minutes and 2 seconds on my development machine … I won’t tell you which one is the faster one …
Test it for yourself and let me know what you think.

by Richard | Jan 6, 2009 | BizTalk Community Blogs via Syndication
>
> **Update 2010-09-30:** BizMon is now owned and developed by [Communicate Norway](http://www.communicate.no). They have renamed, and further developed the product, to IPM (Integration Monitoring Platform) – check it out [here](http://ipm.communicate.no/exciting-news).
>
>
>
> _**Update 2009-08-11: **This project turned out to be far more complicated and bigger than I first expected (ever heard that before?). Due to that and the fact that we wanted to have a company behind that could offer full-time support and stability “BizMon” has been released as a commercial product that you can find [here](http://bizmontool.com/). _
>
>
>
> _I love to get some [help from you](http://bizmontool.com/we-have-a-rtm-version)**** to test it and make it as good as possible. Even if it is commercial and cost money we have a free alternative for small environments and we work hard to keep the license price as low as possible._
>
>
****
>
> _**Update 2009-02-25:** In the original post I said I’d post more on the architecture and the code during February 09. I’m however current struggling getting the needed legal rights etc, etc to be able to talk further about the “BizMon”-solution. It was harder than I thought … I’ll get back to posing on the subject as soon as I have that sorted._
>
>
Integration of enterprise processes often ends up being very business critical. If a integration fails delivering the messages it was supposed to it usually means the business will be affected in a very negative way (for example losing money or delivering bad service). That of course means that monitoring the status of the integrations soon becomes very important (if you’re not into getting yelled at or potentially loosing your job).
Strangely enough **BizTalk Server 2006 R2 in my humble opinion doesn’t come with the right tool to efficiently monitoring big enterprise integration solutions!**
What do I mean by monitoring?
Before I get myself deeper into trouble I’d like to define what I mean by monitoring. I think monitoring a BizTalk integration solution could be divided into four categories.
-
Infrastructure (traditional)
This is the easy one and one that IT-pros and alike are used to monitor. Hardware status, network traffic, disk space, event logs etc all fall under this category. If the storing area for the databases start running low on memory we can be pretty sure it’ll eventually effect the integration somehow.
-
BizTalk infrastructure
This is where it starts getting a bit trickier. This category includes the status of receive locations, orchestrations, host instances and send ports. If a receive location is down no messages will be picked up (but we can also be sure of not getting any suspended messages).
-
Suspended messages
As most reader of this blog probably know suspended message is due to some sort of failure in BizTalk. It can be an actually exception in code or something that went wrong while trying to send messages. It’s however and important category to monitor.
-
Heartbeat (monitoring actual successful traffic)
While the points 1-3 above focuses on errors and that things being inactive this category actually monitors that the integration runs as expected.
To me this final point is almost the most important one. What I mean is that if everything runs as expected and we’re sending the expected amount of messages in the right pace everything else must be ok – right? It’s however the one that in my experience almost always overlooked!
“What do you mean ‘Not the right tools to monitor’? We have loads of tools in BizTalk 2006 R2!”
OK. So let’s see what tools we have available actually monitor the categories above.
-
Infrastructure (traditional)****
I won’t discuss this kind of monitoring in this post. There are loads of tools (all from the huge expensive enterprise ones to plenty of good open-source alternatives) for this and you’re probably already using one or several of them already.
-
BizTalk infrastructure
There are a couple of way of achieving this. One of the is to use the Microsoft BizTalk Server Management Pack for Operation Manager. It does however of course require that you have invested in System Center Operation Manager already …
Another way is to either use the ExplorerOM classes or connecting directly to the BizTalk configuration database and code your own report of some sort.
The final (and most common way in my experience) is to try and document the correct configuration and settings and then have someone check these manually (if you’re that person I feel for you …).
- Suspended messages
Suspended messages are of course very important to monitor and it’s for some reason also the first thing developers think of monitoring when developing BizTalk integration (maybe because of the fact that they’re similar to traditional exceptions in software). There are also here a couple of different ways to solve the problem.
Microsoft BizTalk Server Management Pack for Operation Manager mentioned above has the functionality to monitor and altering on suspended messages.
BizTalk Server fires the MSBTS_ServiceInstanceSuspendedEvent WMI event every time a service instance gets suspended. It’s fully possible to write a service that watches for this event and then for example sends some sort of alert. Darren Jefford has an example on how do something like that in this post.
