by community-syndication | Jan 25, 2010 | BizTalk Community Blogs via Syndication
On monday 19 january I gave a presentation to the dutch BizTalk User Group (BTUG) about he BizTalk Best Practices. The Best Practices are a set of components, a loosly coupled architecture and a software factory that supports the components and the architecture…(read more)

by community-syndication | Jan 24, 2010 | BizTalk Community Blogs via Syndication
In case you’ve missed it, a hotfix was released in December that fixes a lot of the issues raised by BizTalk developers and MVPs relating to BizTalk 2009 and Visual Studio 2008. It was also know as the ’copy local’ issue because usually toggling the copy local setting of the referenced project under References would fix the […]
by community-syndication | Jan 24, 2010 | BizTalk Community Blogs via Syndication
[In addition to blogging, I am also now using Twitter for quick updates and to share links. Follow me at: twitter.com/scottgu]
Technical debates are discussed endlessly within the blog-o-sphere/twitter-verse, and they range across every developer community. Each language, framework, tool, and platform inevitably has at least a few going on at any particular point in time.
Below are a few observations I’ve made over the years about technical debates in general, as well as some comments about some of the recent discussions I’ve seen recently about the topic of ASP.NET Web Forms and ASP.NET MVC in particular.
General Observations About Technical Debates
Below are a few general observations independent of any specific technical debate:
a) Developers love to passionately debate and compare languages, frameworks, APIs, and tools. This is true in every programming community (.NET, Java, PHP, C++, Ruby, Python, etc). I think you can view these types of religious technical debates in two ways:
- They are sometimes annoying and often a waste of time.
- They are often a sign of a healthy and active community (since passion means people care deeply on both sides of a debate, and is far better than apathy).
Personally I think both points are true.
b) There is never only “one right way” to develop something. As an opening interview question I sometimes ask people to sort an array of numbers in the most efficient way they can. Most people don’t do well with it. This is usually not because they don’t know sort algorithms, but rather because they never think to ask the scenarios and requirements behind it – which is critical to understanding the most efficient way to do it. How big is the sequence of numbers? How random is the typical number sequence (is it sometimes already mostly sorted, how big is the spread of numbers, are the numbers all unique, do duplicates cluster together)? How parallel is the computer architecture? Can you allocate memory as part of the sort or must it be constant? Etc. These are important questions to ask because the most efficient and optimal way to sort an array of numbers depends on understanding the answers.
Whenever people assert that there is only “one right way” to a programming problem they are almost always assuming a fixed set of requirements/scenarios/inputs – which is rarely optimal for every scenario or every developer. And to state the obvious – most problems in programming are far more complex than sorting an array of numbers.
c) Great developers using bad tools/frameworks can make great apps. Bad developers using great tools/frameworks can make bad apps. Be very careful about making broad assumptions (good or bad) about the quality of the app you are building based on the tools/frameworks used.
d) Developers (good and bad) can grow stronger by stretching themselves and learning new ideas and approaches. Even if they ultimately don’t use something new directly, the act of learning it can sharpen them in positive ways.
e) Change is constant in the technology industry. Change can be scary. Whether you get overwhelmed by change, though, ultimately comes down to whether you let yourself be overwhelmed. Don’t stress about having to stop and suddenly learn a bunch of new things – rarely do you have to. The best approach to avoid being overwhelmed is to be pragmatic, stay reasonably informed about a broad set of things at a high-level (not just technologies and tools but also methodologies), and have the confidence to know that if it is important to learn a new technology, then your existing development skills will mostly transition and help. Syntax and APIs are rarely the most important thing anyway when it comes to development – problem solving, customer empathy/engagement, and the ability to stay focused and disciplined on a project are much more valuable.
f) Some guidance I occasionally give people on my team when working and communicating with others:
- You will rarely win a debate with someone by telling them that they are stupid – no matter how well intentioned or eloquent your explanation of their IQ problems might be.
- There will always be someone somewhere in the world who is smarter than you – don’t always assume that they aren’t in the room with you.
