by Nick Hauenstein | Jul 7, 2015 | BizTalk Community Blogs via Syndication
Earlier this week, I was revisiting a design for a Logic App that interacted with an event about a business entity that was represented as an XML message. It used data from this XML message to invoke actions later in the process, and relied on the XPath Extractor API App to provide access to the data contained within the XML. It looked something like this:
At the time, the choice to use XPath Extractor API Apps was an alright choice, given that there weren’t really any alternative API Apps in the marketplace that allowed one to cross the XML / JSON divide – JSON being the native tongue of Logic Apps. That has since changed, and upon revisiting the design, it became apparent that using the XPath Extractor was a poor choice.
I wasn’t doing anything complex (e.g., selecting the text inside an element only when that element had an attribute with a specific value and appeared nested inside an element beginning with a certain set of characters), I was just trying to retrieve the values stored within scalar elements within the same location in the XML document each time – elements that I would have simply treated as distinguished fields in BizTalk Server and happily dotted into while editing an expression.
Despite not doing something complex, the original design was using 3 separate API App executions just to read 3 separate values. That seems a little bit wasteful for something that the Logic App runtime would give me for free with JSON data.
Using the Right Tool to Bridge the XML / JSON Divide
So what API App was added into the mix since the original plan for this Logic App? The BizTalk JSON Encoder API App – which provides translation from/to XML/JSON.
It accomplishes this in a similar way to BizTalk Server’s own JSON Encoder / JSON Decoder pipeline components, and like those components also requires an XML schema in order to perform the conversion from JSON to XML. The schema can be written by hand, generated from JSON in the Azure Portal, generated from a Flat-file in the Azure Portal, or created using Visual Studio 2012 with the MABS SDK.
Once you have your schema, you can use the Components tile of the JSONEncoder API App within the Azure Portal to access an interface to upload and provide a name for the schema.
In the case of XML to JSON, the conversion can occur with or without a schema (i.e., a schema isn’t going to be used, but it won’t hurt anything if you upload one either).
Doing Simple Things with Simple Data
So how do we do something simple (e.g., access a few fields) with simple data? Thankfully, the answer is quite easily. First off, you will need to create an instance of the BizTalk JSON Encoder API App. This instance can be re-used for any XML to JSON conversions that you will require. Converting back to XML from JSON assumes that you have created the requisite schemas and uploaded them for the instance. One downside here is that you cannot share schemas between instances (as they are stored in local storage for the API App on the Gateway).
Once you have the API App, you can feed it any arbitrary XML payload and it will provide a nice JSON representation that you can dot into for any later actions in a Logic App. Unfortunately, its flexibility comes at the cost of rich metadata describing the shape of the output (i.e., the designer won’t be able to help you know which nodes will actually exist in the output, regardless of potentially having a schema available).
So let’s make it happen. I have an event about a business entity (product) that looks something like this as XML:
Let’s say that I want to retrieve the ProductName out of this message. In that case, the expression within a Logic App to retrieve the value would look something like this:
@body(‘jsonencoder’).OutputJSON.ProductEvent.ProductName
If the Remove Outer Envelope property on the BizTalk JSON Encoder API App was set to true, then it would look like this instead:
@body(‘jsonencoder’).OutputJSON.ProductName
As shown in the screenshot above, neither of these expressions are going to show up within my nice little drop-down list of values to select. Instead, I must dot into it in trust that it will be there. But how can we be a little bit more sure? We could couple it with an XML Validator, or add a condition on the action based on the logical existence of the node.
Does the simple case work though? Well, after updating the expression:
And then submitting the sample message to the source queue, this was the input/output set of the BizTalk JSON Encoder:
And this was the data that showed up in the request bin:
What If I Have More Complex Data?
What if the data that I have isn’t just a bunch of text in elements, but I have a complex structure with repeating nodes and attribute values? To find out, I loaded up the sample message with some sample data to see.
Running that through the JSON Encoder, I saw this output:
Attributes are represented as properties prefixed with @ and the text included in a node is represented as the value of a property named #text. Repeating nodes are collapsed into an array sharing the name of the node name – perfect for repeating an action against.
Then, When Is the XPath Extractor the Right Answer?
Simple data or complex data might not be the determining factor in the choice between using the XPath Extractor or JSON Encoder API Apps to access data locked up in an XML message. Instead, it looks like the determining factor is how hard it is to describe where that data lives (or doesn’t live) within the content. In all the cases we’ve seen thus far, we referenced by name / location in the document. XPath will shine when we don’t have that information, or when we want information about the content in the document, and as such still deserves a place in the toolbox.
However, just because you’re trying to get data out of XML, and all previous knowledge points to XPath as the answer, it might not be – instead, the answer might be to translate that message into the native tongue of the runtime that’s interacting with it.
What’s Next?
I currently owe all of you readers out there a post about push triggers. I have most of it written, but I’m not yet fully pleased with it. I’ll try to get that out as soon as possible. Additionally, there’s another post that I’m even more excited about, one that I’ve been thinking about for the last 3 years. I’m likely going to be posting that one shortly after WPC.
