
by [email protected] Steef-Jan Wiggers | Jul 24, 2014 | BizTalk Community Blogs via Syndication
There will be another BizTalk Summit event in august in Australia. The early bird tickets are on sale now until the end of this month! The event will take place in three different cities: Melbourne, Sydney and Brisbane.
I will be speaking at each of the events together with fellow MVP’s Saravana Kumar, Michael Stephenson, Bill Chesnut, Mikael Hakansson and Mick Badran on various topics around integration with the Microsoft technology stack: Microsoft Azure, BizTalk Service, BizTalk Server 2013 R2, Mobile, Office365, and BizTalk360.
My talk will specifically go into Microsoft Azure BizTalk Service, what it offers today, what scenarios can be supported, development-, deployment-, and operation perspective of this cloud service. Session is called:
Hitchhiker’s guide to integration with Microsoft Azure BizTalk Service
and the actual abstract:
Microsoft Azure BizTalk Service (MABS) is almost available to us for a year. It is a newcomer in the world of integration Platform as a Service (iPaaS) and promising contender for the sweet-spot in the Gartner’s Magic Quadrant. This service in Azure has a great deal to offer and can provide different means of integration in the changing IT world of on premise ERP systems, services, cloud and devices. In this session the audience will learn where the Microsoft Azure BizTalk Service stands in the middle of the iPaaS world, what it has to offer today and what the road-map will look like in the future. During the session there will be various demo’s showcasing the service features from a development, deployment and operations perspective.
You will find the agenda, other speaker bio’s, sessions and abstracts on the site, where you can register.
Looking forward to speak there and meet people in Australia. I have not seen this part of the world yet so it will be quite an adventure. See you there!
Cheers,
Steef-Jan
by community-syndication | Jul 24, 2014 | BizTalk Community Blogs via Syndication
In a previous post, I gave an example of a simple automation job. Here is a more interesting one.
Here is a sample Azure Automation code that creates an HDInsight cluster, runs a job, and removes the cluster.
I used it for a demonstration at the French Hadoop User Group. You can find the video (in French) where I explain what is does here (go to 01:40:00) :
When you start it, you can specify the options you want to activate:
The code is the following:
workflow HDInsightJob
{
param(
[Parameter(Mandatory=$false)]
[bool]$createCluster=$false,
[Parameter(Mandatory=$false)]
[bool]$runJob=$true,
[Parameter(Mandatory=$false)]
[bool]$removeCluster=$false
)
$subscription = 'Azdem169A44055X'
$azureConnection=Get-AutomationConnection -Name $subscription
$subscriptionId=$azureConnection.SubscriptionId
$azureCertificate=Get-AutomationCertificate -Name 'azure-admin.3-4.fr'
$clusterCredentials=Get-AutomationPSCredential -Name 'HDInsightClusterCredentials'
InlineScript
{
echo "RunBook V140629c"
echo $PSVersionTable
import-module azure
get-module azure
$createCluster=$using:createCluster
$runJob=$using:runJob
$removeCluster=$using:removeCluster
$subscription=$using:subscription
$subscriptionId=$using:subscriptionId
$azureCertificate=$using:azureCertificate
$clusterCredentials=$using:clusterCredentials
$defaultStorageAccount='monstockageazure'
$clusterName = 'monclusterhadoop'
$clusterContainerName = 'monclusterhadoop'
$clusterVersion='3.0' #3.1, 3.0, 2.1, 1.6
Set-AzureSubscription -SubscriptionName $subscription -SubscriptionId $subscriptionID -Certificate $azureCertificate -CurrentStorageAccount $defaultStorageAccount
Select-AzureSubscription -Current $Subscription
$storageAccount1 = (Get-AzureSubscription $Subscription).CurrentStorageAccountName
$key1 = Get-AzureStorageKey -StorageAccountName $storageAccount1 | %{ $_.Primary }
$storageAccount2Name = "wasbshared"
$storageAccount2Key = (Get-AzureStorageKey -StorageAccountName $storageAccount2Name).Secondary
if ($createCluster)
{
echo "will create cluster $clusterName"
New-AzureHDInsightClusterConfig -ClusterSizeInNodes 3 |