In BizTalk 2006 Failed Message Routing was introduced. This gives the developer the possibility to subscribe to suspended messages. These can then for example be sent out to file system or written to a database. Microsoft ESB Guidance for BizTalk Server 2006 R2 Exception management component uses this approach. The problem with this approach is however that the message is moved out of BizTalk and one loses all the built in possibilities of resending them etc.
- **Heartbeat (monitoring actual successful traffic)
As I said before I think this is a very important metric. If you can see that messages travel through BizTalk in a normal rate things much be pretty ok – right? Without doing to much coding and developing you own pipeline components for tracking etc there are two options.
**
The first one is of course using the Health and Activity Tracking tool (HAT). This shows a simple view of receives, processed and sent messages. I hate to say it but the HAT tool is bad. It’s slow, it’s hard to use, it’s hard to filter information, it times out, it doesn’t aggregate information, it’s basically almost useless … (Just to make one thing clear: I make my living working with BizTalk and I really enjoy the product but tracking and monitoring is really one of it’s ugly sides. I hate to say it.)
The other option is to develop a simple BAM tracking profile to monitoring the send and receive port ports of the different processes.
So to repeat what I said earlier: no I don’t think BizTalk comes with the right tool to monitor integration solutions. I do however think that the platform has the capabilities to create something that could close that gap in the product.
What I need!
Much of what’s discussed in this post can be solved using the BizTalk Administrations Console (to manually monitor BizTalk infrastructure status) or in the Health and Activity Tracking tool (to manually monitor traffic). The aim of this post is however to discuss the possibilities to use this information, aggregate it and give the persons responsible for monitoring integration a dashboard that shows the current status of all integrations within the enterprise.
The dashboard monitor application need the following main features.
-
In one single screen give an overview of the overall status of all the integrations. By status I mean if there are ports, orchestration or host instances that aren’t running that should be running or if there is any suspended traffic on that particular integration.
-
The possibility to show detailed information for a specific integration on what artifacts (ports, host instances etc) that are/aren’t running. How much traffic that’s been sent/received via the integration. When traffic was sent/received and if there’s any suspended messages on the integration.
-
The option to filter exclude specific artifacts from monitoring (for example receive locations that’s usually turned off etc).
-
Setting up monitoring by for example email and also define what integrations to be included in one specific monitoring (different persons are usually responsible for monitoring different integrations).
Introducing “BizMon”
Based on the needs and “requirements” above I’ve started developing a application. The idea is to release it as open-source as soon as I get to a first stable version (I’d be very interested in help on practical details on how to do so). For now I’ll demonstrate it by showing some screenshots. The application is a web application based on ASP.NET MVC.
Screenshot: “Applications” page
The above image shows a screenshot from the start page of the BizMon-application that shows the aggregated status of the entire BizTalk group it’s connected to. The applications is build to monitor one BizTalk group and the shown page displays all applications within that BizTalk group.
In the example image the two first rows have an OK status. That means that all of the monitored artifacts (receive locations, send ports, orchestrations and host instances) within that application are in a running and OK status.
The yellow line on the YIT.NO.Project-application indicates a warning. That means that all the artifacts are in a OK status but there’re suspended messages within that application. The red line indicates that one or more of the monitored artifacts are in a inactive status.
Each row and application show when the last message on that application was received and/or sent. It also show how many suspended messages exists and when the last message got suspended.
Screenshot: “Application-detail” page
When clicking on a application on the main page previously shown the application-detail page is displayed for that application. This page shows detailed information on each of the artifacts within that application. I also shows suspended messages and the date and time of the last suspended.
It also displays a graph showing how many messages that has been processed by each of the ports. Currently the graph can view data from the last 7 days. In the screenshot above data from the 6th of January is shown and as it’s set to display data for a specific day the data is grouped in hours of that day. It’s also possible to view the aggregated data from all the traced days as show below. When viewing data from all days the graphs is grouped by days.
(The graph only shows data from the 6th of January as this is from test and there was no traffic of the previous days but I’m sure you get the idea …)
Screenshot: “Application-detail” page with inactive artifacts
This final page show details of an application with some inactive artifacts. The small cross highlighted by the arrow in the image show the possibility to filter out a single artifact from monitoring. If an excluded artifacts is failing the overall status of the application will still be OK and no alerts will be sent.
Help!
I’d love to get some input and feedback on all this. What do you think could be useful, what do you think won’t? Do you know of something similar, how do you solve this kind of monitoring?
I’d also like to know any suitable placed to publish the code as an open-source project or is the best thing to just release it here on the blog? What do you think? Use the comments or send me a mail.
What’s next?
