Today, I will bring back to life an old BizTalk Server blog post by an old friend of mine, Thomas Canter, with his permission, that I find pretty interesting and useful: The maligned Distinguished Field or why Distinguished Fields are cool.
The Distinguished Field is often seen as the weaker of the two types of Fields when handling Fields in BizTalk.
After all, the Distinguished Field can’t be used as a filter on a message, and it’s slower than its big brother the Promoted Field.
Well, today I’m here to dispel the myth of the wimpy Distinguished Field and place in the pantheon of power that equals, and in some ways exceeds the Promoted Field.
MYTH: Getting the value of a Distinguished Field requires loading the entire message into memory.
The first myth we need to dispel is that the Promoted Field is quicker to access than the Distinguished Field.
This is due to the statement in the old BizTalk Documentation (now deprecated but still possible to retrieve), and I quote:
One of the benefits of promoted Fields is that the value of the element that is promoted is available in the context of the message. This means that retrieving that value is inexpensive, as it does not require loading the message into memory to execute an XPath statement on the message.
from The BizTalk Server Message.
What is implied here is that for the Promoted Field reading, its value doesn’t require an XPath read into the message and, conversely, that the Distinguished Field does require loading the message and has a performance cost because it’s evaluated when queried.
Nothing could be further from the truth! In fact, both the Promoted and Distinguished Fields are evaluated at the same time, and both are placed in the message context at the same time. So, let’s talk about how fields get into the message context.
… Lots of stuff cut out…
Since Distinguished fields do not require a separate property schema, the evaluation of Distinguished fields by the Orchestration engine consumes less overhead than the evaluation of Property fields by the Orchestration engine. The evaluation of Property fields requires an XPath query, the evaluation of Distinguished fields does not require an XPath query as the pipeline disassembler populates the Distinguished fields in the context and the orchestration engine gets the cached values. However, if the orchestration engine does not find the property in the context, it will then evaluate the XPath query to find the value. Distinguished fields do not have a size limitation.
from About BizTalk Message Context Fields
Now, how does Promoted and Distinguished Fields get into the Message Context? This occurs automatically in the Receive Pipeline by specific pre-built pipeline components?
Out of the box, the BizTalk XML Disassembler, BizTalk Flat File Disassembler, and the BizTalk Framework Disassembler Promote Fields to the message context. All other production level Pipelines promote fields, most also support Distinguished Fields.
Distinguished Fields are written to the Message Context if one of these Receive Pipeline Components is used in the Pipeline. Interestingly enough, this explains why the Passthrough pipeline doesn’t promote Fields from the message. There are no components in the Passthrough Pipeline, it does nothing to the message content and therefore, nothing gets promoted, especially BTS.MessageType.
Regarding performance, Distinguished Fields beat out Promoted Fields 9 days each week. This is because both Promoted and Distinguished require the same overhead of writing the message value to the context Field bag in the Message Box. Still, Promoted Fields have the additional overhead of both being written to the Message Box context database AND the Subscription database. Promoted Fields have an impact every time a message is written to the Message Box because each Promoted Field that exists must be evaluated in a massive union (very efficiently written union, mind you!) that builds the list of matching activation subscriptions. So, in short, the more Promoted Fields that you have, the costlier the subscription process.
RECOMMENDATION: Use Promoted somewhat sparingly. Don’t avoid them, but do not use them if you do not need to. Use Promoted Fields as they were designed: to facilitate message routing, but not to make it easy to access a message value. Instead, primarily use Distinguished Fields.
MYTH: It’s always safe to use a Promoted or Distinguished Field in an Orchestration.
exists test for the existence of a message context property BTS.RetryCount exists Message_In
from Using Operators in Expressions
Let us talk about how to handle message content that is missing when it is a Promoted Field and a Distinguished Field. What we are talking about specifically is the field that was Promoted, or Distinguished did not exist in the inbound message. The XLANG/s xpath statement that was used to query the message for the content during pipeline processing returned a null object.
The first thing to understand is when a Promoted and Distinguished Field comes into existence. They are essentially the same, and this occurs when a Pipeline component parses a message and either Promotes or Writes the value to the context. The simple answer is that when the value does not exist, the Field is not created. A query to the context for the Field returns a null object.
So, if you attempt to access a Promoted or Distinguished Field that didn’t exist in the inbound message, you can cause an unhandled exception to be thrown. Specifically, in both cases, a NullReferenceException.
Promoted Fields have a special XLang/s test operator: exists (we will soon blog about this operator). You can use this operator to determine if they exist before attempting to use them. In this case, Promoted Fields can always be tested for existence before use and can safely be avoided when they don’t exist.
Unfortunately, Distinguished Fields don’t have such a special test operator, and can cause an unpreventable unhandled exception. Specifically, if you use a Field that the underlying type is a native non-nullable type. For instance, suppose the value that you have distinguished is an integer. Integers cannot be null (and yes, I am aware of the Nullable generics, but we are talking about what BizTalk XLANG/s has, not what is C# has), and if the underlying value didn’t exist, and you attempt to use the value, or even test to see if the value exists will cause an unhandled NullReferenceException when BizTalk’s XLang engine attempts to convert a null value into an integer by calling the System.Number.Parse(string) method with a null value.
Here comes in the kicker and why a Distinguished field can appear to be fine at design time but bite you at run-time.
At design time, the expression editor generates a pseudo-class-like dotted object for you to use in your expression. At run-time, there is simple type-casting that occurs by the run-time engine that inspects the XML datatype of the node in the Schema, retrieves the value as an object… then attempts to call the appropriate ConvertTo method on the Object. When casting a Null to an Int32 or any other intrinsic datatype, a NullReferenceException is thrown, and the Orchestration fails.
The primary difference (excluding Routing) between Promoted and Distinguished Fields is the developer’s design-time experience. Distinguished Fields are easy to use because they emulate .Net Class dotted notation.
RECOMMENDATION: If there is any chance that accessing the Distinguished Field may cause an exception, then place the check in a Scope Shape that has a catch shape to handle the NullReferenceException.
MYTH: Distinguished Fields are only accessible in Orchestrations
Another major fallacy about Distinguished Fields is that they are only accessible in the Orchestration. This is also untrue. The BizTalk Server Documentation clearly has an example of how to use Distinguished Fields in any component from the RIGHT Documentation above.
All Distinguished Fields outside of an Orchestration use a fixed schema: http://schemas.microsoft.com/BizTalk/2003/btsDistinguishedFields
The Field to use is the XPath of the node that is Distinguished, such as:
/*[local-name()='PO' and namespace-uri()='http://SendHtmlMessage.PO']/*[local-name()='Price' and namespace-uri()='']
Thus, to access this, you would use the Read Method:
MyObject = MyMessageContext.Read("/*[local-name()='PO' and namespace-uri()='http://SendHtmlMessage.PO']/*[local-name()='Price' and namespace-uri()='']", " http://schemas.microsoft.com/BizTalk/2003/btsDistinguishedFields”);
If the Field exists, then MyObject will contain an object that can be cast to the appropriate type.
RECOMMENDATION: Once the proper Pipeline Component has processed the message, use the Distinguished Field as you would any Field without the Xpath lookup overhead.
MYTH: Distinguished Fields in Orchestration Expression shapes are actually code.
You have to hand it to the people who did the coding for XLANG/s. It looks like C#, it feels like C#, and 99% of the time, it pretty much generates standard C#.
In many ways, this is not your father’s C#. It is really XLANG/s, and it has its own syntax and special components. Distinguished Fields are a prime example.
Think back on all the times you used a distinguished Field. It feels like it’s a C# Object! It uses dotted notation (Node.Node.Node.Attribute). You assign values to it, you use its value in an expression, and it comes out as the correct type. When the node is Boolean, then it behaves like a Boolean. Nothing could be further from the actual behavior. Just because it looks like a duck, doesn’t mean that it’s a duck. It really is a trick, that the Expression Editor parses the XSD on the fly and generates a classlike editor experience, but no actual code ever gets generated.