Set-AzureHDInsightDefaultStorage -StorageAccountName "${storageAccount1}.blob.core.windows.net" -StorageAccountKey $key1 -StorageContainerName $clusterContainerName |
Add-AzureHDInsightStorage -StorageAccountName $storageAccount2Name -StorageAccountKey $storageAccount2Key |
New-AzureHDInsightCluster -Name $clusterName -Version $clusterVersion -Location "North Europe" -Credential $clusterCredentials
echo "cluster created"
}
$wasbdemo = "wasb://[email protected]"
Use-AzureHDInsightCluster $clusterName
if ($runJob)
{
echo "will start job"
$pigJob = New-AzureHDInsightPigJobDefinition -File "$wasbdemo/scripts/iislogs-pig-jython/iislogs-client-ip-time.pig"
$pigJob.Files.Add("$wasbdemo/scripts/iislogs-pig-jython/iislogs-client-ip-time-helper.py")
$pigJob.Files.Add("$wasbdemo/scripts/iislogs-pig-jython/jython-2.5.3.jar")
$startedPigJob = $pigJob | Start-AzureHDInsightJob -Credential $clusterCredentials -Cluster $clusterName
echo "will wait for the end of the job"
$startedPigJob | Wait-AzureHDInsightJob -Credential $clusterCredentials
echo "--- log ---"
Get-AzureHDInsightJobOutput -JobId $startedPigJob.JobId -TaskSummary -StandardError -StandardOutput -Cluster $clusterName
echo "job done"
}
if ($removeCluster)
{
echo "will remove cluster"
Remove-AzureHDInsightCluster -Name $clusterName
echo "removed cluster"
}
echo "done"
}
}
Here is a sample log of that job:
RunBook V140629c
Name Value
---- -----
PSRemotingProtocolVersion 2.2
BuildVersion 6.3.9600.16406
PSCompatibleVersions {1.0, 2.0, 3.0, 4.0}
PSVersion 4.0
CLRVersion 4.0.30319.19455
WSManStackVersion 3.0
SerializationVersion 1.1.0.1
ModuleType Version Name ExportedCommands PSComputerName
---------- ------- ---- ---------------- --------------
Binary 0.8.0 azure {Remove-AzureStorageAccount,... localhost
will create cluster monclusterhadoop
PSComputerName : localhost
PSSourceJobInstanceId : b7a8dc2b-3e11-467f-8dad-2a1ac76da33f
ClusterSizeInNodes : 3
ConnectionUrl : https://monclusterhadoop.azurehdinsight.net
CreateDate : 6/29/2014 7:57:56 AM
DefaultStorageAccount : monstockageazure.blob.core.windows.net
HttpUserName : cornac
Location : North Europe
Name : monclusterhadoop
State : Running
StorageAccounts : {}
SubscriptionId : 0fa85b4c-aa27-44ba-84e5-fa51aac32734
UserName : cornac
Version : 3.0.3.234.879810
VersionStatus : Compatible
cluster created
Successfully connected to cluster monclusterhadoop
will start job
will wait for the end of the job
PSComputerName : localhost
PSSourceJobInstanceId : b7a8dc2b-3e11-467f-8dad-2a1ac76da33f
Cluster : monclusterhadoop
ExitCode : 0
Name :
PercentComplete : 100% complete
Query :
State : Completed
StatusDirectory : 54d76c5f-a0a3-4df8-84d3-8b58d05f51fd
SubmissionTime : 6/29/2014 8:12:17 AM
JobId : job_1404029421644_0001
--- log ---
2014-06-29 08:12:28,609 [main] INFO org.apache.pig.Main - Apache Pig version 0.12.0.2.0.9.0-1686 (r: unknown) compiled Jun 10 2014, 17:27:26
2014-06-29 08:12:28,609 [main] INFO org.apache.pig.Main - Logging error messages to: C:\apps\dist\hadoop-2.2.0.2.0.9.0-1686\logs\pig_1404029548609.log
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/C:/apps/dist/hadoop-2.2.0.2.0.9.0-1686/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/C:/apps/dist/pig-0.12.0.2.0.9.0-1686/pig-0.12.0.2.0.9.0-1686.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2014-06-29 08:12:29,609 [main] INFO org.apache.pig.impl.util.Utils - Default bootup file D:\Users\hdp/.pigbootup not found
2014-06-29 08:12:29,844 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2014-06-29 08:12:29,844 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS
2014-06-29 08:12:29,844 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: wasb://[email protected]
2014-06-29 08:12:30,515 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS
2014-06-29 08:12:30,547 [main] INFO org.apache.pig.scripting.jython.JythonScriptEngine - created tmp python.cachedir=D:\Users\hdp\AppData\Local\Temp\pig_jython_8612239229935485131
2014-06-29 08:12:32,781 [main] WARN org.apache.pig.scripting.jython.JythonScriptEngine - pig.cmd.args.remainders is empty. This is not expected unless on testing.