I have a few thing on the alerts part of the application left and then I’ll release a first version. I’m hoping that could happened at the end of February 09 (look at the update at the top of the post) . Make sure to let me know what you think!
I’ll publish a follow-up post discussing the technical details and the architecture more in detail shortly.

by Richard | Nov 12, 2008 | BizTalk Community Blogs via Syndication
This is a very specific problem but I’m sure some of you stumbled over it. When disassembling a XML message in a SOAP port BizTalk can’t read the message type. This causes problems when for example trying to handle an envelope message and split it to smaller independent messages in the port. It’s a known problem discussed here and here (you also find information about it in the BizTalk Developer’s Troubleshooting Guide) and the solution is to make a small change in the generated web service class. Below is a small part of he generated class.
//[cut for clarity] ...
Microsoft.BizTalk.WebServices.ServerProxy.ParamInfo[] outParamInfos = null;
string bodyTypeAssemblyQualifiedName = "XXX.NO.XI.CustomerPayment.Schemas.r1.CustomerPayments_v01, XXX.NO.XI.CustomerPaym" +
"ent.Schemas.r1, Version=1.0.0.0, Culture=neutral, PublicKeyToken=ac564f277cd4488" +
"e";
// BizTalk invocation
this.Invoke("SaveCustomerPayment", invokeParams, inParamInfos, outParamInfos, 0, bodyTypeAssemblyQualifiedName, inHeaders, inoutHeaders, out inoutHeaderResponses, out outHeaderResponses, null, null, null, out unknownHeaderResponses, true, false);
}
}
}
Basically the problem is that the generated code puts the wrong DocumentSpecName property in the message context. I’ll not dicusses the problem in detail here but Saravana Kumar does thorough dissection of the problem in his post on it.
The solution is to update the bodyTypeAssemblyQualifiedName to set a null value. That will cause the XmlDiassasemler to work as we’re used to and expect.
>
> If the value _null_ is passed instead of _bodyTypeAssemblyQualifiedName_, SOAP adapter won’t add the _DocumentSpecName_ property to the context. Now, when we configure our auto-generated SOAP_ReceiveLocation_ to use _XmlReceive_ pipeline, the _XmlDisassembler_ component inside _XmlReceive_ will go through the process of automatic dynamic schema resolution mechanism, pick up the correct schema and promotes all the required properties (distinguished and promoted) defined in the schema and it also promotes the _MessageType_ property.
>
>
>
> **From:** [http://www.digitaldeposit.net/saravana/post/2007/08/17/SOAP-Adapter-and-BizTalk-Web-Publishing-Wizard-things-you-need-to-know.aspx](http://www.digitaldeposit.net/saravana/post/2007/08/17/SOAP-Adapter-and-BizTalk-Web-Publishing-Wizard-things-you-need-to-know.aspx)
>
>
//[cut for clarity] ...
Microsoft.BizTalk.WebServices.ServerProxy.ParamInfo[] outParamInfos = null;
string bodyTypeAssemblyQualifiedName = null;
// BizTalk invocation
this.Invoke("SaveCustomerPayment", invokeParams, inParamInfos, outParamInfos, 0, bodyTypeAssemblyQualifiedName, inHeaders, inoutHeaders, out inoutHeaderResponses, out outHeaderResponses, null, null, null, out unknownHeaderResponses, true, false);
}
}
}
But if you have an automated deployment process you probably use MSBuild to generate your Web Services. Then is soon becomes very annoying to remember to update the .cs-file again and again for every deployment. So how can we script that update?
First we need to find a regular expression to find the right values. With some help from StackOverflow (let’s face it, there are some crazy regular expressions skills out there …) I ended up on the following.
(?<=stringsbodyTypeAssemblyQualifiedNames=s)(?s:[^;]*)(?=;)
If you’re not a RegEx ninja the line above does something like this:
-
After the string “string bodyTypeAssemblyQualifiedName = “
-
turn on single line (treat “rn” as any other character) ( this is what “(?s: )” does)
-
match every character that is not a semicolon
-
until a single semicolon is reached.
Then I used a task from the SDC Task library (you probably already use this if you’re using MSBuild and BizTalk). More specially we use the File.Replace
<Target Name="FixSOAPServiceCode">
<File.Replace
Path="$(WebSiteServicePath)CustomerPaymentServiceApp_CodeCustomerPaymentService.asmx.cs"
Force="true"
NewValue="null"
RegularExpression="(?<=stringsbodyTypeAssemblyQualifiedNames=s)(?s:[^;]*)(?=;)">
</File.Replace>
</Target>
Now this task is part of the build script and called right after the tasks that generates the web service. This saves me a lot of manual work and potential errors!
by Richard | Oct 30, 2008 | BizTalk Community Blogs via Syndication
I’ll start by saying that I really (like in “really, really!“) like BizUnit! BizUnit in combination with MSBuild, NUnit and CruiseControl.NET has really changed the way work and how I feel about work in general and BizTalk development in particular.