Hope you find this helpful! So, if you liked the content or found it helpful and want to help me write more content, you can buy (or help buy) my son a Star Wars Lego!
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc.
He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community.
View all posts by Sandro Pereira
We live in an era where people seem to give titles and labels to everything, not just IT, but IT is a jungle! Systems designer, Systems analyst, Application support analyst, IT manager, IT coordinator, Solutions Architect, Web designer, Web development project manager, User interface (UI) designer, Webmaster, UX/UI specialist, SEO manager, Front-end developer, Back-end developer, Full-stack developer, Technology manager, Technology assistant, Business systems analyst, Information security engineer, Computer forensic investigator and so many more! And then we have that fancy one like Chief Digital Officer (CDO), Digital Transformation Specialist, Technology Evangelist, Chief Innovation Officer (CIO), Cybersecurity Ninja, Data Scientist, DevOps Guru, and the list is endless. Personally, I don’t like titles, and I consider myself an Enterprise Integration Consultant, which means that depending on the client’s needs, I can have different responsibilities. I can perform simple developer tasks or more responsible tasks like architecture and guidance.
By reading this book, the first impression I got was that the author was defending and/or selling the Solution Architect title almost as the mastermind behind everything, bordering on arrogance by using sentences like:
“That is when an SA has to switch to their guardian angel hat and come to the rescue.”
“That being said, SAs are not called guardian angels just for defending the developers but also are of great help if the team is short of hands…”
“As the name itself suggests, SAs have ownership of their solution, It’s creation. They designed it and they will be the ones who will have the final say.”
“As the SA, you won’t think about why you should do this, but you know that you are the only one who has to do it”
“… you have to be involved in the day-to-day operations of development, testing, user acceptance testing (UAT), and deployment phases.”
“…you will face some situations where developers are frustrated to know you design a solution the way you did, …”
And many more. The reality is that some of these behaviors and sentences do not correspond to reality or the best way to approach and bring a solution to a successful conclusion. And to be honest, if I have to sell my “title” like this, probably the client won’t need me…
However, abstracting from this somewhat arrogant behavior, in my opinion of the author about the highly inflated profile of an SA, the book touches on some very interesting points in the life cycle of a solution and to each intends to become a solutions architect or a project manager. And although in certain parts the author particularizes the text for RPA solution, as well as the name of the book mentions, in my opinion, most of the book is written generically. An Enterprise Integration solution architect or a BI solution architect has to have the same concepts, responsibilities, and skills as an RPA solution architect.
Even so, for those who want to be responsible for the management and architecture of solutions, it is a pleasant book to read. However, be more humble, try to integrate all those involved in the decisions on solutions, and make them part of the project. If people have a sense of belonging, they give 100%.
RPA Solution Architect’s Handbook Book Description
RPA solution architects play an important role in the automation journey and initiatives within the organization. However, the implementation process is quite complex and daunting at times. RPA Solution Architect’s Handbook is a playbook for solution architects looking to build well-designed and scalable RPA solutions.
You’ll begin by understanding the different roles, responsibilities, and interactions between cross-functional teams. Then, you’ll learn about the pillars of a good design: stability, maintainability, scalability, and resilience, helping you develop a process design document, solution design document, SIT/UAT scripts, and wireframes. You’ll also learn how to design reusable components for faster, cheaper, and better RPA implementation, and design and develop best practices for module decoupling, handling garbage collection, and exception handling. At the end of the book, you’ll explore the concepts of privacy, security, reporting automated processes, analytics, and taking preventive action to keep the bots healthy.
By the end of this book, you’ll be well equipped to undertake a complete RPA process from design to implementation efficiently.
What you will learn
Understand the architectural considerations for stability, maintainability, and resilience for effective RPA solution design.
Interact with cross-functional teams for seamless RPA implementation.
Write effective RPA documentation, non-functional requirements, and effective UAT scripts.
Demo RPA solutions, receive feedback, and triage additional requirements based on complexity, time, and cost.
Design considerations for intelligent automation and learn about RPA as a service.
Explore best practices for decoupling, handling garbage collection, and exception handling.
Who is this book for
This book is for RPA developers, RPA Sr. developers, or RPA analysts looking to become RPA solution architects. If you are an RPA solution architect, this book can help you advance your understanding and become more efficient. Familiarity with RPA documentation like SDD, and PDD, along with hands-on experience with either one or more RPA tools, will be helpful but is not mandatory.
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc.
He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community.
View all posts by Sandro Pereira
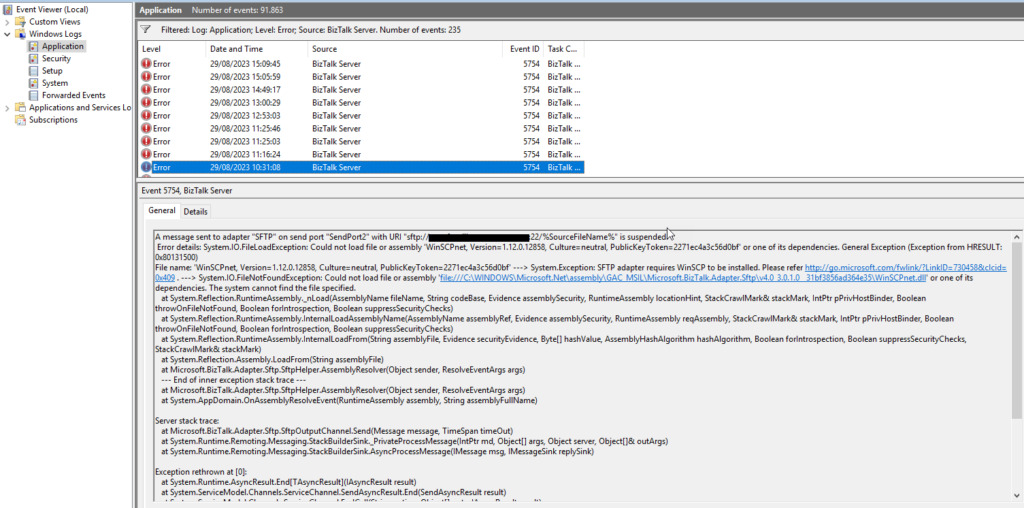
It is always fun to return to one of my favorite topics: Errors and warnings, causes and solutions – aka Troubleshooting! Regardless of the technology, language, or service, we are using. In this case, this problem occurred when configuring the SFTP adapter in BizTalk Server 2020, which means BizTalk Server and WinSCP.
After installing and configuring the pre-requirements of the SFTP adapter according to the official documentation and using the BizTalk WinSCP PowerShell Installer, you can find it here. In our case, the latest official WinSCP version 5.19.2. We got the following error while trying to send a test message using the SFTP adapter:
A message sent to adapter “SFTP” on send port “SendPort2” with URI “sftp:/FTP-SERVER:22/%SourceFileName%” is suspended.