2014-06-29 08:12:34,828 [main] INFO org.apache.pig.scripting.jython.JythonScriptEngine - Register scripting UDF: helper.date_time_by_the_minute
2014-06-29 08:12:34,828 [main] INFO org.apache.pig.scripting.jython.JythonScriptEngine - Register scripting UDF: helper.new_uuid
2014-06-29 08:12:35,594 [main] INFO org.apache.pig.scripting.jython.JythonFunction - Schema 'hit_date_time:chararray' defined for func date_time_by_the_minute
2014-06-29 08:12:35,750 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig features used in the script: GROUP_BY,ORDER_BY,FILTER
2014-06-29 08:12:35,812 [main] INFO org.apache.pig.newplan.logical.optimizer.LogicalPlanOptimizer - {RULES_ENABLED=[AddForEach, ColumnMapKeyPrune, DuplicateForEachColumnRewrite, GroupByConstParallelSetter, ImplicitSplitInserter, LimitOptimizer, LoadTypeCastInserter, MergeFilter, MergeForEach, NewPartitionFilterOptimizer, PartitionFilterOptimizer, PushDownForEachFlatten, PushUpFilter, SplitFilter, StreamTypeCastInserter], RULES_DISABLED=[FilterLogicExpressionSimplifier]}
2014-06-29 08:12:35,844 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.textoutputformat.separator is deprecated. Instead, use mapreduce.output.textoutputformat.separator
2014-06-29 08:12:36,078 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MRCompiler - File concatenation threshold: 100 optimistic? false
2014-06-29 08:12:36,219 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.CombinerOptimizer - Choosing to move algebraic foreach to combiner
2014-06-29 08:12:36,297 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer - MR plan size before optimization: 3
2014-06-29 08:12:36,297 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer - MR plan size after optimization: 3
2014-06-29 08:12:36,594 [main] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at headnodehost/100.85.198.84:9010
2014-06-29 08:12:36,734 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig script settings are added to the job
2014-06-29 08:12:36,750 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.job.reduce.markreset.buffer.percent is deprecated. Instead, use mapreduce.reduce.markreset.buffer.percent
2014-06-29 08:12:36,750 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - mapred.job.reduce.markreset.buffer.percent is not set, set to default 0.3
2014-06-29 08:12:36,750 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.output.compress is deprecated. Instead, use mapreduce.output.fileoutputformat.compress
2014-06-29 08:12:36,750 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Reduce phase detected, estimating # of required reducers.
2014-06-29 08:12:36,750 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Using reducer estimator: org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.InputSizeReducerEstimator
2014-06-29 08:12:36,750 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.InputSizeReducerEstimator - BytesPerReducer=1000000000 maxReducers=999 totalInputFileSize=-1
2014-06-29 08:12:36,750 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Could not estimate number of reducers and no requested or default parallelism set. Defaulting to 1 reducer.