If you haven’t started looking into what for example MSBuild can do you for you and your BizTalk build process you’re missing out on something great. The time spent on setting up a automatic build process is time well spent – take my word for it!
But build processes isn’t was this post is supposed to be about. This post is about one of the few limitations of BizUnit and the possibilities to work around one of those in particular.
BizUnit is a test framework that is intended to test Biztalk solutions. BizUnit was created by Kevin.B.Smith and can be found on [this CodePlex space](http://www.codeplex.com/bizunit) . BizUnit has quite a significant number of steps that have nothing to do with Biztalk per se and can be used for any integration project testing.
>
>
[](../assets/2008/10/windowslivewriterusingbizunitextensionstopokesomexml-d286note-2.gif)If you have used BizUnit before and need an introduction before reading further, start [here](http://www.codeproject.com/KB/biztalk/BizUnit2006.aspx), [here](http://www.codeplex.com/bizunit) or [here](http://biztalkia.blogspot.com/2007/03/getting-started-with-nunit-and-bizunit.html) – they’re all excellent articles.
>
>
As stated BizTalk has quite a significant number of steps but to my knowledge it’s missing a step to change and update file from within the test script. This step and a couple of other are added in separate fork-project to BizUnit called BizUnitExtensions.
This project [_BizUnitExtension_] aims to provide some more test step libraries, tools and utilities to enhance the reach of BizUnit. Here you can find some enhancements/extensions to the steps in the base libraries , new steps, support applications, tutorials and other documentation to help you understand and use it….This project is currently owned and contributed to by Santosh Benjamin and Gar Mac Críostaand. Our colleagues have also contributed steps and suggestions. We welcome more participation and contributions.
>
>
Amongst other steps (some for Oracle DBs etc) BizUnitExtensions adds a XmlPokeStep!
**XmlPokeStep:** This step is modelled on the lines of the NAnt XmlPoke task The XmlPokeStep is used to update data in an XML file with values from the context This will enable the user to write tests which can use the output of one step to modify the input of another step.
>
>
A cool thing about BizUnitExtensions is that it really just extends BizUnit. You’ll continue to run on the BizUnit dll:s when you use steps form BizUnit and just use the BizUnitExtensions code when you actually use some of steps from that library.
The example below shows how we first use an ordinary BizUnit task to validate and read a value from a file. We then use BizUnitExtension to gain some new powers and update the file with that value we just read.
<!–Ordinary BizUnit step to validate a file –>
<TestStep assemblyPath="" typeName="Microsoft.Services.BizTalkApplicationFramework.BizUnit.FileValidateStep">
<Timeout>5000</Timeout>
<Directory>....ReceiveRequest</Directory>
<SearchPattern>*Request.xml</SearchPattern>
<DeleteFile>false</DeleteFile>
<ContextLoaderStep assemblyPath="" typeName="Microsoft.Services.BizTalkApplicationFramework.BizUnit.XmlContextLoader">
<XPath contextKey="messageID">/*[local-name()=’SystemRequest’]/ID</XPath>
</ContextLoaderStep>
</TestStep>
<!–Use BizUnitExtensions to poke the value and change it –>
<TestStep assemblyPath="BizUnitExtensions.dll" typeName="BizUnit.Extensions.XmlPokeStep">
<InputFileName>....SystemResponse.xml</InputFileName>
<XPathExpressions>
<Expression>
<XPath>/*[local-name()=’SystemResponse’]/ID</XPath>
<NewValue takeFromCtx="messageID"></NewValue>
</Expression>
</XPathExpressions>
</TestStep>
This of course means that all you need to extend you current test steps and gain some cool new abilities is to add another assembly to you test project
Using BizUnitExtensions in a “real” scenario
An scenario when this can be useful is the following example were we need to test some message correlation.
-
A message request is received via a web service.
-
The message is sent to a queue via an orchestration in BizTalk. To be able to correlate the response a message id is added to the message request sent to the back-end system.
-
A message response is sent from the back-end system using a second queue. The response message contains the same message id as the incoming request contained.
-
BizTalk correlates the message back to the web service using the message id.