- People you interact with too often forget the praise you give them, and too often remember a past insult - so be judicious in handing them out as they come back to haunt you later.
- People can and do change their minds – be open to being persuaded in a debate, and neither gloat nor hold it against someone else if they also change their minds.
g) I always find it somewhat ironic when I hear people complain about programming abstractions not being good. Especially when these complaints are published via blogs – whose content is displayed using HTML, is styled with CSS, made interactive with JavaScript, transported over the wire using HTTP, and implemented on the server with apps written in higher-level languages, using object oriented garbage collected frameworks, running on top of either interpreted or JIT-compiled byte code runtimes, and which ultimately store the blog content and comments in relational databases ultimately accessed via SQL query strings. All of this running within a VM on a hosted server – with the OS within the VM partitioning memory across kernel and user mode process boundaries, scheduling work using threads, raising device events using signals, and using an abstract storage API fo disk persistence. It is worth keeping all of that in mind the next time you are reading a “ORM vs Stored Procedures” or “server controls – good/bad?” post. The more interesting debates are about what the best abstractions are for a particular problem.
h) The history of programming debates is one long infinite loop – with most programming ideas having been solved multiple times before. And for what it’s worth – many of the problems we debate today were long ago solved with LISP and Smalltalk. Ironically, despite pioneering a number of things quite elegantly, these two languages tend not be used much anymore. Go figure.
Some Comments Specific to ASP.NET Web Forms / ASP.NET MVC debates:
Below are a few comments specific to some of the recent debates that I’ve seen going around within the community as to whether a ASP.NET Web Forms or ASP.NET MVC based approach is best:
a) Web Forms and MVC are two approaches for building ASP.NET apps. They are both good choices. Each can be the “best choice” for a particular solution depending on the requirements of the application and the background of the team members involved. You can build great apps with either. You can build bad apps with either. You are not a good or bad developer depending on what you choose. You can be absolutely great or worthless using both.
b) The ASP.NET and Visual Studio teams are investing heavily in both Web Forms and MVC. Neither is going away. Both have major releases coming in the months ahead. ASP.NET 4 includes major updates to Web Forms (clean ClientIDs and CSS based markup output, smaller ViewState, URL Routing, new data and charting controls, new dynamic data features, new SEO APIs, new VS designer and project improvements, etc, etc). ASP.NET 4 will also ship with ASP.NET MVC 2 which also includes major updates (strongly typed helpers, model validation, areas, better scaffolding, Async support, more helper APIs, etc, etc). Don’t angst about either being a dead-end or something you have to change to. I suspect that long after we are all dead and gone there will be servers somewhere on the Internet still running both ASP.NET Web Forms and ASP.NET MVC based apps.
c) Web Forms and MVC share far more code/infrastructure/APIs than anyone on either side of any debate about them ever mentions – Authentication, Authorization, Membership, Roles, URL Routing, Caching, Session State, Profiles, Configuration, Compilation, .aspx pages, .master files, .ascx files, Global.asax, Request/Response/Cookie APIs, Health Monitoring, Process Model, Tracing, Deployment, AJAX, etc, etc, etc. All of that common stuff you learn is equally valid regardless of how you construct your UI. Going forward we’ll continue to invest heavily in building core ASP.NET features that work for both Web Forms and MVC (like the URL Routing, Deployment, Output Caching, and DataAnnotations for Validation features we are adding with ASP.NET 4).
d) I often find debates around programming model appropriateness and abstractions a little silly. Both Web Forms and MVC are programming web framework abstractions, built on top of a broader framework abstraction, programmed with higher level programming languages, running on top of a execution engine abstraction that itself is running on top of a giant abstraction called an OS. What you are creating with each is HTML/CSS/JavaScript (all abstractions persisted as text, transmitted over HTTP – another higher level protocol abstraction).