2014-06-29 08:12:36,750 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting Parallelism to 1
2014-06-29 08:12:36,750 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
2014-06-29 08:12:37,347 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - creating jar file Job1668949293984769897.jar
2014-06-29 08:12:46,909 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - jar file Job1668949293984769897.jar created
2014-06-29 08:12:46,909 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.jar is deprecated. Instead, use mapreduce.job.jar
2014-06-29 08:12:46,940 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting up single store job
2014-06-29 08:12:46,987 [main] INFO org.apache.pig.data.SchemaTupleFrontend - Key [pig.schematuple] is false, will not generate code.
2014-06-29 08:12:46,987 [main] INFO org.apache.pig.data.SchemaTupleFrontend - Starting process to move generated code to distributed cache
2014-06-29 08:12:46,987 [main] INFO org.apache.pig.data.SchemaTupleFrontend - Setting key [pig.schematuple.classes] with classes to deserialize []
2014-06-29 08:12:47,112 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 1 map-reduce job(s) waiting for submission.
2014-06-29 08:12:47,112 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.job.tracker.http.address is deprecated. Instead, use mapreduce.jobtracker.http.address
2014-06-29 08:12:47,112 [JobControl] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at headnodehost/100.85.198.84:9010
2014-06-29 08:12:47,206 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS
2014-06-29 08:12:49,043 [JobControl] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 71
2014-06-29 08:12:49,043 [JobControl] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths to process : 71
2014-06-29 08:12:49,090 [JobControl] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths (combined) to process : 12
2014-06-29 08:12:49,293 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - number of splits:12
2014-06-29 08:12:49,621 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - Submitting tokens for job: job_1404029421644_0002
2014-06-29 08:12:49,621 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - Kind: mapreduce.job, Service: job_1404029421644_0001, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@5b531130)
2014-06-29 08:12:49,636 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - Kind: RM_DELEGATION_TOKEN, Service: 100.85.198.84:9010, Ident: (owner=cornac, renewer=mr token, realUser=hdp, issueDate=1404029526385, maxDate=1404634326385, sequenceNumber=1, masterKeyId=2)
2014-06-29 08:12:50,058 [JobControl] INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1404029421644_0002 to ResourceManager at headnodehost/100.85.198.84:9010
2014-06-29 08:12:50,121 [JobControl] INFO org.apache.hadoop.mapreduce.Job - The url to track the job: http://headnodehost:9014/proxy/application_1404029421644_0002/
2014-06-29 08:12:50,121 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - HadoopJobId: job_1404029421644_0002
2014-06-29 08:12:50,121 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Processing aliases logs_date_cip,logs_date_cip_with_headers,logs_date_time_cip,logs_date_time_cip_count,logs_date_time_cip_group,logs_raw
2014-06-29 08:12:50,121 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - detailed locations: M: logs_raw[4,11],logs_date_cip_with_headers[5,29],logs_date_cip[6,16],logs_date_time_cip[7,21],logs_date_time_cip_count[9,27],logs_date_time_cip_group[8,27] C: logs_date_time_cip_count[9,27],logs_date_time_cip_group[8,27] R: logs_date_time_cip_count[9,27]
2014-06-29 08:12:50,168 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 0% complete
2014-06-29 08:13:33,534 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 4% complete
2014-06-29 08:13:36,784 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 11% complete
2014-06-29 08:13:39,034 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 16% complete
2014-06-29 08:13:39,566 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 20% complete
2014-06-29 08:13:41,258 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 33% complete
2014-06-29 08:13:46,533 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig script settings are added to the job
2014-06-29 08:13:46,533 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - mapred.job.reduce.markreset.buffer.percent is not set, set to default 0.3
2014-06-29 08:13:46,533 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Reduce phase detected, estimating # of required reducers.
2014-06-29 08:13:46,533 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Using reducer estimator: org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.InputSizeReducerEstimator
2014-06-29 08:13:46,533 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.InputSizeReducerEstimator - BytesPerReducer=1000000000 maxReducers=999 totalInputFileSize=-1
2014-06-29 08:13:46,533 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Could not estimate number of reducers and no requested or default parallelism set. Defaulting to 1 reducer.