So how can we now test this? The steps should be something like the below.
>
> [](../assets/2008/10/windowslivewriterusingbizunitextensionstopokesomexml-d286note-4.gif) Notice that we read and write to the file system in the example. Once deployed to test these send ports and receive location will be reconfigured to use the queuing adapter. But for testing the scenario the file system works just fine a simplifies things IMHO.
>
>
- Send a request message using BizUnit and the HttpRequestResponseStep. Make sure it runs concurrently with the other steps and then wait for a response (using the runConcurrently-attribute on the step).
- Configure the send port so the orchestration that added the generated message id writes the message to a folder. Use the FileValidateStep and a nested XmlContextLoader to read the message from the folder and write the message id the context.
- Use the context and the XmlPokeStep from BizUnitExtensions to update a response message template with the message id from the request message (this is of course needed so we can correlate the response message back to the right orchestration).
-
Copy the update response message template using the FileCreateStep to the folder that is monitored by the the receive location used for reading responses.
<!–Clean up!–>
….ReceiveRequest.….SendResponse.
<TestExecution>
<!–Post a request message on the SOAP port. Run it Concurrently–>
<TestStep assemblyPath="" typeName="Microsoft.Services.BizTalkApplicationFramework.BizUnit.HttpRequestResponseStep" runConcurrently="true">
<SourcePath>....WebRequest.xml</SourcePath>
<DestinationUrl>http://localhost:8090/BizTalkWebService/WebService1.asmx?op=WebMethod1</DestinationUrl>
<RequestTimeout>15000</RequestTimeout>
</TestStep>
<!–Read the system request message and read the generaed id to the context–>
<TestStep assemblyPath="" typeName="Microsoft.Services.BizTalkApplicationFramework.BizUnit.FileValidateStep">
<Timeout>5000</Timeout>
<Directory>....ReceiveRequest</Directory>
<SearchPattern>*Request.xml</SearchPattern>
<DeleteFile>false</DeleteFile>
<ContextLoaderStep assemblyPath="" typeName="Microsoft.Services.BizTalkApplicationFramework.BizUnit.XmlContextLoader">
<XPath contextKey="messageID">/*[local-name()=’SystemRequest’]/ID</XPath>
</ContextLoaderStep>
</TestStep>
<!–If we have the file in source control it might be read-only -> remove that attribute–>
<TestStep assemblyPath="" typeName="Microsoft.Services.BizTalkApplicationFramework.BizUnit.ExecuteCommandStep">
<ProcessName>attrib</ProcessName>
<ProcessParams>SystemResponse.xml -r</ProcessParams>
<WorkingDirectory>....</WorkingDirectory>
</TestStep>
<!–Update our response template (using BizUnitExtensions) and add the message id that we read into the the context–>
<TestStep assemblyPath="BizUnitExtensions.dll" typeName="BizUnit.Extensions.XmlPokeStep">
<InputFileName>....SystemResponse.xml</InputFileName>
<XPathExpressions>
<Expression>
<XPath>/*[local-name()=’SystemResponse’]/ID</XPath>
<NewValue takeFromCtx="messageID"></NewValue>
</Expression>
</XPathExpressions>
</TestStep>
<!–Wait a moment so we don’t copy the file until we’re done updating it–>
<TestStep assemblyPath="" typeName="Microsoft.Services.BizTalkApplicationFramework.BizUnit.DelayStep">
<Delay>1000</Delay>
</TestStep>
<!–Copy the file to the folder that monitored by the receive location for opicking up system responses–>
<TestStep assemblyPath="" typeName="Microsoft.Services.BizTalkApplicationFramework.BizUnit.FileCreateStep">
<SourcePath>....SystemResponse.xml</SourcePath>
<CreationPath>....SendResponseSystemResponse.xml</CreationPath>
</TestStep>
</TestExecution>
This might look messy at first but I think it’s really cool I also think it worth thinking about on how you should run this at during development otherwise? You would then have to build some small stub to return a response message with the right id … I prefer this method!
BizUnitExtension makes me like BizUnit even more! Thanks to Kevin. B. Smith, Santosh Benjamin and Gar Mac Críostaand for spending so much time on this and sharing it with us mere mortals!
Update: Gar’s blog can be found here.

by Richard | Sep 5, 2008 | BizTalk Community Blogs via Syndication
Lately I’ve been using custom Xslt more and more instead of the BizTalk mapping tool. I still use the mapping tool in easy scenarios when I just need to do some straight mapping or maybe even when I need to concatenate some fields, but as soon as I need to to some looping, grouping, calculations etc I’ve made a promise to myself to use custom Xslt!