Error details: System.IO.FileLoadException: Could not load file or assembly ‘WinSCPnet, Version=1.12.0.12858, Culture=neutral, PublicKeyToken=2271ec4a3c56d0bf’ or one of its dependencies. General Exception (Exception from HRESULT: 0x80131500)
File name: ‘WinSCPnet, Version=1.12.0.12858, Culture=neutral, PublicKeyToken=2271ec4a3c56d0bf’ —> System.Exception: SFTP adapter requires WinSCP to be installed. Please refer http://go.microsoft.com/fwlink/?LinkID=730458&clcid=0x409 . —> System.IO.FileNotFoundException: Could not load file or assembly ‘file:///C:WINDOWSMicrosoft.NetassemblyGAC_MSILMicrosoft.BizTalk.Adapter.Sftpv4.0_3.0.1.0__31bf3856ad364e35WinSCPnet.dll‘ or one of its dependencies. The system cannot find the file specified.
at System.Reflection.Assembly.LoadFrom(String assemblyFile)
at Microsoft.BizTalk.Adapter.Sftp.SftpHelper.AssemblyResolver(Object sender, ResolveEventArgs args)
— End of inner exception stack trace —
at Microsoft.BizTalk.Adapter.Sftp.SftpHelper.AssemblyResolver(Object sender, ResolveEventArgs args)
at System.AppDomain.OnAssemblyResolveEvent(RuntimeAssembly assembly, String assemblyFullName)
Server stack trace:
at Microsoft.BizTalk.Adapter.Sftp.SftpOutputChannel.Send(Message message, TimeSpan timeOut)
at System.Runtime.Remoting.Messaging.StackBuilderSink._PrivateProcessMessage(IntPtr md, Object[] args, Object server, Object[]& outArgs)
at System.Runtime.Remoting.Messaging.StackBuilderSink.AsyncProcessMessage(IMessage msg, IMessageSink replySink)
Exception rethrown at [0]:
at System.Runtime.AsyncResult.End[TAsyncResult](IAsyncResult result)
at System.ServiceModel.Channels.ServiceChannel.SendAsyncResult.End(SendAsyncResult result)
at System.ServiceModel.Channels.ServiceChannel.EndCall(String action, Object[] outs, IAsyncResult result)
Exception rethrown at [1]:
at System.Runtime.Remoting.Proxies.RealProxy.HandleReturnMessage(IMessage reqMsg, IMessage retMsg)
at System.Runtime.Remoting.Proxies.RealProxy.PrivateInvoke(MessageData& msgData, Int32 type)
at System.ServiceModel.Channels.IOutputChannel.EndSend(IAsyncResult result)
at Microsoft.BizTalk.Adapter.Wcf.Runtime.WcfClient`2.SendCallback(IAsyncResult result)
I was surprised by the error because this wasn’t the first time I had installed the SFPT Adapter. I have successfully performed this configuration in many clients and never found myself in a WinSCP DLL version nightmare.
Cause
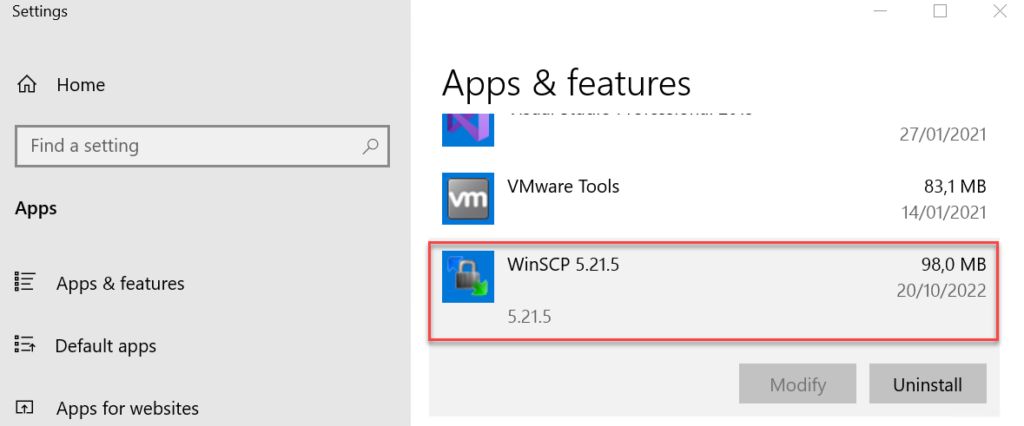
As mentioned, I never had a version issue with the WinSCP DLLs if I installed it according to the documentation. That means depending on the BizTalk Server version and cumulative we have installed, we have to select the proper WinSCP version, for example:
With BizTalk Server 2020 (no CU installed), we need to use WinSCP 5.15.4
With BizTalk Server 2020 with CU1 and/or CU2 we need to use WinSCP 5.17.6
With BizTalk Server 2020 with CU3 and/or CU4 we need to use WinSCP 5.19.2
To put the SFTP Adapter, we need to copy the WinSCP.exe and WinSCPnet.dll to the BizTalk installation folder, normally C:Program Files (x86)Microsoft BizTalk Server. So, by the error description, this issue was clearly a DLL version issue.
In our case, we had BizTalk Server 2020 with CU4 and correctly installed the WinSCP 5.19.2. However, this version of WinSCP brings version 1.8.3.11614 of WinSCPnet.dll instead of version 1.12.0.12858, which is asking for. WinSCPnet.dll version 1.12.0.12858 is only available in WinSCP 5.21.5.
After some investigation, we detected that WinSCP version 5.21.5 was installed on the server, and because of that, the BizTalk Server SFTP adapter was trying to look for this version on C:WINDOWSMicrosoft.NetassemblyGAC_MSILMicrosoft.BizTalk.Adapter.Sftpv4.0_3.0.1.0__31bf3856ad364e35.
Notice that you don’t need to install any WinSCP software or GAC any WinSCP DLL on the BizTalk Server machine.
Solution
In the end, this is an issue that can be fixed easily. And there are many ways to solve this:
First approach: This may be the correct approach, is to:
Uninstall the WinSCP 5.21.5 version or any other version installed on the machine.
Make sure that there aren’t any WinSCPnet.dll in the GAC.
Note: We didn’t apply this approach because we were unsure who and what was using this WinSCP version.
Second approach: This second approach may not be 100% supported, but it still works like a charm.
We maybe also solve this problem by using an assembly redirect on the machine.config but I didn’t try it out.
Hope you find this helpful! So, if you liked the content or found it helpful and want to help me write more content, you can buy (or help buy) my son a Star Wars Lego!
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc.
He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community.
View all posts by Sandro Pereira
This is just another post for the sake of my mental sanity because I’m always tired of looking up for this over and over again. While working on BizTalk Server projects, and in many other scenarios, we have to check if a specific user has access to specific resources in a file share or the file share itself, and we don’t want to disconnect (log off) from the machine and log on on the same machine using a different account. Sometimes, this account doesn’t have remote desktop access either.
So, the main question is: How to run Windows File Explorer as a different user?
There are several ways to accomplish this, but if you need to run File Explorer as a different user, the simplest way to accomplish that is by:
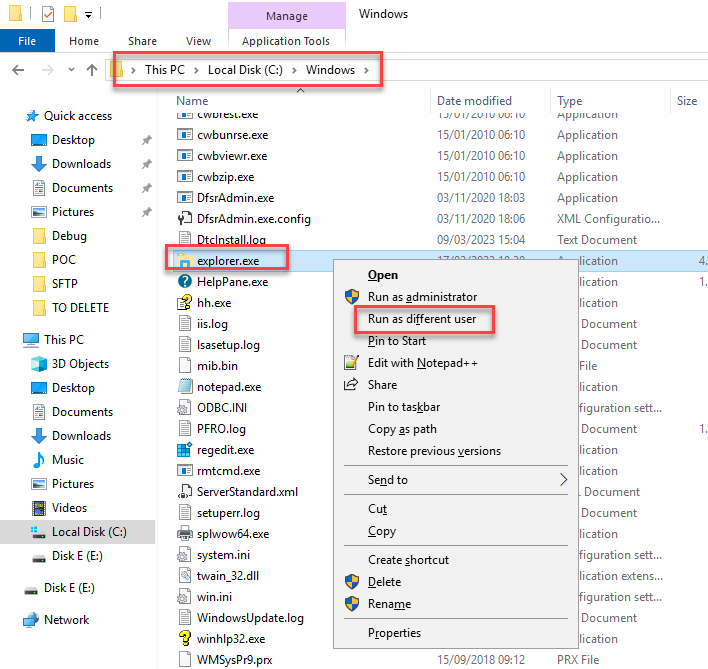
Open the File Explorer, normally as we usually do, and access the following folder:
C:Windows
Scroll down until you find the explorer.exe executable, or search for this file in the search field in the upper right corner.