Stay tuned. There’s heaps that I want to share, but, alas, the constraints of the solar day and the capacity of my human flesh prevent it from happening all at once.
by Nick Hauenstein | May 1, 2015 | BizTalk Community Blogs via Syndication
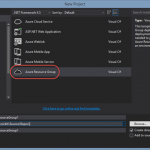
As shown today in Ilya Grebnov, and Stephen Siciliano’s Build 2015 Session titled simply “Logic Apps”, there is now (as of the 29th actually) a nice project template for creating a deployment project containing a Logic App with separate per-environment parameters files. The deployment project is really scoped higher than the Logic App itself, it is instead a definition for an Azure Resource Group to be provisioned by Azure Resource Manager.
Selecting the project template (found in the Cloud category as Azure Resouce Group) launches a dialog asking for the type of resource(s) that you would like the resource group project to start with. There are two resource types that include Logic Apps: Logic App, and Logic App and API App.
Once created, the project (like any other Cloud Deployment Project up to this point) contains a PowerShell script to perform the actual deployment, along with a helper executable named AzCopy.exe. However, in addition to that, we not only get a file describing the deployment of an App Service Plan, Gateway, API App, and Logic App, we also get a parameters file — initially for a dev environment, but it is a step in the right direction and shows how to make it happen.
How do we know that this parameters file will be used? Well the parameters file itself is actually a parameter within the Deploy-AzureResourceGroup.ps1 deployment script, and the default is to use dev:
Inside, you will find the parameters apiAppName, gatewayName, logicAppName, and svcPlanName.
The definition for the Logic App itself is contained deep within the LogicAppAndAPIApp.json file (starting around line 271 in my test shown here):
It consists of a recurrence trigger (polling very hour) that invokes an operation with id of getValues on the deployed API App and outputs an array containing the value of the readValues property on the body of the API App response. I guess that’s the “Hello World” of the Logic App world, eh?
Code where Code Belongs
This represents a big step in the right direction for the team building Logic Apps. It’s putting code where code belongs, in the best IDE ever made and backed by proper source control. It also cleanly separates logic and configuration, enabling multiple environments.
However, without a visual editor, and an/or an quick/easy way to resolve API App ids from the marketplace, it’s going to be tough to build more complex flows in this fashion. I would also like to see the deployment spread across files. Imagine a resource group with multiple Logic Apps (a receive pipeline style Logic App, a process orchestration-style Logic App and a send pipeline style Logic App), working with that in one giant file would be a little bit painful.
In theory, there is a concept of a definitionLink to the body of the workflow itself (so as to not include it directly within the deployment script), but that’s not what the project template will give you:
That’s All From Build
I know that I wrote a lot for each of the major BizTalk events over the last 6 months, but for Build 2015, I’m going to keep it short and sweet and to the point. I’m juggling a lot of really cool things right now that I’m excited to share with you as soon as they’re ready. So stay tuned!
As a side note, BizTalk Server on-premise is going to be getting some love over the next year as well. Another major version is in the works, and you’d better bet that I’m going to be all over that as well.

by Nick Hauenstein | Apr 26, 2015 | BizTalk Community Blogs via Syndication
In my first article recapping the BizTalk Summit 2015, I said I would revisit the topic of triggers for those of you wanting to build out custom API Apps that implemented either of those patterns.
After working through the official docs, and reviewing the code presented at the BizTalk Summit 2015 in anticipation of our upcoming Cloud-Based Integration Using Azure App Service class, I decided to take a little bit of a different direction.
Rather than do a write-up both here, and in hands-on-lab form within the class of writing a bunch of custom Swashbuckle operation filters for generating the appropriate metadata for a Logic App to properly consume an API App that’s trying to be a trigger, I decided to write up a library that just made it a little bit easier to create custom API Apps that are consumable from the Logic App designer.
How did I go about doing that? Well Sameer Chabungbam had mentioned in his presentation that a more elegant solution might be to use attributes for friendly names and the like. So I went in that direction, and made attributes for all of the stuff that the Logic App designer needs to have in a certain way (really anything that involved vendor extensions in the generated swagger). What do we do with all of those attributes? Well, we uh, read them in custom operation / schema filters of course! So yes, I did have to write some custom filters after all, but now you don’t have to!
Announcing QuickLearn’s T-Rex Metadata Library
I rolled all of the code into a library that I’ve named the T-Rex Metadata Library1. The library is available as a NuGet package as well that you can add directly to your API App projects within Visual Studio 2013.
So how can we use that to make custom triggers? I’m glad you asked. Let’s get right into it.
Creating Custom Polling Triggers
The easiest kind of trigger to implement is a polling trigger. A polling trigger is polled by a Logic App at a set polling interval, and is asked for data. When the trigger has data available, it is supposed to return a 200 OK status with the data contained in the response body. When there is not data available, a 202 Accepted status should be returned with an empty response body.
You can find an example of a polling trigger over here. This polling trigger takes in a single configuration parameter named “divisor” and when polled will return data if and only if the current minute is evenly divisible by the divisor specified (kind of silly, I know).
So, how do I separate sample from reality and actually build one?