I find custom Xslt so much easier in more complex scenarios and once one get past the template matching and understands how and when to use recursion (No you can’t reassign a variable in Xslt and you’re not supposed to!) I find it to be a dream compared to the mapping tool. I also find the code so much easier to maintain compared to the result from the mapping tool. I mean someone would have to pay me good money to even start figuring out what this map is doing. And the scary thing is that if you worked with BizTalk for a while you probably know that maps like this isn’t that rare! I’ve even seen worse!
Don’t get me wrong, Xslt definitely has some major limitations.
Some of the acute limitations of XSLT 1.0 I can think of off the top of my head are:
>
> * The lack of real string comparison
> * No support for dates
> * No simple mechanism for grouping
> * No querying into RTF’s
>
And it doesn’t take long before one runs up against one of these and suddenly you wish you were back in mapping tool were we just could add scripting functoid and some code or a external assembly. But then you remember … (Sorry, I know it’s painful just to watch it).
There has to be a better way of doing this and combining the best out of the two worlds!
I started looking into to how BizTalk actually solves combining Xslt and the possibility to use external assemblies. After a couple of searches I found Yossi’s nice article that explained it to me (from 2005! I’m behind on this one!) and it even turns out that there an example in the BizTalk SDK.
Ok, so now I had what I need. I started a new class library project and began writing some date parsing methods, some padding methods and so on.
It somehow however felt wrong from the start and I got this grinding feeling that I must be reinventing the wheel (I mean these are well know limitations of Xslt and must have been solved before). Even worse I also felt that I was creating a stupid single point of failure as I started using the component from all different maps in my projects and I have actually seen how much pain a bug in similar shared dll:s could cause. Basically a small bug in the component could halt all the process using the library! Finally I realized that this kind of library would be under constant development as we ran into more and more areas of limitations in the our Xslt:s and that would just increase the risk of errors and mistakes.
After some further investigation I found EXSLT which looked like a solution to my problems! A stable, tested library of Xslt extensions that we could take dependency on as it’s unlikely to have any bugs and that should include the functionality we’re missing in standard Xslt!
How I used EXSLT in BizTalk
These days it’s the Xml Mvp crowd over at the Mvp.Xml project who develops and maintains the .NET implementation of EXSLT. So I downloaded the latest binaries (version 2.3). Put the the Mvp.Xml.dll in the GAC. Wrote a short custom extension Xml snippet that looked like this (using what I’ve learnt from Yossi’s article).
<?xml version="1.0" encoding="utf-8"?>
<ExtensionObjects>
<ExtensionObject
Namespace="http://exslt.org/dates-and-times"
AssemblyName="Mvp.Xml,
Version=2.3.0.0, Culture=neutral,
PublicKeyToken=6ead800d778c9b9f"
ClassName="Mvp.Xml.Exslt.ExsltDatesAndTimes"/>
</ExtensionObjects>
All you define is the Xml namespace you like to use in your Xslt to reference the dll, the full assembly name and finally the name of the class in Mvp.Xml.Exslt you want to use (make sure you also download the source to Xml.Mvp, it helps when looking up in what classes and namespaces different methods are placed).
That means you need one ExtensionObjects block for each class you want you use which really isn’t a problem as the methods are nicely structured based on there functionality.
Then we can use this in a Xslt like this:
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:S1="http://ExtendedMapping.Schema1"
xmlns:S2="http://ExtendedMapping.Schema2"
xmlns:exslt="http://exslt.org/dates-and-times"
version="1.0">
<xsl:template match="/">
<S2:Root>
<Field>
<xsl:value-of select="exslt:dateTime()"/>
</Field>
</S2:Root>
</xsl:template>
</xsl:stylesheet>
Which gives us the below output. Notice the current time and date! Cool!
<S2:Root xmlns:S1="http://ExtendedMapping.Schema1" xmlns:S2="http://ExtendedMapping.Schema2" xmlns:exslt="http://exslt.org/dates-and-times">
<Field>2008-09-05T20:45:13+02:00</Field>
</S2:Root>
All you then have to do in you map is to reference the Xslt and the extension Xml.
Just as final teaser I’ll paste a few methods from the EXSLT documentation
Some string methods:
-
str:align()
-
str:concat()
-
str:decode-uri()
-
str:encode-uri()
-
str:padding()
-
str:replace()
-
str:split()
-
str:tokenize()
Some date and time methods:
As if this was enough (!) the Mvp Xml project added a couple of there own methods! What about string lowercase and string uppercase – all in Xslt! And about 30 new date-time related methods extra to the standard ones already in EXSLT!