The interesting question to debate is not whether abstractions are good or not – but rather which abstractions feels most natural to you, and which map best to the requirements/scenarios/developers of your project.
e) We are about to do a pretty major update to the www.asp.net site. As part of that we will be posting more end to end tutorials/content (for both Web Forms and MVC). We will also be providing tutorials and guidance that will help developers quickly evaluate both the Web Forms and MVC approach, easily learn the basics about how both work, and quickly determine which one feels best for them to use. This will make it easy for developers new to ASP.NET, as well as developers who already know either Web Forms or MVC, to understand and evaluate the two approaches and decide which they want to use.
f) Decide on a project about whether you want to use Web Forms or MVC and feel good about it. Both can be good choices. Respect the choices other people make – the choice they have made is also hopefully a good one that works well for them. Keep in mind that in all likelihood they know a lot more about their own business/skills than you do. Likewise you hopefully know a lot more about your own business/skills than they do.
g) Share ideas and best practices with others. That is a big part of what blogs, forums, listservs and community is all about. What makes them work great is when people know that their ideas aren’t going to be ripped to shreds, and that they will be treated with respect. Be constructive, not snarky. Teach, don’t lecture. Remember there is always someone else out there who you can also learn from.
Hope this helps,
Scott
by community-syndication | Jan 24, 2010 | BizTalk Community Blogs via Syndication
I started this week at WPC Services. They specialize in providing business and technical consulting services for healthcare organizations. Initially I’ll be doing systems integration architecture.
by community-syndication | Jan 24, 2010 | BizTalk Community Blogs via Syndication
In a previous post, I wrote about how to extend the reach of an ESB on-ramp to Windows Azure platform AppFabric ServiceBus. This same technique also works for any BizTalk receive location, as what makes it an ESB on-ramp is the presence of a pipeline that includes some of the itinerary selection and processing components from the ESB Toolkit. In that post (and accompanying video) I showed how to use InfoPath as a client to submit the message to the ServiceBus, which subsequently got relayed down and into a SharePoint-based ESB-driven BizTalk-powered workflow.
In this and the next post, we’ll look at how to send messages in the other direction, and in this post, I’ll show how to do it using a BizTalk dynamic send port. If you’re used dynamic send ports with BizTalk, you’ll know they’re a powerful construct that let you programmatically sent endpoint configuration information that will subsequently be provided to a send adapter. This is a great way to have a single outbound port that can deliver messages to a variety of endpoints. And, dynamic ports are a key concept behind ESB off-ramps, but more on that later.
The video to go along with this post can be found here.
The sequence used here is:
- Message is picked up from a file drop (because that’s how most BizTalk demos start:))
- A BizTalk orchestration bound to that receive port is instantiated
- The orchestration (in an expression shape) sets properties the adapter will use
- The message goes to the dynamic send port and is dispatched
- The message is retrieved by the receive location I wrote about in my previous post
- A send port has a filter set to pick up messages received by that receive port, and persists the file to disk
The last two steps are not covered here, but are shown in the video.
Our orchestration is proof-of-concept simple, as you may have expected:
In our message assignment shape, first we create and work with the message:
Then, because the outbound port in our orchestration is a dynamic port, we set a couple of properties on that:
And. THAT’S IT!!!!! That is all we have to do in order for BizTalk to send a message to the Azure platform AppFabric ServiceBus. As you can see from the behavior specified, this is a secured channel (in this case I am using “shared secret”). The actual security part of this is provided with the Windows Azure platform AppFabric Access Control Service, which is tightly integrated with the ServiceBus.
Note the value of the WCF.BindingType (netTcpRlayBinding). This is just one of the ServiceBus-related bindings you get when you install the Azure platform AppFabric SDK. This particular binding is high performance .NET-to-.NET, but requires TCP/IP ports be open, which could be an issue depending on your network.
I’ve always loved the flexibility that the WCF-Custom adapter provides, and here is yet another example. Another team issues an SDK well after the current release of BizTalk, and because we’re all leveraging WCF it makes it trivial for us to take advantage of the new capabilities.
The next post and video in this series will show how to provide message sending capabilities using the components provided with the ESB Toolkit. Stay tuned.