2014-06-29 08:13:46,533 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting Parallelism to 1
2014-06-29 08:13:47,042 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - creating jar file Job8669508224269273799.jar
2014-06-29 08:13:56,229 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - jar file Job8669508224269273799.jar created
2014-06-29 08:13:56,261 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting up single store job
2014-06-29 08:13:56,276 [main] INFO org.apache.pig.data.SchemaTupleFrontend - Key [pig.schematuple] is false, will not generate code.
2014-06-29 08:13:56,276 [main] INFO org.apache.pig.data.SchemaTupleFrontend - Starting process to move generated code to distributed cache
2014-06-29 08:13:56,276 [main] INFO org.apache.pig.data.SchemaTupleFrontend - Setting key [pig.schematuple.classes] with classes to deserialize []
2014-06-29 08:13:56,307 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 1 map-reduce job(s) waiting for submission.
2014-06-29 08:13:56,307 [JobControl] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at headnodehost/100.85.198.84:9010
2014-06-29 08:13:56,386 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS
2014-06-29 08:13:57,318 [JobControl] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 1
2014-06-29 08:13:57,318 [JobControl] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths to process : 1
2014-06-29 08:13:57,318 [JobControl] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths (combined) to process : 1
2014-06-29 08:13:57,505 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - number of splits:1
2014-06-29 08:13:57,630 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - Submitting tokens for job: job_1404029421644_0003
2014-06-29 08:13:57,630 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - Kind: mapreduce.job, Service: job_1404029421644_0001, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@3c124a75)
2014-06-29 08:13:57,630 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - Kind: RM_DELEGATION_TOKEN, Service: 100.85.198.84:9010, Ident: (owner=cornac, renewer=mr token, realUser=hdp, issueDate=1404029526385, maxDate=1404634326385, sequenceNumber=1, masterKeyId=2)
2014-06-29 08:13:57,755 [JobControl] INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1404029421644_0003 to ResourceManager at headnodehost/100.85.198.84:9010
2014-06-29 08:13:57,771 [JobControl] INFO org.apache.hadoop.mapreduce.Job - The url to track the job: http://headnodehost:9014/proxy/application_1404029421644_0003/
2014-06-29 08:13:57,771 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - HadoopJobId: job_1404029421644_0003
2014-06-29 08:13:57,771 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Processing aliases logs_date_time_cip_count_ordered
2014-06-29 08:13:57,771 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - detailed locations: M: logs_date_time_cip_count_ordered[10,35] C: R:
2014-06-29 08:14:16,338 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 50% complete
2014-06-29 08:14:24,487 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 66% complete
2014-06-29 08:14:28,544 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig script settings are added to the job
2014-06-29 08:14:28,544 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - mapred.job.reduce.markreset.buffer.percent is not set, set to default 0.3
2014-06-29 08:14:28,544 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Reduce phase detected, estimating # of required reducers.
2014-06-29 08:14:28,544 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting Parallelism to 1
2014-06-29 08:14:29,021 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - creating jar file Job3067576297837929164.jar
2014-06-29 08:14:38,100 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - jar file Job3067576297837929164.jar created
2014-06-29 08:14:38,115 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting up single store job
2014-06-29 08:14:38,115 [main] INFO org.apache.pig.data.SchemaTupleFrontend - Key [pig.schematuple] is false, will not generate code.
2014-06-29 08:14:38,115 [main] INFO org.apache.pig.data.SchemaTupleFrontend - Starting process to move generated code to distributed cache
2014-06-29 08:14:38,115 [main] INFO org.apache.pig.data.SchemaTupleFrontend - Setting key [pig.schematuple.classes] with classes to deserialize []
2014-06-29 08:14:38,162 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 1 map-reduce job(s) waiting for submission.