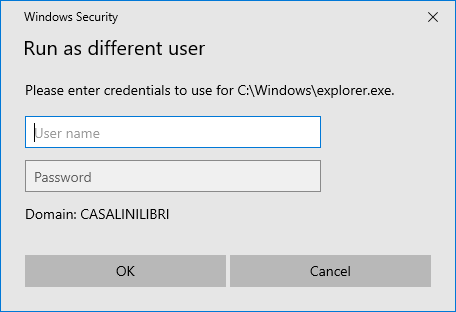
Press the Shift key, and with the Shift key pressed, right-click on the explorer.exe file, and on the context menu, select Run as different user.
In the Windows Security window that appears, you need to specify the name and password of the user under whose account you want to run the application and click OK.
After this, a new File Explorer is open, running under the specified user account.
Any Windows user can run a program in his current session on behalf of another user using RunAs. This feature allows you to run any scripts (.bat, .cmd, .vbs, .ps1), executable files (.exe), or install applications (.msi, .cab) with the permissions of another user without the need to log off and log in on the machine with different users/credentials.
Hope you find this helpful! So, if you liked the content or found it helpful and want to help me write more content, you can buy (or help buy) my son a Star Wars Lego!
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc.
He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community.
View all posts by Sandro Pereira
I always love Microsoft Visio to create my Enterprise Integration documentation. That passion led me to create the Microsoft Integration and Azure Stencils Pack for Visio – a Visio package that contains fully resizable Visio shapes (symbols/icons) that will help you to visually represent On-premise, Cloud or Hybrid Integration and Enterprise architectures scenarios (BizTalk Server, API Management, Logic Apps, Service Bus, Event Hub…), solutions diagrams and features or systems that use Microsoft Azure and related cloud and on-premises technologies in Visio. Most of you may know me for being a Microsoft Azure MVP, where my focus is Enterprise Integration, but I’m also a former Visio MVP. All of this just to say that I had expectations high for this book!
To be honest, based on the title of this book: Visualize Complex Processes with Microsoft Visio, I was expecting different content with more real cases and complex scenarios explained in detail, different implementation strategies, and advanced designing tips. But I soon realized that the book would guide me differently. Did I get disappointed with the book? No. I choose the book by the name without reading the description and table of content. And I cannot criticize a book just for its title or for my mistakes. In fact, I was surprised by how many small things I have learned from this book.
For me, this book is an excellent guide for professionals seeking to learn or enhance their Visio skills, not to design complex processes. Nevertheless, the authors will give you some best practices to archive that. The book will guide you to the different types of diagrams and different types of Visio versions. Of course, how to work with Visio and how you can manually create your flow diagrams. How to utilize data sources, share (security include) or collaborate, and integrate Visio with Microsoft Apps or /and BPMN.
In resume, I enjoyed the book, and I will recommend it to anyone seeking to learn or enhance their Visio skills.
Visualize Complex Processes with Microsoft Visio Book Description
Every business has process flows, but not all of them are fully described to or verified for accuracy with each stakeholder. This not only presents a risk for business continuity but also removes the ability to make insightful improvements. To make these complex interactions easy to grasp, it’s important to describe these processes visually using symbology that everybody understands. Different parts of these flows should be collaboratively developed and stored securely as commercial collateral.
Visualize Complex Processes with Microsoft Visio helps you understand why it is crucial to use a common, systematic approach to document the steps needed to meet each business requirement. This book explores the various process flow templates available in each edition of Microsoft Visio, including BPMN. It also shows you how to use them effectively with the help of tips and techniques and examples to reduce the time required for creating them, as well as how you can improve their integration and presentation.
By the end of this book, you’ll have mastered the skills needed to create data-integrated business flowcharts with Microsoft Visio, learned how to effectively use these diagrams collaboratively, but securely, and understood how to integrate them with other M365 apps, including Excel, Word, PowerPoint, and Power Automate.
What you will learn
Choose an appropriate flowchart diagram type to describe the process steps.
Develop the skills to efficiently use Visio to draw process flowcharts.
Discover how to create process flows diagrams to meet the BPMN standard.
Find out how to synchronize Excel tables with Visio process flowcharts.
Store flowcharts that can also be used for collaboration securely.
Understand how to export flowcharts and data to other M365 apps.
Discover how Visio ShapeSheet functions can increase productivity.
Who is this book for
Suppose you’re a manager, analyst, or designer of business processes. In that case, this book will help you create professional process diagrams effectively and consistently to improve the accuracy of communication and facilitate impactful insights. This book will also be helpful for beginners or power users seeking tips and techniques to capture process flows from context and customize diagrams to meet academic and corporate standards.
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc.
He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community.
View all posts by Sandro Pereira
In our Integration projects, especially nowadays on Azure Integration Services, we often work with JSON messages. And despite Logic App Designer allowing us to generate a JSON schema based on a JSON payload (or JSON message), but there are many situations we need the opposite! We want to generate a dummy message from the JSON Schema in order to test our Logic Apps solutions or now our Data Mapper maps.
Unfortunately, there aren’t any out-of-the-box capabilities inside Logic Apps or the new Data Mapper to generate a dummy message.
I’m doing a lot of demos and sessions on the new Data Mapper, and you cannot imagine the times I forget the input message for each specific map, and I find myself constantly looking for that information.
In order to accomplish that, we usually use free online tools like this one: https://www.liquid-technologies.com/online-schema-to-json-converter, but what annoys me about these online tools is that all data are stored in their log files, and sometimes for privacy/security concerns that can be a problem. Mainly because of this reason, I decide, along with my team, to start creating these free tools with the source code available on GitHub in order to not raise the same suspicions.
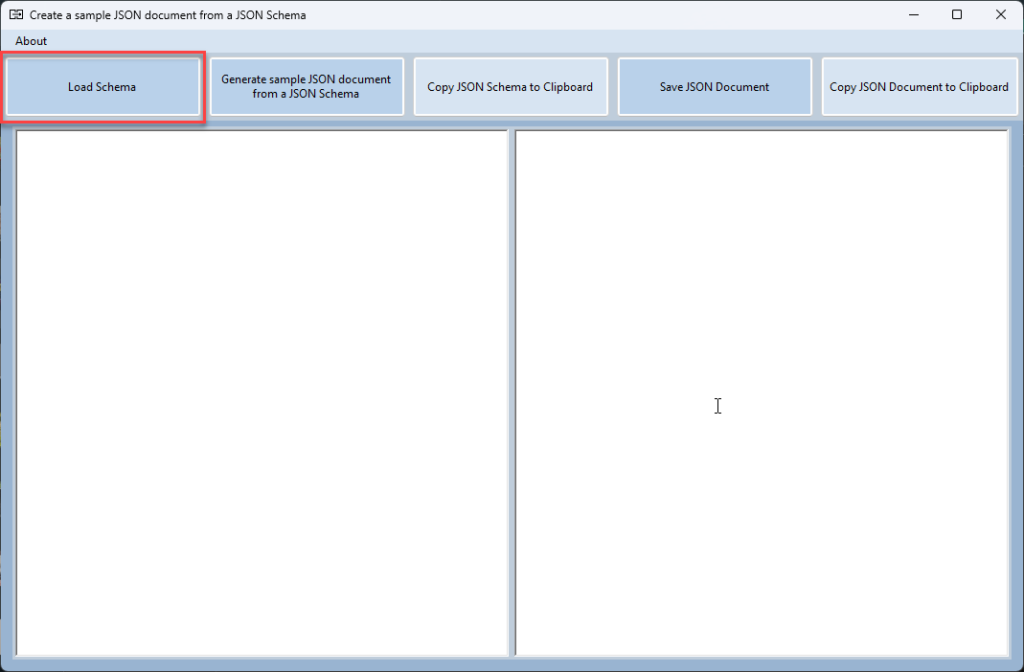
Create a sample JSON document from a JSON Schema Tool
Create a sample JSON document from a JSON Schema Tool is a straightforward Windows tool that allows you to create a JSON Document based on the JSON Schema we provide. No data are stored in log files.