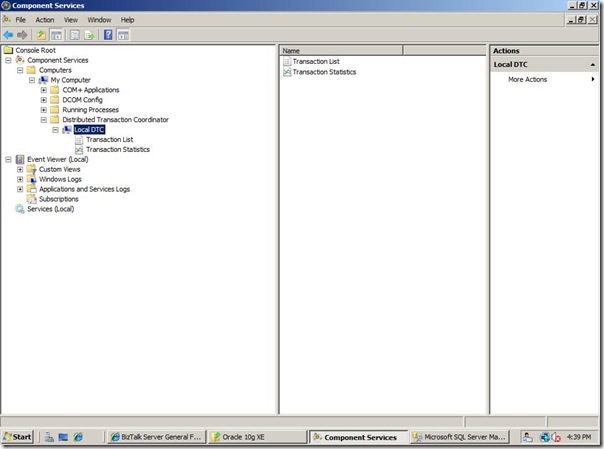
by community-syndication | Jan 23, 2010 | BizTalk Community Blogs via Syndication
Microsoft Distributed Transaction Coordinator (MSDTC) is an important component in a BizTalk environment. Especially in multi-server environment it is mandatory and needs to setup and configured properly before one starts configuring BizTalk features like group, BRE or BAM. During configuration of these BizTalk features, databases like BizTalkMsgBoxDb, BizTalkMgmtDb, BizTalkDTADb (tracking archiving), BizTalkRuleEngineDb, or BAMPrimairyImport and other (BAMStar, ect) are created on database server. MSDTC is component inside Component Services (Windows 2003, Windows 2008). Below is a screen from DTC inside Component Services Windows Server 2008.
By right clicking Local DTC you can configure it via three tabs (Tracing, Logging, and Security). To enable MSDTC on Windows Server 2003 or 2008 you can find that on this MSDN page.
Below is a screen from DTC inside Component Services Windows Server 2003.

There are three tabs available and first on is Tracing (this accounts W2K8):

Above screens show default settings (and is first tab shown if you right click local DTC -> Properties). There is an excellent explanation via official Distributed Services Support Team blog that explains what you can do here. Second tab is Logging:

This tab self explanatory I think. The Microsoft Distributed Transaction Coordinator (MS DTC) log file is in the %windir%\system32\Msdtc directory by default. More on choosing where to put log file you can find here. The third tab is the most important one having DTC work properly:

Note: DTC account can be changed, look here how and consider if it is necessary. It can be tricky depending on Operating Systems you are working.
Depending on your Operating System you need to set the following settings (above shows the default settings on Windows 2008).
| Configuration Option |
Default Value W2K3 |
Default Value W2K8 |
Recommended value |
| Network DTC Access |
Enabled |
Enabled |
Enabled |
| Client and Administration |
|
|
|
| Allow Remote Clients |
Disabled |
Disabled |
Disabled |
| Allow Remote Administration |
Enabled |
Disabled |
Disabled |
| Transaction Manager Configuration |
|
|
|
| Allow Inbound |
Enabled |
Enabled |
Enabled |
| Allow Outbound |
Enabled |
Enabled |
Enabled |
| Mutual Authentication Required |
Disabled |
Disabled |
Enabled if all remote machines are running Win2K3 SP1 or XP SP2 or higher. |
| Incoming Caller Authentication Required |
Disabled |
Disabled |
Enabled if running MSDTC on cluster. |
| No Authentication Required |
Disabled |
Disabled |
Enabled if remote machines are pre-Windows Server 2003 SP1 or pre- Windows XP SP2. |
| Enable XA Transaction |
Disabled |
Disabled |
Enabled if communicating with an XA based transactional system such as when communicating with IBM WebSphere MQ using the MQSeries adapter. |
To validate the connection between BizTalk Server and SQL Server machines you can use DTCPing. Also take into consideration that firewall can block access. To configure firewall on W2K3 you can go here and for W2K8 here.