2014-06-29 08:14:38,193 [JobControl] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at headnodehost/100.85.198.84:9010
2014-06-29 08:14:38,256 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS
2014-06-29 08:14:39,129 [JobControl] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 1
2014-06-29 08:14:39,129 [JobControl] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths to process : 1
2014-06-29 08:14:39,145 [JobControl] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths (combined) to process : 1
2014-06-29 08:14:39,333 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - number of splits:1
2014-06-29 08:14:39,442 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - Submitting tokens for job: job_1404029421644_0004
2014-06-29 08:14:39,442 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - Kind: mapreduce.job, Service: job_1404029421644_0001, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@6791a1a0)
2014-06-29 08:14:39,442 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - Kind: RM_DELEGATION_TOKEN, Service: 100.85.198.84:9010, Ident: (owner=cornac, renewer=mr token, realUser=hdp, issueDate=1404029526385, maxDate=1404634326385, sequenceNumber=1, masterKeyId=2)
2014-06-29 08:14:40,604 [JobControl] INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1404029421644_0004 to ResourceManager at headnodehost/100.85.198.84:9010
2014-06-29 08:14:40,610 [JobControl] INFO org.apache.hadoop.mapreduce.Job - The url to track the job: http://headnodehost:9014/proxy/application_1404029421644_0004/
2014-06-29 08:14:40,610 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - HadoopJobId: job_1404029421644_0004
2014-06-29 08:14:40,610 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Processing aliases logs_date_time_cip_count_ordered
2014-06-29 08:14:40,610 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - detailed locations: M: logs_date_time_cip_count_ordered[10,35] C: R:
2014-06-29 08:14:55,976 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 83% complete
2014-06-29 08:15:11,394 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 100% complete
2014-06-29 08:15:11,597 [main] INFO org.apache.pig.tools.pigstats.SimplePigStats - Script Statistics:
HadoopVersion PigVersion UserId StartedAt FinishedAt Features
2.2.0.2.0.9.0-1686 0.12.0.2.0.9.0-1686 hdp 2014-06-29 08:12:36 2014-06-29 08:15:11 GROUP_BY,ORDER_BY,FILTER
Success!
Job Stats (time in seconds):
JobId Maps Reduces MaxMapTime MinMapTIme AvgMapTime MedianMapTime MaxReduceTime MinReduceTime AvgReduceTime MedianReducetime Alias Feature Outputs
job_1404029421644_0002 12 1 33 16 29 31 20 20 20 20 logs_date_cip,logs_date_cip_with_headers,logs_date_time_cip,logs_date_time_cip_count,logs_date_time_cip_group,logs_raw GROUP_BY,COMBINER
job_1404029421644_0003 1 1 7 7 7 7 5 5 5 5 logs_date_time_cip_count_ordered SAMPLER
job_1404029421644_0004 1 1 5 5 5 5 7 7 7 7 logs_date_time_cip_count_ordered ORDER_BY /wasbwork/iislogs-client-ip,
Input(s):
Successfully read 592234 records from: "wasb://[email protected]/data/iislogs"
Output(s):
Successfully stored 712 records in: "/wasbwork/iislogs-client-ip"
Counters:
Total records written : 712
Total bytes written : 0
Spillable Memory Manager spill count : 0
Total bags proactively spilled: 0
Total records proactively spilled: 0
Job DAG:
job_1404029421644_0002 -> job_1404029421644_0003,
job_1404029421644_0003 -> job_1404029421644_0004,
job_1404029421644_0004
2014-06-29 08:15:31,611 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: workernode0/100.85.210.91:49416. Already tried 0 time(s); maxRetries=3
2014-06-29 08:15:51,619 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: workernode0/100.85.210.91:49416. Already tried 1 time(s); maxRetries=3
2014-06-29 08:16:11,631 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: workernode0/100.85.210.91:49416. Already tried 2 time(s); maxRetries=3
2014-06-29 08:16:31,768 [main] INFO org.apache.hadoop.mapred.ClientServiceDelegate - Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server
2014-06-29 08:16:54,015 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: workernode1/100.85.164.84:49580. Already tried 0 time(s); maxRetries=3
2014-06-29 08:17:14,021 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: workernode1/100.85.164.84:49580. Already tried 1 time(s); maxRetries=3
2014-06-29 08:17:34,027 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: workernode1/100.85.164.84:49580. Already tried 2 time(s); maxRetries=3
2014-06-29 08:17:54,161 [main] INFO org.apache.hadoop.mapred.ClientServiceDelegate - Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server
2014-06-29 08:17:56,525 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: workernode2/100.85.206.85:49658. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=3, sleepTime=1 SECONDS)
2014-06-29 08:17:58,543 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: workernode2/100.85.206.85:49658. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=3, sleepTime=1 SECONDS)
2014-06-29 08:18:00,583 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: workernode2/100.85.206.85:49658. Already tried 2 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=3, sleepTime=1 SECONDS)
2014-06-29 08:18:01,705 [main] INFO org.apache.hadoop.mapred.ClientServiceDelegate - Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server
2014-06-29 08:18:01,908 [main] WARN org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Encountered Warning ACCESSING_NON_EXISTENT_FIELD 330 time(s).