Steps for Creating a Polling Trigger
- Create a new project in Visual Studio using the Web Application template
- Choose API App (Preview) as the type of Web Application you are creating
- Add the TRex NuGet package to your project
- In the SwaggerConfig.cs file, add a using directive for TRex.Metadata
- In the SwaggerConfig.cs file, just after the line showing how to use the c.SingleApiVersion add a line that reads c.ReleaseTheTRex();
- Add using directives for the Microsoft.Azure.AppService.ApiApps.Service, and TRex.Metadata namespaces.
- Microsoft.Azure.AppService.ApiApps.Service provides the EventWaitPoll andEventTriggered extension methods
- TRex.Metadata provides the T-Rex Metadata attribute, and the Trigger attribute
- Create an action that returns an HttpResponseMessage
- Decorate the action with the HttpGet attribute
- Decorate the action with the Metadata attribute and provide a friendly name, and description, for your polling action
- Decorate the action with the Trigger attribute passing the argument TriggerType.Poll to the constructor, as well as the type of model that will be sent when data is available (e.g.,typeof(MyModelClassHere))
- Make sure the action has a string parameter named triggerState
- This is a value that you can populate and pass back whenever polling data is returned to the Logic App, and the Logic App will send it back to you on the next poll (e.g., to let you know that it is finished with the last item sent)
- You do not need to decorate this parameter with any attributes. T-Rex looks for this property by name and automatically applies the correct metadata (friendly name, description, visibility, and default value)
- Optionally, add any other parameters that controls how it should poll (e.g., file name mask, warning temperature, target heart rate, etc…)
- Decorate these parameters with the Metadata attribute to control their friendly names, descriptions, and visibility settings
- Make sure that the action returns the value generated by calling Request.EventWaitPoll when no data is available
- You can also provide a hint to the Logic App as to a proper polling interval for the next request (if you anticipate data available at a certain time)
- You can also provide a triggerState value that you want the Logic App to send to you on the next poll
- Make sure that the action returns the value generated by calling Request.EventTriggered when data is available
- The first argument should be the data to be returned to the Logic App, followed by the newtriggerState value that you want to receive on the next poll, and optionally a new polling interval for the next request (if you anticipate data available at a certain time, or more likely that you know more data is immediately available and there isn’t a need to wait).
After you publish your API App, you should be able to use it as a trigger in a Logic App. Here’s what the sample looks like after being deployed:
Next Up
In my next post, I’ll turn my focus to custom push triggers. For now though, I need to rest a little bit to get ready for 2 days of teaching followed immediately by Build 2015! It’s going to a long, yet quite fun week this week!
Until next week, take care!
1It was named this so that it would comply with the latest trends of fanciful library names, and so that I could justify naming a method ReleaseTheTRex. If you believe the name too unprofessional, let me know and I may add a TRex.Enterprise.Extensions namespace that includes a more professional sounding method name which simply calls into the former.

by Nick Hauenstein | Apr 22, 2015 | BizTalk Community Blogs via Syndication
After a relaxing 9-hour flight on a surprisingly empty plane, and a week to re-adjust to the UTC-0700 time zone, I am finally back home in the Pacific Northwest of the United States and ready to record all of the happenings of Day 2 of the BizTalk Summit in London. This post has been delayed as I have been without my Surface Pro since arriving home — the power adapter was destroyed in transit.
If you haven’t already read codit’s write-up of day 2, I highly recommend giving that a read as well so that you can get a few different perspectives.
Hybrid Integration with BizTalk Server 2013 R2
The morning started off with back-to-back sessions from fellow Integration MVPs, beginning with Steef-Jan Wiggers who demonstrated how BizTalk Server 2013 R2 can be used to implement hybrid integration solutions (without relying on things that are currently in preview).
To get a flavor of his demo, you can check out his sample code here, and a wiki write-up over here. Ultimately, his session was a refreshing look at how we can deal with present challenges using presently available software.
I stole this image from the BizTalk 360 photo stream on Facebook because it looked really serious and epic, until you catch the background. It just goes to show that a good sense of humor really is something to be treasured when dealing with the insane world of integration.
From 17 Seconds to Sub-Second Processing with BizTalk Server
Johan Hedberg took the stage next to walk through how he was able to take one integration from 17s all the way down to 0.95s, and how one might apply the same optimizations.
The optimizations that he applied were:
- Reduce MsgBox hops (Call Orchestration vs. Send shape where possible) to provide a 7s improvement
- Consider your Level/Layer of re-use (Avoid calling BizTalk process through external interface, and round-trip through send/receive port) to provide a 5s improvement
- Use Caching to provide a 0.6s improvement
- Optimize your logical flow (respond to caller as soon as you can, potentially before all work is done) to provide a 0.6s improvement
- Consider your Host Settings (specifically reducing the polling interval from 500ms to 50ms) to provide a 1.6s improvement
- Inline Sends (using code to send the message, rather than routing to send port) to provide a 0.3s improvement [Although, I’m personally not sure that it’s worth the cost of giving up everything a Send Port gives you most of the time, so use with caution)
- Optimize instrumentation (find out where time is being spent). In this case, he mentioned that he discovered a database call being made where indexes weren’t being fully utilized. No sense doing a table scan where an index scan will do. Use the index Luke! This provided a 0.9s improvement
- Optimize persistence points, providing a 0.05s improvement at this point.