Check out the full documentation here!
Let me know how it works out for you.
by Richard | Jul 16, 2008 | BizTalk Community Blogs via Syndication
I’ve seen people struggle both on the forums and while doing consulting when in it comes to finding an good way of grouping and transforming content in file before debatching it. Say for example we have a text file like the example below.
0001;Test row, id 0001, category 10;10
0002;Test row, id 0002, category 10;10
0003;Test row, id 0003, category 10;10
0004;Test row, id 0004, category 20;20
0005;Test row, id 0005, category 20;20
0006;Test row, id 0006, category 20;20
0007;Test row, id 0007, category 20;20
0008;Test row, id 0008, category 10;10
0009;Test row, id 0009, category 10;10
0010;Test row, id 0010, category 30;30
Notice how the the ten rows belong to three different categories (10,20 and 30). These kind of export are in my experience quite common batch export from legacy systems and they usually aren’t ten rows (in my last project the sizes ranged from 5 MB to 25 MB) …
The problem
The problem is that the receiving system expects the data to be in separate groups, grouped by the categories the rows belong to. The expected message might look something like the below for category 10 (notice how all rows within the group are from category 10)
<ns1:Group numberOfRows="5" xmlns:ns1="http://Blah/Group">
<Row>
<Id>0001</Id>
<Text>Test row, id 0001, category 10</Text>
<Category>10</Category>
</Row>
<Row>
<Id>0002</Id>
<Text>Test row, id 0002, category 10</Text>
<Category>10</Category>
</Row>
<Row>
<Id>0003</Id>
<Text>Test row, id 0003, category 10</Text>
<Category>10</Category>
</Row>
<Row>
<Id>0008</Id>
<Text>Test row, id 0008, category 10</Text>
<Category>10</Category>
</Row>
<Row>
<Id>0009</Id>
<Text>Test row, id 0009, category 10</Text>
<Category>10</Category>
</Row>
</ns1:Group>
The problem is now that we need to find a efficient way of first grouping the incoming flat file based message and then to debatch it using those groups. Our ultimate goal is to have separate messages that groups all rows that belongs to the same category and then send these messages to the receiving system. How would you solve this?
I’ve seen loads of different solution involving orchestrations, databases etc, but the main problem they all had in common is that they’ve loaded up to much of the message in memory and finally hit an OutOfMemoryException.
The solution
The way to solve this is to use pure messaging as one of the new features in BizTalk 2006 is the new large messages transformation engine.
>
> **Large message transformation.** In previous versions of BizTalk Server, mapping of documents always occurred in-memory. While in-memory mapping provides the best performance, it can quickly consume resources when large documents are mapped. In BizTalk Server 2006, large messages will be mapped by the new large message transformation engine, which buffers message data to the file system, keeping the memory consumption flat.
>
>
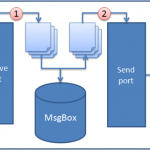
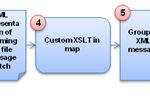
So the idea is the to read the incoming flat file, use the Flat File Disassembler to transform the message to it’s XML representation (step 1,2 and in the figure below) and the to use XSLT to transform in to groups (step 4 and 5). We will then use the XML Disassembler to split those groups into separate messages containing all the rows within a category (step 6 and 7).
Step 1, 2 and 3 are straight forward and pure configuration. Step 4 and 5 will require some custom XSLT and I’ll describe that in more detail in the section below. Step 6 and 7 will be discussed in the last section of the post.
Grouping
Let’s start by looking at a way to group the message. I will use some custom XSLT and a technique called the Muenchian method. A segment from the XML representation of the flat file message could look something like this.
<Rows xmlns="http://Blah/Incoming_FF">
<Row xmlns="">
<ID>0001</ID>
<Text>Test row, id 0001, category 10</Text>
<Category>10</Category>
</Row>
<Row xmlns="">
<ID>0002</ID>
<Text>Test row, id 0002, category 10</Text>
<Category>10</Category>
</Row>
...
[message cut for readability]
The XSLT will use could look something like the below. It’s kind of straight forward and I’ve tried commenting the important parts of in the actual script. Basically it will use keys to fins the unique categories and then (again using keys) selecting those rows within the category to loop and write to a group.