2014-06-29 08:18:01,908 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Success!
job done
will remove cluster
removed cluster
done
Benjamin (@benjguin)
Blog Post by: Benjamin GUINEBERTIERE
by community-syndication | Jul 24, 2014 | BizTalk Community Blogs via Syndication
the result
I regulalry need to check if my Azure virtual machines are turned off before leaving. Besides virtual machines, I also want to know in which pricing level my web sites, Azure SQL Databases, etc are running. I want to know if I have an HDInsight cluster running.
So I created an Azure automation job that checks the subscriptions at 6pm every day.
Here is how it looks:
How to start
You can start using Azure automation by following the instructions available here:
http://azure.microsoft.com/en-us/documentation/articles/automation-create-runbook-from-samples/
Credentials
The script will need to get access to the subscriptions.
So I created a management certificate. One way to do so is explained in this blog post by Keith Mayer.
In my case, here is how my environment looks:
In Azure automation, the same certificate is declared in the assets:
The script
Here is how the script itself:
workflow Inventory
{
# Get the Azure management certificate that is used to connect to this subscription
$Certificate = Get-AutomationCertificate -Name 'azure-admin.3-4.fr'
if ($Certificate -eq $null)
{
throw "Could not retrieve '$AzureConn.AutomationCertificateName' certificate asset. Check that you created this first in the Automation service."
}
InlineScript
{
$Certificate = $using:Certificate
$subscriptions = (('Azdem169A44055X','0fa8xxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx'),
('Azure bengui','b4edxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx'),
('APVX','0ec1xxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx'),
('demos-frazurete','4b57xxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx'))
foreach ($subscription in $subscriptions)
{
$subscriptionName = $subscription[0]
$subscriptionId = $subscription[1]
echo "------- Subscription $subscriptionName ----------"
# Set the Azure subscription configuration
Set-AzureSubscription -SubscriptionName $subscriptionName -SubscriptionId $subscriptionId -Certificate $Certificate
Select-AzureSubscription -Current $subscriptionName
$vms = @()
foreach ($s in Get-AzureService)
{
$vms += Get-AzureVm -ServiceName $s.ServiceName
}
echo "--- Virtual Machines ---"
$vms | select servicename, Name, PowerState | format-table
$hclusters=Get-AzureHDInsightCluster
echo "--- HDInsight clusters ---"
$hclusters | format-table
$webs=Get-AzureWebSite
echo "--- Web Sites ---"
$webs | select Name, SiteMode | sort Name | format-table
$dbs = @()
foreach ($s in Get-AzureSqlDatabaseServer)
{
$dbs += Get-AzureSqlDatabase -ServerName $s.ServerName
}
echo "--- SQL Databases ---"
$dbs | select Name, Edition, MaxSizeinGb | format-table
}
}
}
NB: I have obfuscated the subscription ids.
Make it your own
You can change the script for your own usage. You would need to change the certificate name (mine is azure-admin.3-4.fr), the names and ids of your subscriptions).