I really enjoyed his talk, mainly because I’ve been through these things while beating integrations into shape to eek out the last little bit of raw performance, and it was nice to see the process all laid out and broken down in terms of numbers gained at each step.
If you want to see the talk for yourself, he gave the talk again as part of an #IntegrationMonday talk.
Sandro Pereira Annoys Tord
Sandro was up next with a list of tips for both BizTalk Server Administrators and BizTalk Server Developers. Here’s the list:
Tip #1 – Trying to annoy Tord: PowerShell!
Sandro started by weaving a tale involving famed commercial actor turned BizTalk Administrator Tord Glad Nordahl. In this tale, a developer unwittingly annoyed their BizTalk Administrator with mindless EventLog entries written out for every single event and action that occurred during normal processing. Rather than requiring code to change, or bad habits to die, the smart BizTalk Administrator used PowerShell to clean up and redirect the entries to a dedicated log. The script behind the legend is now available for download.
Tip #2 – What RosettaNet, ESB, and UDDI have in common?
They’re backed by databases that aren’t backed up by default. The second tip is then to ensure that these are included in your BizTalk backups.
Tip #3 – BizTalk MarkLog Tables
By default, every 15 minutes a string is stored in the table. Microsoft Terminator tool helps curb the growth within these tables, but requires stopping your entire environment. The solution here is a custom stored procedure to handle all of the clean-up work
Tip #4 – WCF-SAP Adapter supports 64-bit?
Yes. Just make sure that you install all the pre-reqs correctly, and you’ll be set.
Tip #5 – Take control of your environment: Tracking Data
If, as an administrator, you’re receiving MSI packages from your developers with full tracking enabled all over the place within the application, don’t fret, but instead take control of your environment by automating the tracking settings (again using PowerShell).
Tip #6,7 – Single Pipeline for Debatch/XML Validation/FF Encode
To combine tips 6 and 7, if you’re doing XML Validation, XML Debatching, FF Decoding, etc… You may not need to create a pipeline per-message type. Instead creating a generic pipeline and setting the properties in the BizTalk Server Administration console (rather than inside Visual Studio) can save you some heartache and suffering.
Tip #8 – Request-Response CBR with LOB operations
You don’t need orchestrations to use LOB Adapters (but you do need to promote BTS.Operation property for action mapping on the send side). One thing that I liked here, was that rather than creating a pipeline component that by code or configuration “hard-coded” an action in for the BTS.Operation, the solution presented guessed it from the root node of the message – pretty smart.
This is actually one of the things that I used to demo in the BizTalk Server Developer Immersion class if the question was ever posed, and one of the things that is now directly included as part of the core materials for the BizTalk Server Developer Deep Dive class. Yes, I am being shameless with those plugs, because I love our new Deep Dive class.
This is one of those things that provides a real Take the Red Pill moment when you show it to a BizTalk Developer who has been doing it the hard way for a few years.
Tip #9 – Creating custom pipeline components
Here is where my notes start to break down. I typed “custom pipeline components” but what follows are notes about custom functoid development. So either I missed a tip, or I mistyped. I will retain it as written here, and leave it up for you to determine.
So what was the tip in my notes? If you’re building out a custom functoid (see what I mean?), create custom inline functoids whenever possible. This will avoid the need to deploy a bunch of runtime artifacts, since the script itself is inlined in the map. Beautiful, and excellent tip with which to end the talk.
Tord Will Not Be Shaken… By Power BI
Tord was next to the stage for his 30 minute tour of Power BI. I think he introduced it in the right way – at least I felt like it addressed where I was at with the technology. I’ve always been scared of BI, probably unnecessarily – ever since that defining moment as a young developer being exposed to the horror that was a raw, naked, MDX query. When I saw Power BI demoed for the first time, it looked amazing and absolutely incredible – with MDX queries hidden behind plain English, pretty graphs leaping off of dash boards. It looked great. Because it looked great, and computers aren’t really magic, that must mean that there is hard work and lots of technologies to learn behind the scenes, right?
That was the angle that Tord took, as even he was looking at it skeptically, thinking there was going to be a lot of stuff to learn just to get started. However, during his talk, he proved that this wasn’t the case, and showed just how easy it really can be to get up and running with Power BI.
So where’s the BizTalk tie-in? He was using Power BI against data gathered by BAM, because it really is just data in a database at the end of the day. A really beautiful way to tie it all together (and certainly more modern looking than the BAM portal).
Since I’ve bulleted pointed everything else, here’s some bullet points for you on Power BI (really selling points when it comes down to it):
- Free access to Power BI designer
- Easy to use web interface
- Works on any platform
- Loved by management
- Like Azure Services, it’s cheap (10 USD per month, per user)
On the Origin of Microservices – Charles Young Connects Past to Present
For me it’s a personal treat to be able to hear Charles Young speak, and luckily I got the opportunity at the 2015 BizTalk Summit in London. He’s the Donald Knuth of EAI, and always serves to bring the larger picture to developers (myself included) who tend to have myopic tendencies driven by the lust for shiny things.