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:ns1="http://GroupAndDebatch.Schemas.Incoming_FF"
xmlns:ns2="http://GroupAndDebatch.Schemas.Grouped"
>
<!--Defining the key we're gonna use-->
<xsl:key name="rows-by-category" match="Row" use="Category" />
<xsl:template match="/ns1:Rows">
<ns2:Groups>
<!--Looping the unique categories to get a group for-->
<xsl:for-each select="Row[count(. | key('rows-by-category', Category)[1]) = 1]">
<!--Creating a new group and set the numberOfRows-->
<Group numberOfRows="{count(key('rows-by-category', Category))}">
<!--Loop all the rows within the specific category we're on-->
<xsl:for-each select="key('rows-by-category', Category)">
<Row>
<ID>
<xsl:value-of select="ID"/>
</ID>
<Text>
<xsl:value-of select="Text"/>
</Text>
<Category>
<xsl:value-of select="Category"/>
</Category>
</Row>
</xsl:for-each>
</Group>
</xsl:for-each>
</ns2:Groups>
</xsl:template>
</xsl:stylesheet>
>
> [](../assets/2008/07/windowslivewriterefficientgroupingandsplittingofbigfiles-8295note-2.gif)You have found all the [XSLT and XML related features](http://msdn.microsoft.com/en-us/library/aa302298.aspx) in Visual Studio – right?
>
>
Ok, so the above XSLT will give us a XML structure that looks some like this.
<?xml version="1.0" encoding="utf-8"?>
<ns2:Groups xmlns:ns2="http://Blah/Groups" xmlns:ns1="http://Blah/Group">
<ns1:Group numberOfRows="5">
<Row>
<ID>0001</ID>
<Text>Test row, id 0001, category 10</Text>
<Category>10</Category>
</Row>
<Row>
<ID>0002</ID>
<Text>Test row, id 0002, category 10</Text>
<Category>10</Category>
</Row>
<Row>
<ID>0003</ID>
<Text>Test row, id 0003, category 10</Text>
<Category>10</Category>
</Row>
<Row>
<ID>0008</ID>
<Text>Test row, id 0008, category 10</Text>
<Category>10</Category>
</Row>
<Row>
<ID>0009</ID>
<Text>Test row, id 0009, category 10</Text>
<Category>10</Category>
</Row>
</ns1:Group>
<ns1:Group numberOfRows="4">
<Row>
<ID>0004</ID>
<Text>Test row, id 0004, category 20</Text>
<Category>20</Category>
</Row>
...
[message cut for readability]
Finally! This we can debatch!
Debatching
Debatch the Groups message above is also rather straight forward and I won’t spend much time on in this post. The best way to learn more about it is to have a look ate the EnvelopeProcessing sample in the BizTalk SDK.
And the end result of the debatching are single messages within a unique category, just as the receiving system expects! Problem solved.
Issue #1 – slow transformations
The first time I’ve put a solution like this in test and started testing with some real sized messages (> 1 MB) I really panicked, the mapping took forever. And I really mean forever, I sat there waiting for 2-3 hours (!) for a single file getting transformed. When I had tested the same XML based file in Visual Studio the transformation took about 10 seconds so I knew that wasn’t it. With some digging here I found the TransformThreshold parameter.
TransformThreshold decides how big a message can be in memory before BizTalk start buffering it to disk. The default value is 1 MB and one really has to be careful when changing this. Make sure you thought hard about your solution and situation before changing the value – how much traffic do you receive and how much of that can you afford reading in to memory?
In my case I received a couple of big files spread out over a night so setting parameter with a large amount wasn’t really a problem and that really solved the problem. The mapping finished in below 10 minutes as I now allow a much bigger message to be read into memory and executed in memory before switching over to the large message transformation engine and start buffering to disk (which is always much slower).
Problem #2 – forced to temp storage
Looking at the model of the data flow again you probably see that I’m using the XML Disassembler to split the grouped files (step 5 to step 6).
The only way I’ve found this to work is actually to write the Grouped XML message to file and the to read that file in to BizTalk again and in that receive pipeline debatch the message. Not the most elegant solution, but there really isn’t a another out-of-the-box way of debatching messages (the XML Assembler can’t do it) and I don’t want to use an orchestration to execute the a pipeline as I want to keep the solution pure messaging for simplicity and performance reasons.
Finishing up
Have you solved similar cases differently? I’d be very interested in your experience! I also have a sample solution of this – just send me an email and make sure you’ll get it.
Update
Also don’t miss this issue (pdf) of BizTalk Hotrod magazine. There is an article on “Muenchian Grouping and Sorting using Xslt” describing exactly the problem discussed above.