Besides DTCPing there is also a tool called DTCTester. Latter utility is to verify transaction support between two computers, if SQL Server is installed on one of the computers. The DTCTester utility uses ODBC to verify transaction support against a SQL Server database. For more information about DTCTester see How to Use DTCTester Tool. DTCPing is to verify transaction support between two computers, if SQL Server is not installed on either computer. The DTCPing tool must be run on both the client and server computer. For more information about DTCPing, see How to troubleshoot MS DTC firewall issues.
To troubleshoot MSTDC you can also find valuable information at this MSDN page and summary of other useful tools here. I hope that if you are building a multi-server BizTalk environment that this information gathered here can help you setup and configure MSDTC properly before you start configuring BizTalk features.
Technorati: BizTalkBizTalk 2006 R2BizTalk Server 2009
by community-syndication | Jan 22, 2010 | BizTalk Community Blogs via Syndication
I will be doing a brand-new, never-seen-before presentation at the Code Camp in Fullerton next week. I’m late signing up as I wasn’t sure if my schedule would permit it, but it all looks good, so I’ll do it.
The session will encapsulate some of the cool stuff I’ve been doing spanning the two environments. This will be a powerful (and I would say essential) presentation for BizTalk developers as it highlights some of the new patterns we now have at our disposal. However, I this is also an important session for anyone deploying services to Azure and calling them from on premises, as many will not have an integration background and as such will run into the typical pitfalls that experienced integration devs know to avoid.
I’ve done one post about bridging on-premise to Azure here, and there are more videos working their way through MSDN that should be live any time now. Once they go live, I’ll post accompanying blog posts.
I’ll be presenting at 2:45 on Sat Jan 30th. Hope to see you there if you’re attending this Code Camp.
——————–
Title:
Bridging the Gap between On-premise ESB and Windows Azure
Abstract:
Having attained the plateau of productivity, companies worldwide are enjoying the benefits and efficiencies that can be realized through a well-defined and implement SOA strategy. In addition, many are also realizing the business value and agility improvements that come from have an Enterprise Service Bus in place as a messaging backbone to support their SOA infrastructure.
With the recent “go-live” of Microsoft’s Windows Azure platform, intriguing new architectural patterns for distributed applications are being made possible. In this session we will look at what it means to bridge from the on-premise ESB to the Windows Azure platform. In addition, we will cover the value-add that an ESB brings to Azure usage. We will take a pragmatic approach, showing you what can be done today, with the tools available to you right now.
Register at http://www.SoCalCodeCamp.com.
by community-syndication | Jan 22, 2010 | BizTalk Community Blogs via Syndication
by community-syndication | Jan 22, 2010 | BizTalk Community Blogs via Syndication
The second chapter of our WCF Extensibility Guidance Pablo and I authored a few months ago is now available on MSDN . This chapter is one of my favorites given that it touches upon the most common extensibility points of WCF’s client and dispatcher programming…(read more)
by community-syndication | Jan 21, 2010 | BizTalk Community Blogs via Syndication
What does the persistence subsystem do?
The persistence subsystem is responsible for making a workflow instance durable. Durable workflow instances can be unloaded from memory and reloaded on the same or a different machine at a later point in time. This way, the persistence subsystem enables scenarios such as long-running workflow applications, increase system load by unloading idle instance, migration of instances between machines, scale out and load-balancing, and recovery of failed instances.
The persistence subsystem performs the following tasks:
%u00b7 Storing the state of workflow instances in a persistence store.
%u00b7 Recovery of durable workflow instances.
%u00b7 Activation of durable workflow instances with expired durable timers.
%u00b7 Instantaneous reactivation of durable workflow instances after a shutdown or crash of the Workflow Service Host.
Persistence for a workflow is enabled by defining an instance store for the Workflow Service Host. The .NET 4 framework comes with the SQL Workflow Instance Store, which is a SQL Server implementation of an instance store.
When a workflow instance persists, the SQL Workflow Instance Store (SWIS) saves the current instance state into the persistence store together with additional metadata that is required for activation, recovery and control. After the instance is persisted, the Workflow Service Host can unload the instance from memory. At a later point in time the Workflow Service Host may instruct the instance store to load the instance again. For example, the Workflow Service Host will automatically reload the workflow instance when a new message arrives for that instance or if any of the instance’s timers expire.