So how would he introduce himself? “I am an EAI dinosaur. I’ve been doing it for years, and years, and years, and we either evolve, or obviously we atrophy or whatever”. Of course, we all know what whatever is. Poor dinos (except for the raptors in Jurassic Park – they had it coming).
His talk walked through the evolution from n-tier architectures of the 90’s to Alistair Cockburn’s Hexagonal Architecture (to which BizTalk Server closely aligns, and shares terminology with, though pre-dating the architecture), all the way through Microservices Architecture.
He saw as driving forces of this evolution the aspiration for:
- Simplicity in addressing complex requirements
- Velocity (speed of delivering solutions)
- Evolution (see above)
- Democratization
On Microservices, “[they are] essentially based very consciously on hexagonal architecture. It’s the idea of taking your application domain and ensuring that the way you implement services within the application domain are very fine grained […]. Microservice principles are based on the notion that the services that we tended to build in the middle tier have tended to be monolithic, which isn’t quite exactly what is being built, but in terms of how it is packaged and hosted, maybe. There’s a lot of chunky services that cover lots of concerns which can be problematic. The idea is to decompose the monolith into fine grained services […]. [It is] the new new fine grained SOA approach for a modern audience. But just because Microservices is the new buzzword doesn’t mean that we should leave our brain at the door and forget what we know about building complex integrations”
As he expanded out to iPaaS and Microservices, he mentioned that he has a problem with most of the iPaaS platforms today (e.g., MABS), where the full integration / mediation workflow is emitted up to the cloud as a monolithic thing which makes no proper separation of concerns (e.g., Itinerary containing a bridge with VETR flow). However, with App Service, he sees a change of direction in which we don’t have to use Logic Apps, for example, to use API Apps – the capabilities are no longer tightly coupled to the workflow.
I must admit, his session was so packed full of essential and incredible content, that I was unable to take notes fast enough to capture it all. He doesn’t waste a lot of words, and still succeeds to use lots of them.
If you want a better view into his brain right now, as he’s processing the change in the industry, read through his latest series of posts on architecture (Part 1, Part 2, Part 3).
Announcing The Migration Factory
Next up was Jon Fancy and Dan Probert, to completely blow my mind. At first, it seemed that their talk was going to be providing tips to migrate BizTalk solutions to Azure App Service. Instead they announced that they had created an automated service to do just that.
I thought it was a joke. I thought they were going to have a fake announcement, and then resolve it with, “of course, automated migration will never be possible, so here’s a checklist that you will need to manually go through”. But this was not the case. Indeed, they were announcing, and DEMONSTRATED a working migration service that was able to take a BizTalk Server application and migrate it over to Logic App form on Azure App Service. Good show!
I was so thrown off by this that I couldn’t get my camera up fast enough and ended up with some wonderful candid pictures of my shirt, my shoes, and the floor.
Best of all, you can sign-up today. I’m still in shock over this one.
API Management with Kent Weare and Tomasso Groenendijk
The next set of talks were a coordinated effort between Kent Weare and Tomasso Groenendijk.
Kent introduced the topic of APIs by showing their power in modern business (e.g., Uber – the largest hired ride company that owns no cars, Facebook – the largest media company that produces no content) to enable the exchange of data which is where the real value lies. He likened APIs to a doorway for your business, which with the help of API Management gets a bouncer. Why a bouncer? Because they handle similar concerns:
- Authentication / authorization
- Policy enforcement
- Analytics
- Engagement
So what’s the Red Pill moment that API Management delivers to a BizTalk Server developer who is keen on exposing BizTalk endpoints directly to end consumers with whatever format the end consumer wants? Of course, we still have to think about security, enrollment, governance, visibility, etc…
Kent followed through with a nice end to end demo of API Management being applied to a car insurance purchasing scenario with a shiny Windows Store app front-end.
Next up was Tomasso.
I always get excited when I see Tomasso, because I know that I’m in the same room as one of the few human beings that shares the same passion for the ESB Toolkit as I. He’s also probably the only person I know who has ever implemented IExtenderStyle (so rare, it’s not even Google-able, though Bing makes an effort) – that shows that he really takes pride in his work.
He demonstrated what it looks like to put API management in front of the ESB Toolkit on-premises, which adds the benefit of message repair thanks to the ESB Exception Management Framework. For an added bonus he demonstrated the message repair being done through the BizTalk360 ESB Portal.
Power BI to replacing the BAM Portal, and BizTalk360 to replacing the ESB Portal demoed in the same day to the same audience? Yes! I’m really looking forward to seeing more modern looking front-ends for BizTalk installations in the wild as a result.
Nino Brings it Home
Nino closed out the conference with his talk on his own personal journey as a developer that led to the thing that is currently eating up his free development time – JitGate.
So how did he get to that point? He started out riding the roller coaster of integration technologies through to the present era (shedding hair and resolve along the way), until he had a realization – what he really wanted out of integration he got from file-based integration:
- Simple to manage
- Fast to use
- Polymorphic
- Adaptable
- Serializable
- Fully extensible
- Persistent
- Multi-platform
- Scalable
- Reliable
From there he set out to use the tools provided by Azure to build out an integration framework that gave him those same benefits. The result was JitGate – Just-in-time integration.