In this new version, we will be able to load a JSON Schema from our local hard drive.
Download
Hope you find this useful! So, if you liked the content or found it useful and want to help me write more content, you can buy (or help buy) my son a Star Wars Lego!
Credits
Luis Rigueira | Member of my team and one of the persons responsible for developing this tool.
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc.
He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community.
View all posts by Sandro Pereira
In our Integration projects, especially nowadays on Azure Integration Services, we often work with JSON messages. And despite Logic App Designer allowing us to generate a JSON schema based on a JSON payload (or JSON message), but there are many situations we need the opposite! We want to generate a dummy message from the JSON Schema in order to test our Logic Apps solutions or now our Data Mapper maps.
Unfortunately, there aren’t any out-of-the-box capabilities inside Logic Apps or the new Data Mapper to generate a dummy message.
I’m doing a lot of demos and sessions on the new Data Mapper, and you cannot imagine the times I forget the input message for each specific map, and I find myself constantly looking for that information.
In order to accomplish that, we usually use free online tools like this one: https://www.liquid-technologies.com/online-schema-to-json-converter, but what annoys me about these online tools is that all data are stored in their log files, and sometimes for privacy/security concerns that can be a problem. Mainly because of this reason, I decide, along with my team, to start creating these free tools with the source code available on GitHub in order to not raise the same suspicions.
Create a sample JSON document from a JSON Schema Tool
Create a sample JSON document from a JSON Schema Tool is a straightforward Windows tool that allows you to create a JSON Document based on the JSON Schema we provide. No data are stored in log files.
In this new version, we will be able to load a JSON message from our local hard drive.
Download
Hope you find this useful! So, if you liked the content or found it useful and want to help me write more content, you can buy (or help buy) my son a Star Wars Lego!
Credits
Luis Rigueira | Member of my team and one of the persons responsible for developing this tool.
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc.
He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community.
View all posts by Sandro Pereira
Because the Math (or Mathematical) functions category has too many functions, I decide to break this blog post into different parts, so welcome to the second part!
Overview
Math (or Mathematical) functions are used to perform a variety of mathematical and scientific operations, such as addition and multiplication. If you come from the BizTalk Server background or are migrating BizTalk Server projects, they are the equivalent of Mathematical and Scientific Functoids inside BizTalk Mapper Editor.
Available Functions
The Math functions are:
Absolute: Returns the absolute value of the specified number.
Add: Returns the sum from adding two or more numbers.
Arctangent: Returns the arc tangent of a number.
Ceiling: Returns the smallest integral value greater than or equal to the specified number.
Cosine: Returns the cosine for the specified angle.
Divide: Returns the result from dividing two numbers.
Exponential: Raises the “e” constant to the specified power and returns the result.
Exponential (base 10): Returns the number 10 raised to the specified power.
Floor: Returns the largest integral value less than or equal to the specified number.
Integer divide: Divides two numbers and returns the integer part from the result.
Log: Returns the logarithm for the specified number in the specified base.
Log (base 10): Returns the base 10 logarithm for the specified number.
Modulo: Returns the remainder from dividing the specified numbers.
Multiply: Returns the product from multiplying two or more specified numbers.
Power: Returns the specified number raised to the specified power.
Round: Rounds a value to the nearest integer or the specified number of fractional digits and returns the result.
Square root: Returns the square root for the specified number.
Subtract: Subtracts the second number from the first number and returns the result.
Tangent: Returns the tangent for the specified angle.
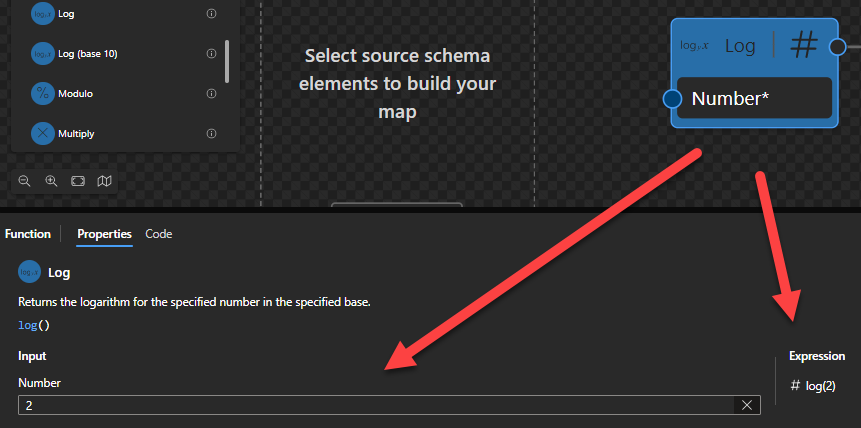
Log
This function states that it will return the logarithm for the specified number in the specified base.
Behind the scenes, this function is translated to the following XPath function: math:log($arg)
math:log($arg as xs:double?) as xs:double?
Rules:
The result is the natural logarithm of $arg
Sample:
The expression math:log(0) returns xs:double('-INF').
The expression math:log(-1) returns xs:double('NaN').
The expression math:log(2) returns 0.6931471805599453
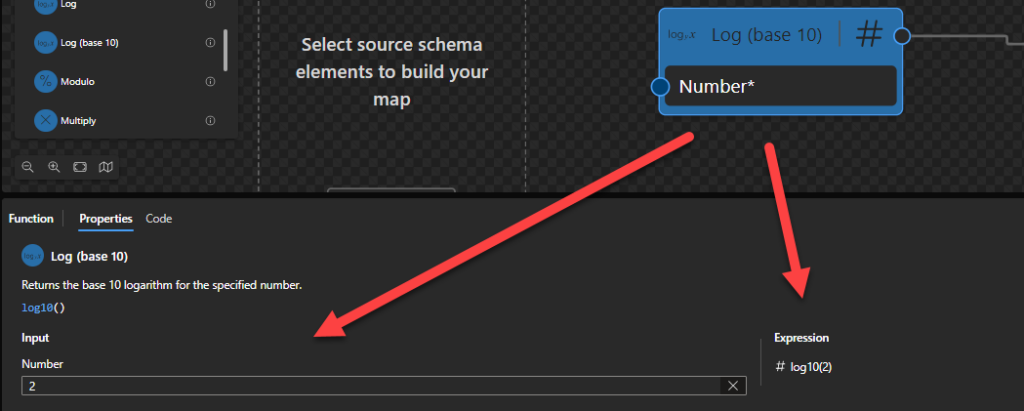
Log (base 10)
This function states that it will return the base 10 logarithm for the specified number.
Behind the scenes, this function is translated to the following XPath function: math:log10($arg)
math:log10($arg as xs:double?) as xs:double?
Rules:
The result is the base-10 logarithm of $arg
Sample:
The expression math:log10(0) returns xs:double('-INF')
The expression math:log10(2) returns 0.3010299956639812
The expression math:log10(-1) returns xs:double('NaN')
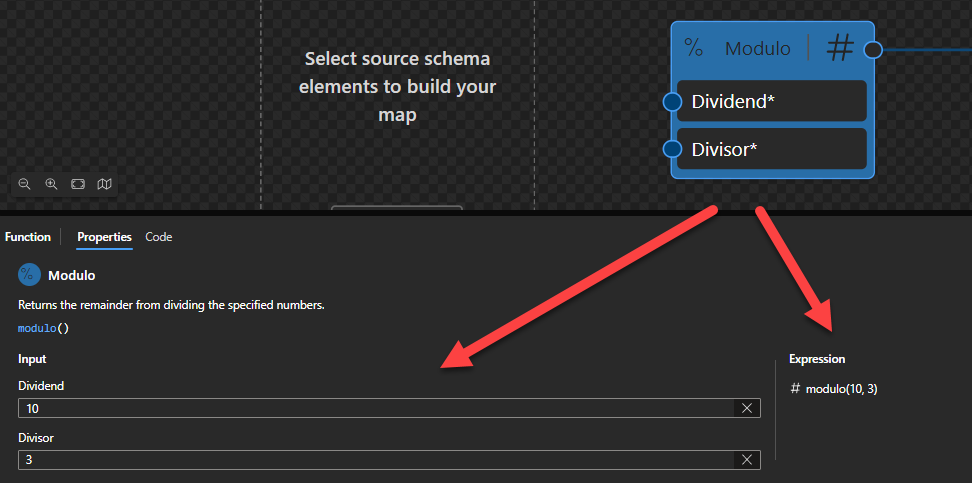
Modulo
This function states that it will return the remainder from dividing the specified numbers.