Benjamin (@benjguin)
Blog Post by: Benjamin GUINEBERTIERE
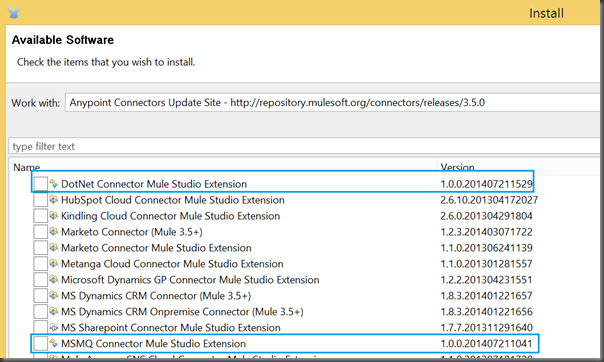
by community-syndication | Jul 23, 2014 | BizTalk Community Blogs via Syndication
For those of you who have been keeping your AnyPoint Studio up to date you may have been pleasantly surprised this week. The reason? MuleSoft released two important connectors for customers who leverage the Microsoft platform in their architectures. (You can read more about the official announcement here.)
More specifically, the two capabilities that were released this week include:
- .NET Connector
- MSMQ Connector
The MSMQ Connector is self explanatory but what is a .NET Connector? The .NET Connector allows .NET code to be called from a Mule Flow.
Why are these connectors important? For some, hating Microsoft is a sport, but the reality is that Microsoft continues to be very relevant in the Enterprise. In case you missed their recent earnings, they made 4.6 billion in net income for their past quarteryes that is a ’b’ and yes that was only for a quarter of the year.
Many customers continue to use MSMQ. Sometimes these solutions are custom .Net solutions where they are using MSMQ to add some durability for their messaging needs. Sometimes, these are legacy applications in maintenance mode but not always. Other use cases include purchasing a COTS (Commercial Off The Shelf) product that has a dependency on MSMQ.
While the MSMQ Connector is a nice addition to the MuleSoft portfolio of Connectors, the .NET Connector is what really gets me excited. I have been using .Net since the 1.1 release and am very comfortable in Visual Studio.
For many organizations, they have standardized on building their custom applications in .NET. I have worked for these companies in the past and for many of these organizations, programming in another language is a showstopper. There may be concerns about re-training, interoperability and productivity as a result of introducing new programming languages. Some people may consider this fear mongering, but the reality is if you have a strong Enterprise Architecture practice, you need to adhere to standards. While some people are willing to introduce many different languages into an environment, others are not.
The combination of the AnyPoint Platform and the ability to write any integration logic that is required in .NET is a very powerful combination for organizations that want to leverage their .NET skill sets.
How to invoke .NET Code from a Mule Flow? There are many resources being made available as part of this release so I don’t want to spoil that party (See conclusion for more resources). But let me provide a sneak peak. For those of you who may not be familiar with MuleSoft, we have the ability to write Mule Flows. You can think of these much like a Workflow or an Orchestration for my BizTalk friends. On the right hand side we have our pallete where we can drag Message processors or Connectors from the pallete to our Mule Flow.

Once our Connector is on our Mule Flow, we can configure it. We need to provide an Assembly Type, Assembly Path (can be relative or absolute), a Scope and a Trust level. This configuration is considered to be a Global Element and we only have to configure this once per .NET assembly.

Next we provide the name of the .NET Method that we want to call.

From there it is business as usual from a .NET perspective. I can send and receive complex types, JSON, XML Documents etc.

Conclusion
Hopefully this gives you a little taste of what is to come. I have had the opportunity to work with many Beta customers on this functionality and am very excited with where we are and where we are headed. What we are releasing now is just the beginning.
Stay tuned for more details on both the MSMQ and .NET Connectors. Now that these bits are public I am really looking forward to sharing this information with both the Microsoft and MuleSoft communities.
Other resources:
- Press Release
- MuleSoft Blog Post including two short video demos and registration link for an upcoming Webinar.
BTW: If this sounds interesting to you, we are hiring!!!