So does this mean he’s announcing an App Service killer? Not necessarily. It means that Azure is an enabler. It has the power as a platform to do integration, and to handle insane loads. You don’t have to use Microsoft’s solution for doing it, you can use the same technologies that they’re using and build your own that is just as capable.
In a way, this is similar to what we had with BizTalk Server – built on top of .NET since 2004. .NET and SQL were always available to any developer who wanted to build something similar to BizTalk.
I don’t want to minimize what Nino has built here though. It is truly impressive and something that sadly, I can’t really capture here. It’s one of those things that you have to see demoed. Stay tuned to his blog for a post with full details and a video of it in action.
What’s Next?
Well it looks like Microsoft has announced Azure Service Fabric, which appears to be a re-branding of Azure Pack and promises to bring the world of Azure App Service on-premises. There are certainly exciting times ahead.
I’ll be at Build 2015 next week in San Francisco, CA to learn all that I can about that, and then the following week will be back in Kirkland, WA teaching the first run of our Cloud-Based Integration Using Azure App Service class.
I hope to see some of you along the way, and if you’re going to the BizTalk Boot Camp 2015 event, y’all better tweet everything so I can get a glimpse of it too!

by Nick Hauenstein | Apr 14, 2015 | BizTalk Community Blogs via Syndication
The first day of the London BizTalk Summit 2015 was a high paced, jammed packed, highly informative, and outstanding1 way to kick-off an event. I sat all the sessions, and ended up with 25 pages of notes, and nearly 200 photos. I have no idea how I’m going to pull this post together in a timely fashion, so I’m just going to dive right in and do what I can.
Service Bus Backed Code-based Orchestration using Durable Task Framework
The morning kicked off with Dan Rosanova delivering his session a little bit early, and in place of Josh Twist’s planned keynote (Josh had taken ill and was unable to make it to the conference). Dan presented the Durable Task Framework – an orchestration engine built on top of Azure Service Bus for durability and the Task Parallel Library for .NET developer happiness.
While not necessarily one of the big new things in the world of BizTalk (i.e., it has been around and doing great since 2013), it is one of those things that allows you to implement some of the same patterns as BizTalk Server, whilst solving some of the same problems that Orchestrations tackle, but with tracing and persistence provided by the cloud, and a design-time experience that feels comfortable to those averse to using mice – pure, real, unadulterated C# code.
The framework provides the following out-of-the-box capabilities:
- Error handling & compensation
- Versioning
- Automatic retries
- Durable timers
- External events
- Diagnostics
That last paragraph is doing the framework a great disservice, and it completely understates the value. Please understand that this is really cool stuff, and one of those things that you just have to see. I’m really happy to have seen the framework featured here, it is definitely now on my list of fun things to experiment with.
I really love Azure Service Bus – it makes me very happy. It’s also making a good showing of Microsoft’s cloud muscle – recently crossing the 500 billion message per month barrier. That’s nuts!
On a side note, I must say that Dan is an excellent presenter, and I would recommend checking out any talk of his that you have the opportunity to hear. POW!
API Apps for IBM Connectivity
Following Dan’s talk, Paul Larsen took the stage to talk about API Apps for IBM Connectivity. Some time was spent recapping the Azure App Service announcement from a few weeks back for those in attendance who were unfamiliar, but then he dove right into it.
The first connector he discussed was the MQ Connector – an API App for connecting applications through Azure App Service to IBM WebSphere MQ server. It can reach all the way on-prem using VPN or Hybrid Connection. The connector uses IBM’s native protocols and formats, while being implemented as a completely custom, fully managed, Microsoft-built client – something that was needed to most efficiently build out the capability given the host. That’s really impressive, especially given the compressed timeline, and complete paradigm shift thrown into the mix. There are some limitations though – compatibility is only for version 8, there is no backwards compatibility yet.
He also took some time to demo the DB2 connector and the Informix connector that are currently in preview, and to present a roadmap that included a TI Connector, TI Service (Host Initialized), DRDA Service (Host Initialized), and of course Host Integration Server v10.
Karandeep Anand Rescues the Keynote
Karandeep Anand, Partner Director of Program Management at Microsoft, flew in from Seattle at the last moment to ensure that the keynote session could still be delivered. He came fresh from the airplane, and started immediately into his talk.
One of the first things he said as he was working through the slides introducing the Azure App Service platform was, “We’re coming to a world where it doesn’t take us 3 years to come out with the next version but 3 weeks to come out with the next feature.” This is so true, and really only fully possible to do with a cloud-based application.
If that statement has you concerned, keep calm. This is something a model that Microsoft has already accomplished on a massive scale with Team Foundation Server. Since the 2012 version of the server product, there has been a mirror of the capabilities in the cloud (first Team Foundation Service, and now Visual Studio Online) providing new features, enhanced functionality, and bug fixes on a 3-week cadence, followed-up by a quarterly release cycle for on-prem.
It’s a model that can definitely work, and I’m excited to see how it might play out on the BizTalk side of things (especially in a micro services architecture where each API App that Microsoft builds is individually versioned and deployed on potentially a per-application basis — not just per-tenant).
It was a model of necessity though when the challenge was issued: “In less than a quarter, we will rebuild our entire integration stack to be aligned with the rest of the app platform.”