Behind the scenes, this function is translated to the following XPath expression: ($arg1) mod ($arg2)
fn:error($code as xs:QName?, $description as xs:string) as none
Rules:
Returns the remainder resulting from dividing $arg1, the dividend, by $arg2, the divisor.
The operation a mod b for operands that are xs:integer or xs:decimal, or types derived from them, produces a result such that (a idiv b)*b+(a mod b) is equal to a and the magnitude of the result is always less than the magnitude of b. This identity holds even in the special case that the dividend is the negative integer of largest possible magnitude for its type and the divisor is -1 (the remainder is 0). It follows from this rule that the sign of the result is the sign of the dividend.
Sample:
The expression (10) mod (3) returns 1.
The expression (6) mod (-2) returns 0.
The expression (4.5) mod (1.2) returns 0.9.
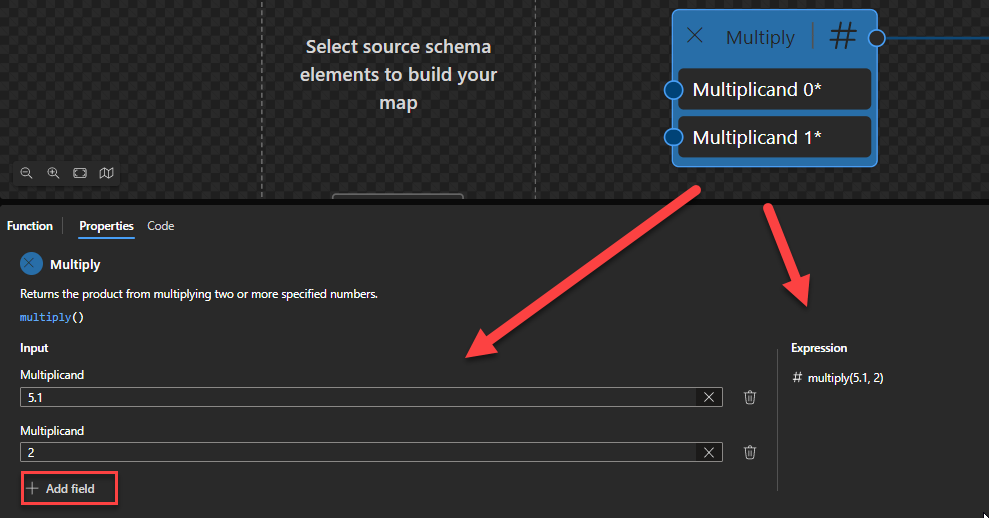
Multiply
This function states that it will return the product from multiplying two or more specified numbers.
Behind the scenes, this function is translated to the following XPath expression: ($arg1) * ($arg2) (allows more inputs)
($arg1) * ($arg2) as xs:numeric?
Rules:
Returns the arithmetic product of its operands: ($arg1 * $arg2).
For the four types xs:float, xs:double, xs:decimal and xs:integer, it is guaranteed that if the type of $arg is an instance of type T then the result will also be an instance of T. The result may also be an instance of a type derived from one of these four by restriction. For example, if $arg is an instance of xs:decimal then the result may be an instance of xs:integer.
This function allows two or more inputs.
Sample:
The expression (5) + (2) returns 10.
The expression (5.1) + (2) returns 10.2.
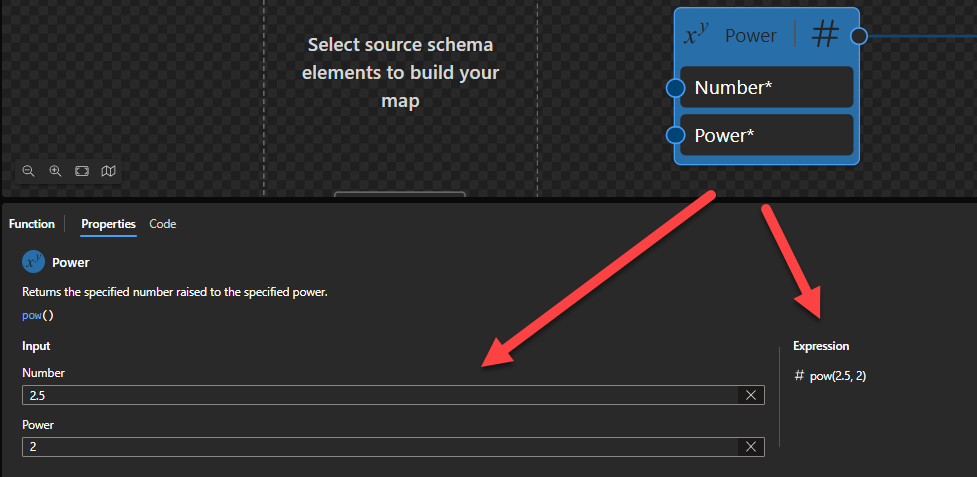
Power
This function states that it will return the specified number raised to the specified power.
Behind the scenes, this function is translated to the following XPath function: math:pow($arg1, $arg2)
math:pow($arg1 as xs:double?, $arg2 as xs:numeric) as xs:double?
Rules:
If $arg2 is an instance of xs:integer, the result is $arg1 raised to the power of $arg2. Otherwise $arg2 is converted to an xs:double by numeric promotion, and the result is the value of $arg1 raised to the power of $arg2.
Sample:
The expression math:pow(2, 3) returns 8.
The expression math:pow(-2, 3) returns -8
The expression math:pow(2, 0) returns 1
The expression math:pow(2.5, 2) returns 6.25
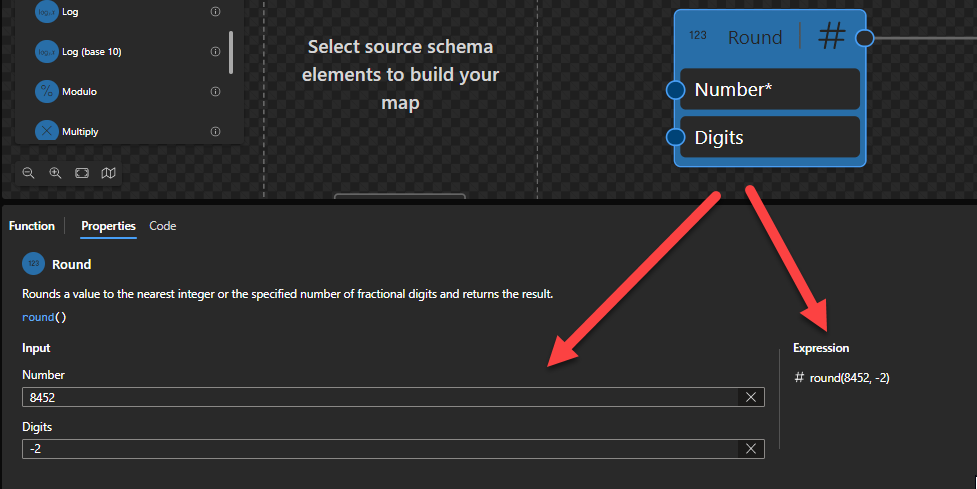
Round
This function states that it will round a value to the nearest integer or the specified number of fractional digits and returns the result.
Behind the scenes, this function is translated to the following XPath function: round($arg1, $arg2)
fn:round($arg as xs:numeric?, $precision as xs:integer) as xs:numeric?