Persistence is triggered in multiple ways:
%u00b7 Some activities persist the instance. The SendReplyToReceive activityhas a PersistBeforeSend property, which can be set to persist the Workflow state before a reply is sent.
%u00b7 The user defines the Workflow Idle behavior and sets the PersistOnIdle time. When specified the Workflow Service Host persists the instance after the instance has been idle for the specified time. An instance can go idle when it is waiting on a receive or delay activity.
%u00b7 The user defines the Workflow Idle behavior and sets the UnloadOnIdle time. When specified the Workflow Service Host persists and unloads the instance after the instance has been idle for the specified time.
In addition to these mechanisms, the workflow can contain explicit persistence activities. Those explicit persist activities are only required to persist a workflow throughout a long episode of computation or to guarantee that certain well-known persist points are present.
How does the persistence subsystem work?
The persistence subsystem consists of four parts:
1. Persistence Framework API A set of persistent interfaces that define the contract with Workflow Service Host to persists its state. These enable you to build any type of persistence provider from database backed to say distributed in-memory cache.
2. The SQL Workflow Instance Store (SWIS) implements the abstract class InstanceStore of the Persistence Framework API. This class is used by the Workflow Service Host to create, load, save and delete durable instance data.
3. The SQL Server Persistence database stores all the durable instance state. It also stores the additional metadata that is used to activate and recover a service instance.
4. The Workflow Management Service (WMS) is a Windows Service that activates a Workflow Service Host whenever there are unloaded instances with expired durable timers, instances that need to be reactivated after a graceful shutdown or instances that need to be recovered after a crash. The WMS is also involved in the execution of instance control commands, which will be covered in a future blog post.
All workflow instances that are hosted by a Workflow Service Host that configures the SQL Workflow Instance Store save their instance state in the SQL Server Persistence Database. In addition to the instance state binary blob, the persistence store holds the following:
The message correlation key allows the Workflow Service Host to correlate an incoming message to a service instance if that instance is not loaded.
The instance lock indicates whether the service instance is loaded.
The service deployment information defines how the service is deployed in a IIS/WAS-hosted environment. It consists of site name, application path, service path and service name. Note that the instance store does not contain any deployment information for self-hosted workflows, meaning that the WMS is specifically tailored for IIS hosted services.
Loading and locking
If a workflow instance is loaded by a Workflow Service Host the persistence store locks that instance, and the instance cannot be loaded by any other service host. If the service host unloads the service instance the lock is released, and the instance can be loaded by a different service host. The new service host may reside on a different machine. This means that a workflow instance can run on multiple machines throughout its lifetime, whenever activation messages arrive. It also means that you can build a machine farm without employing an intelligent message router that remembers which machine is running a particular workflow instance. Instead, the router routes a message to any of the machines in the farm. If the message is correlated to an existing workflow instance, the instance will be loaded by that machine. Casually speaking, the service instance follows the message.
Processing of expired timers
If a workflow instance is executing a delay activity at the time it persists the instance store stores the expiration time of the activity. At the time the activity expires the SQL Workflow Instance Store notifies the Workflow Service Host, which then loads the workflow instance and processes the expired delay activity. If multiple machines are available, the instance may be loaded on any of these machines.
If no Workflow Service Host is running on a particular machine the WMS will activate a host on that machine. This causes the instances of a particular workflow type to be distributed among all machines in the farm.
Instance recovery
If a service host has loaded a workflow instance the Workflow Service Host must renew the instance’s lock on a regular basis. If not renewed on time, the lock expires. An expired lock indicates that the service host or the machine the service host ran on has crashed. In this case another Workflow Service Host will load the instance. If no other Workflow Service Host is running the WMS will activate a host.
If the Workflow Service Host shuts down (e.g., due to an app domain recycle) it releases the locks of all the service instances it has loaded.