Overall, Karandeep did a good job to demonstrate that the Azure App Service offering isn’t just following a new fad, or achieving buzzwords compliance, but instead about learning from past mistakes and applying those learnings.
In discussing the key learnings, there were some interesting things that came out of building BizTalk Services:
- Validated the brand – there is power in the BizTalk brand name, it is synonymous with Integration on the Microsoft platform
- Validated cloud design patterns – MSDTC works on-prem, but doesn’t make a lot of sense in the cloud
- Hybrid is critical and a differentiator
- Feature and capability gaps (esp. around OOTB sources/destinations)
- Pipeline templates, custom code support
- Long running workflows, parallel execution
- Needs a lot more investment
As a result of all of the lessons learned (not just with BizTalk Services), the three guiding principles of building out Azure App Service became: (1) Democratize Integration, (2) Rich Ecosystems, (3) iPaaS Leader.
Shortly after working through the vision, Stephen Siciliano, Sr. Program Manager at Microsoft, and Prashant Kumar came up to assist in demonstrating some of the capabilities provided by the Azure App Service platform.
Stephen’s demo focused on flexing the power of the Logic App engine to compose API Apps and connect to social and SaaS providers (extract tweets on a schedule and write to dropbox, and then looping over the array of tweets rather than only grabbing the first one), while Prashant’s demo demonstrated the use of BizTalk API Apps to handle EAI scenarios in the cloud (calling rules to apply a discount to an XML-based order received at an HTTP location, and then routing the order to a SQL server database).
App Service Intensives Featuring Stephen Siciliano, Prashant Kumar, and Sameer Chabungbam
Right after the keynote, there were three back-to-back sessions (with lunch packed somewhere in between) that provided some raw information download of things that have been out there for discovery, but not yet mentioned directly. I was really pleased with being able to see it live, because it’s going to be awhile before all of the information shown can be documented and disseminated fully by the community.
We’ve been hard at work at QuickLearn on our new Azure App Service class – with the first run just 3 weeks away! For a lot of the conceptual material we’ve relied heavily on the language specification for Logic Apps that was posted not too long ago – trying to understand the capabilities of the engine, rather than the limitations of the designer. So one of the big takeaways for me from Stephen’s session was seeing a lot of those assumptions that we’ve had validated, and then seeing other things pointed out that weren’t as clear at first glance.
Essentially he discussed the expression language (see the language spec for full coverage), the mechanics of triggering a Logic App (see here for full coverage), and the one that stuck out to me: the three ways to introduce dependencies between actions.
Actions aren’t what they seem in the designer (if you follow me on twitter, you would have seen the moment I first learned that thanks to Daniel Probert’s post). They can have complex relationships and dependencies, which can be defined either explicitly or implicitly. The way that Stephen laid it out, I think, was done really well, and certainly sparked my imagination. So here it is, the three ways you can define dependencies for actions:
- Implicitly – whenever you reference the output of an action you’ll depend on that action executing first
- Explicit “dependsOn” condition – you can mark certain actions to run only after previous ones have completed
- Explicit “expression condition – a complex function that evaluates properties of other actions
“expression” (ex: only execute if there was a failure detected / CBR scenarios)
For those that are lost at this point (confused as to why I’m so excited here): If you don’t have a dependency between two steps, they will run in parallel. You can have a fork and rejoin if the rejoined point has a dependency on the last step in both branches. Picture Nino Credele-level happiness, and that’s what you should be feeling right now upon hearing that.
After Stephen left the stage, Prashant Kumar started into his presentation covering BizTalk on App Service. He set the stage by recapping the initial customer feedback on MABS (e.g., more sources/destinations needed out of the box, etc…), and then started to show how Azure App Service capabilities map to BizTalk Server capabilities and patterns that we all know and love:
API Apps
- Connectors: SaaS, Enterprise, Hybrid
- Pipeline Components: VETR
- Extensibility: Connectors and Pipeline
Logic Apps
- Orchestration
- Mediation Pipeline
- Tracking
The interesting one is the dual role of Logic Apps as both Orchestration and Mediation Pipeline (with API App components). So will we build pipeline (VETR focused) Logic Apps ending in a Service Bus connector that could potentially be subscribed to by orchestration (O focused) Logic Apps? Maybe? Either way, that’s a solid way to start the presentation.
After a trip through the slides, Prashant took us to the Azure Portal where all the magic happens. There he demoed a pretty nice scenario wherein we got to see all of the core BizTalk API Apps in action (complete with rules engine invocation, and EDIFACT normalization to a canonical XML model).
Sameer Chabungbam’s session was the last in the group of sessions diving deep into the world of Azure App Service. His session focused around building a custom connector/trigger (in this case for the Azure Storage Queue). He walked through the API App project template specifics (i.e., its inclusion of required references, and additional files that make it work, plus a quick walk through the helper class for Swagger metadata generation). Most of the specifics that he dealt with centered around custom metadata generation.