Rules:
The function returns the nearest (that is, numerically closest) value to $arg that is a multiple of ten to the power of minus $precision. If two such values are equally near (for example, if the fractional part in $arg is exactly .5), the function returns the one that is closest to positive infinity.
For the four types xs:float, xs:double, xs:decimal and xs:integer, it is guaranteed that if the type of $arg is an instance of type T then the result will also be an instance of T. The result may also be an instance of a type derived from one of these four by restriction. For example, if $arg is an instance of xs:decimal and $precision is less than one, then the result may be an instance of xs:integer.
Sample:
The expression fn:round(1.125, 2) returns 1.13
The expression fn:round(8452, -2) returns 8500
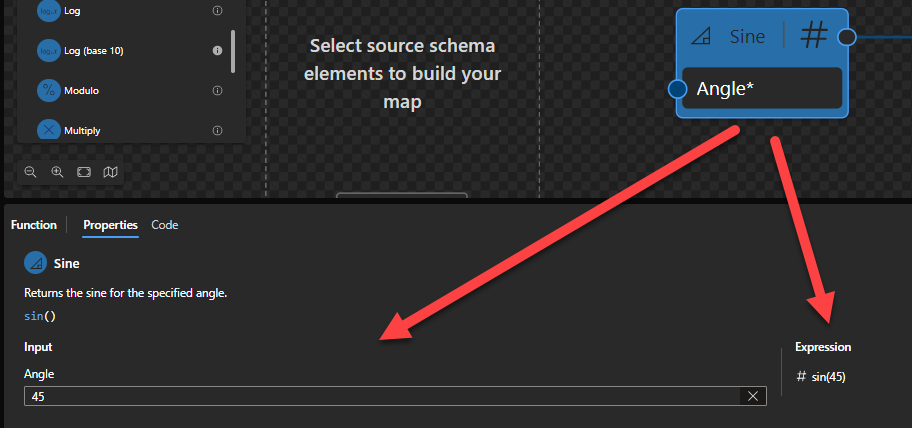
Sine
This function states that it will return the sine for the specified angle.
Behind the scenes, this function is translated to the following XPath function: math:sin($arg)
math:sin($arg as xs:double?) as xs:double?
Rules:
If $arg is positive or negative zero, the result is $arg.
Returns the sine of the argument. The argument is an angle in radians.
Sample:
The expression math:sin(0) returns 0.
The expression math:sin(45) returns 0.8509035245341184.
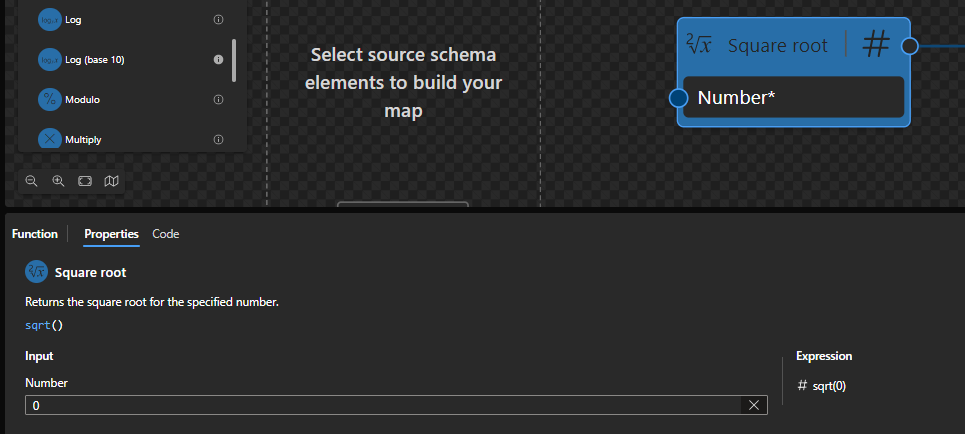
Square root
This function states that it will return the square root for the specified number.
Behind the scenes, this function is translated to the following XPath function: math:sqrt($arg)
math:sqrt($arg as xs:double?) as xs:double?
Rules:
If $arg is positive or negative zero, positive infinity, or NaN, then the result is $arg. (Negative zero is the only case where the result can have negative sign)
The result is the mathematical non-negative square root of $arg
Sample:
The expression math:sqrt(0) returns 0.
The expression math:sqrt(-2) returns NaN.
The expression math:sqrt(4) returns 2.
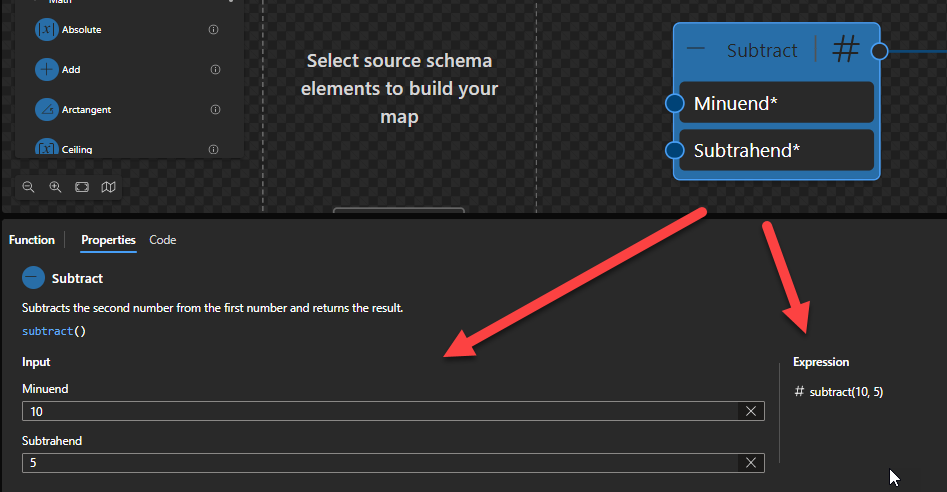
Subtract
This function states that it will subtract the second number from the first number and returns the result.
Behind the scenes, this function is translated to the following XPath function: ($arg1) - ($arg2)
($arg1 as xs:numeric - $arg2 as xs:numeric) as xs:numeric
Rules:
Returns the arithmetic difference of its operands: ($arg1 - $arg2).
$arg1 and $arg2 are numeric values (xs:float, xs:double, xs:decimal and xs:integer)
Sample:
The expression (3) - (1) returns 2.
The expression (2) - (1.12) returns 0.88.
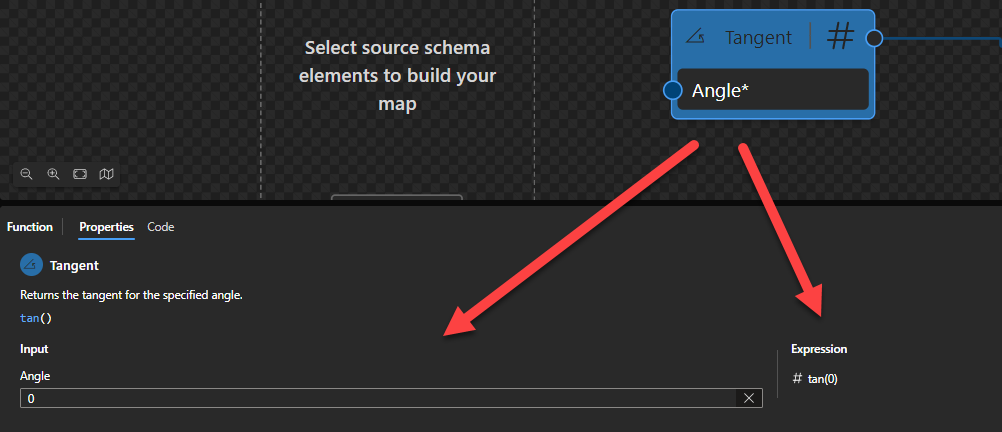
Tangent
This function states that it will return the tangent for the specified angle.
Behind the scenes, this function is translated to the following XPath function: math:tan($arg)
math:tan($arg as xs:double?) as xs:double?