I’m going to take a step back for a moment because I sense there has been some confusion based on conversations that I’ve had today. The confusion centers around Swashbuckle and Swagger – both technologies used by API Apps. Neither of these technologies were built by Microsoft, they are both community efforts attempting to solve two different problems. Swagger is trying to solve the problem of providing a uniform metadata format for describing RESTful resources. Swashbuckle is trying to solve the problem of automatically generating swagger metadata for Web API applications. Swashbuckle can optionally provide a UI for navigating through documentation related to the API exposed by the metadata with help from swagger-ui.
With that background in place, essentially Sameer showed how we can make the Logic App designer-UI happy with consuming the metadata in such a way that it displays a connector and trigger in a user-friendly fashion (through custom display names, UI-suppressed parameters, etc…), while also taking advantage of the state information provided by the runtime within the custom trigger.
Generation/modification of the generated metadata can be accomplished through a few different mechanisms (that operate at different levels within the metadata) within Swashbuckle. The methods demonstrated made heavy use of OperationFilters (which control metadata generation at the operation level).
Unfortunately, my seat during this session did not provide a clear view of the screen, so I am unable to share all of the specifics at this time in a really easy fashion, but that is something that I will be writing up in short order in a separate posting.
UPDATE: The code from his talk has now been posted as a sample.
Yes, You Did Hear Jackhammering at Kovai
To kick off the BizTalk 360 presentation, Nino Credele provided comic relief demonstrating BizTalk Nos Ultimate – now the second offering in the BizTalk 360 family. I’ve got to just throw out a big congratulations to Nino especially and to the team at Kovai for pulling together the tool into a full commercial product. It has been really cool to watch it progress over time, and it must have been a special moment to be able to print out the product banners and make it real. Good work! A lot of developers are going to be very happy.
I also want to take time out to thank the BizTalk 360 team for continuing to organize these events – even though they’re not an event management company by trade – it does take a lot of work (and apparently involves walking 10km around the convention center each day).
No Zombies for Michael Stephenson and Oliver Davy
Not content to show off a web-scale, robust, enterprise-grade file copy demo, Michael Stephenson made integration look like magic by recasting the problem of application integration through the lens of Minecraft. While maybe an excuse for just playing around with fun technology, and getting in some solid cool dad time along the way, Michael showed what it might look like when one is forced to challenge established paradigms to extend data to applications and experiences that weren’t considered or imagined in advance.
This effort started during his work with Northumbria University, a university focused on turning integration into an enabler and not a blocker, to envision what the distant future of integration might look like. That future is one where the existence of an integration platform is assumed, and this becomes the fertile soil into which the seeds of curiosity can be sown. This future was positioned as a solution to those systems that were “developed by the business, but [haven’t] really ever been designed by the business. [They have] just grown.” (Oliver Davy – Architecture & Analysis Manager @ Northumbria University).
The approach to designing the integration platform of the future was to layer abstract logical capabilities / services within a core integration platform (e.g., Application Connector Service, Business Service, Integration Infrastructure Service, Service Gateway, API Management), and then, and only then, layer on concrete technologies with considerations for the hosting container of each. Capabilities outside of the core are grouped as extensions to the core platform (e.g., SOA, API & Services, Hybrid Integration, Industry Verticals, etc…). I felt like there were echoes of Shy Cohen’s Ontology and Taxonomy of Services2 paper.
Honestly, there’s some real wisdom in the approach – one that recognizes the additive nature of technologies in the integration spaces inasmuch as it is very rare that some architectural trend replace another trend. It is also an approach that seeks to apply lessons learned instead of throwing them away for shiny objects.
A common theme throughout Michael’s talk was the theme of agile integration. I’m hoping he takes time to expand on this concept further3. In other words, I don’t see “agile integrations” as integrations that fall into the “hacking IT” zone (which limits scope and often sacrifices quality to provide lower cost), but those that are limited in scope to provide lower cost without sacrificing quality.
Stephen Thomas’ Top 14 Integration Challenges
To wrap-up the day, Integration MVP Stephen Thomas shared the top 14 integration challenges that he has seen over the past 14 years (and did really well with a rough time slot):
- Finding Skilled Resources
- Having Too Much Production Access
- Following a Naming Standard
- Developing a Build and Deployment Process
- Understanding the Data
- Using the ESB Toolkit (Incorrectly)
- Planning Capacity Properly
- Creating Automated Unit Tests
- Thinking BizTalk Development is like .NET Development
- Having Environments Out of Sync
- Involving Production Support Too Late
- Allowing Operations to Drive Business Requirements
- Over Architecting
- Integrators Become Too Smart!
With a rich 14-year history in the space (and the ability to live up to his email address), Stephen shared some anecdotes for each of the points to address why they were included in the list.
Takeaway for the Day
I don’t have just one take-away for the day. I’ve written thousands of words here, and have 25 pages of raw unfiltered notes. Again, this is one of those times where I’m dumping information now, and will be synthesizing it in my head for another 6 months before having 1 or 2 moments of sheer clarity.
So on that note, here’s my take-away: people in the integration space are very intelligent, passionate, and driven – ultimately insanely impressive. I’m just happy to be here and I’m hoping that iron does indeed sharpen iron as we all come together and share new toys, battle stories, and proven patterns.
1 Not like @wearsy’s questions.
2 I’m sure just seeing the title of that article would give @MartinFowler heartburn.
3 Though he may have already, and I’m simply unaware.