Rules:
If $arg is positive or negative infinity, or NaN, then the result is NaN.
Returns the tangent of the argument. The argument is an angle in radians.
Sample:
The expression math:tan(0) returns 0
The expression math:tan(12) returns -0.6358599286615808
Hope you find this helpful! So, if you liked the content or found it useful and want to help me write more, you can buy (or help buy) my son a Star Wars Lego!
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc.
He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community.
View all posts by Sandro Pereira
Math (or Mathematical) functions are used to perform a variety of mathematical and scientific operations, such as addition and multiplication. If you come from the BizTalk Server background or are migrating BizTalk Server projects, they are the equivalent of Mathematical and Scientific Functoids inside BizTalk Mapper Editor.
Available Functions
The Math functions are:
Absolute: Returns the absolute value of the specified number.
Add: Returns the sum from adding two or more numbers.
Floor: Returns the largest integral value less than or equal to the specified number.
Integer divide: Divides two numbers and returns the integer part from the result.
Log: Returns the logarithm for the specified number in the specified base.
Log (base 10): Returns the base 10 logarithm for the specified number.
Modulo: Returns the remainder from dividing the specified numbers.
Multiply: Returns the product from multiplying two or more specified numbers.
Power: Returns the specified number raised to the specified power.
Round: Rounds a value to the nearest integer or the specified number of fractional digits and returns the result.
Sine: Returns the sine for the specified angle.
Square root: Returns the square root for the specified number.
Subtract: Subtracts the second number from the first number and returns the result.
Tangent: Returns the tangent for the specified angle.
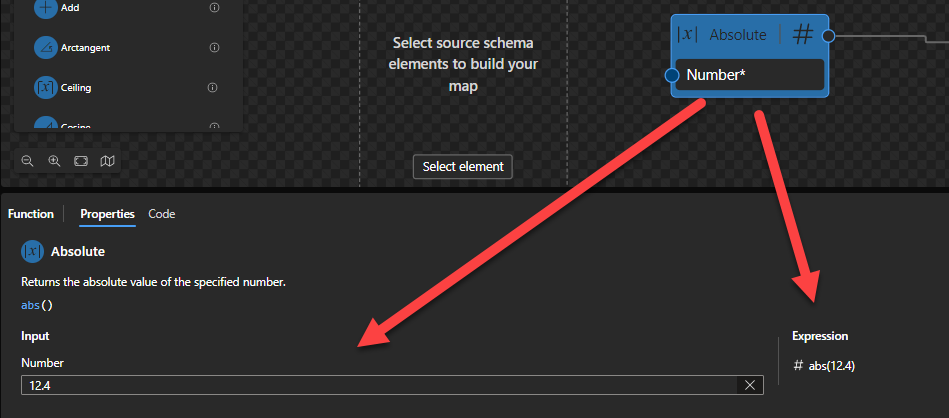
Absolute
This function states that it will return the absolute value of the specified number.
Behind the scenes, this function is translated to the following XPath function: abs($arg)
fn:abs($arg as xs:numeric?) as xs:numeric?
Rules:
If $arg is negative, the function returns -$arg. Otherwise, it returns $arg.
For the four types xs:float, xs:double, xs:decimal and xs:integer, it is guaranteed that if the type of $arg is an instance of type T then the result will also be an instance of T. The result may also be an instance of a type derived from one of these four by restriction. For example, if $arg is an instance of xs:positiveInteger then the value of $arg may be returned unchanged.
For xs:float and xs:double arguments, if the argument is positive zero or negative zero, then positive zero is returned. If the argument is positive or negative infinity, positive infinity is returned.
Sample:
The expression fn:abs(10.5) returns 10.5.
The expression fn:abs(-10.5) returns 10.5.
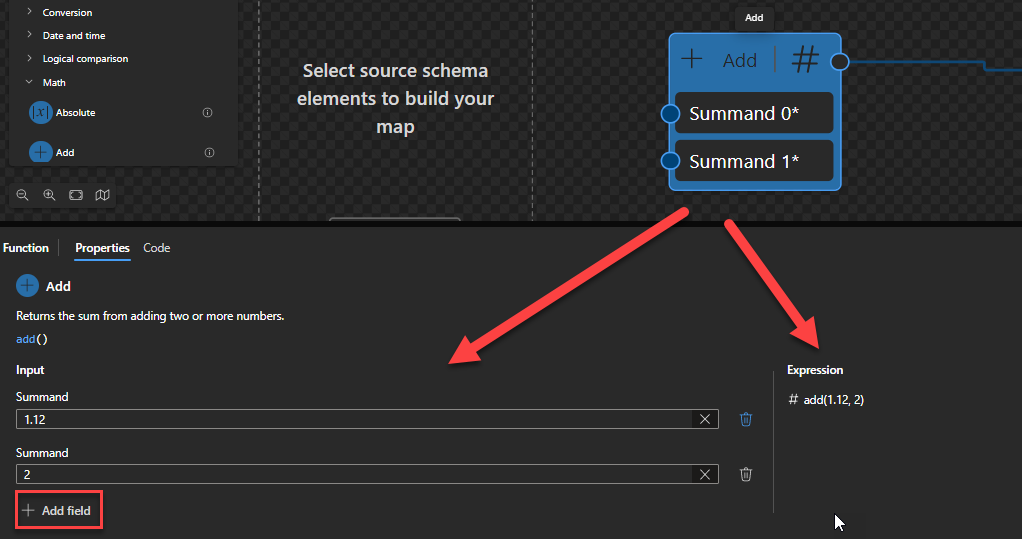
Add
This function states that it will return the sum from adding two or more numbers.
Behind the scenes, this function is translated to the following XPath expression: $arg1 + $arg2 (allows more inputs)
($arg1 as xs:numeric + $arg2 as xs:numeric) as xs:numeric
Rules:
Returns the arithmetic sum of its operands: ($arg1 + $arg2).
$arg1 and $arg2 are numeric values (xs:float, xs:double, xs:decimal and xs:integer)
This function allows two or more inputs.
Sample:
The expression (1) + (3) returns 4.
The expression (1.12) + (2) returns 3.12.
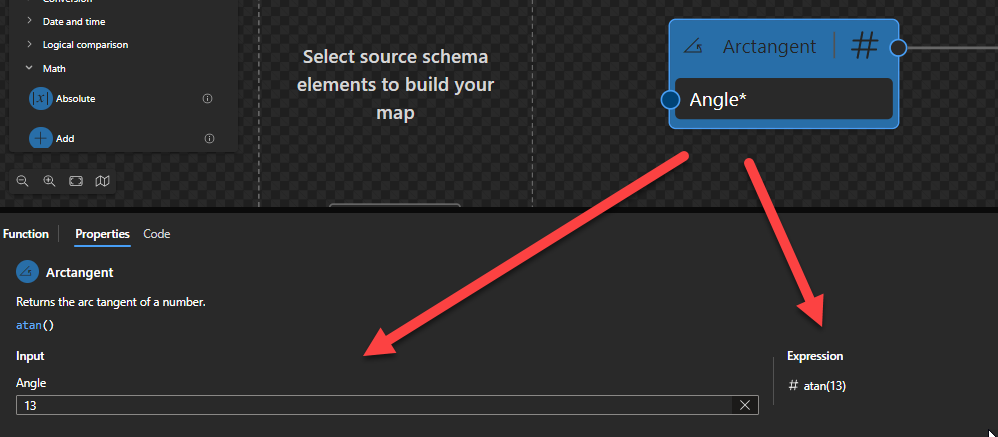
Arctangent
This function states that it will return the arc tangent of a number.
Behind the scenes, this function is translated to the following XPath function: math:atan($arg)
math:atan($arg as xs:double?) as xs:double?
Rules:
If $arg is a non-numeric value, then the result is empty.
Sample:
The expression math:atan(0) returns 0.
The expression math:atan(1.28) returns 0.9075933340888034.
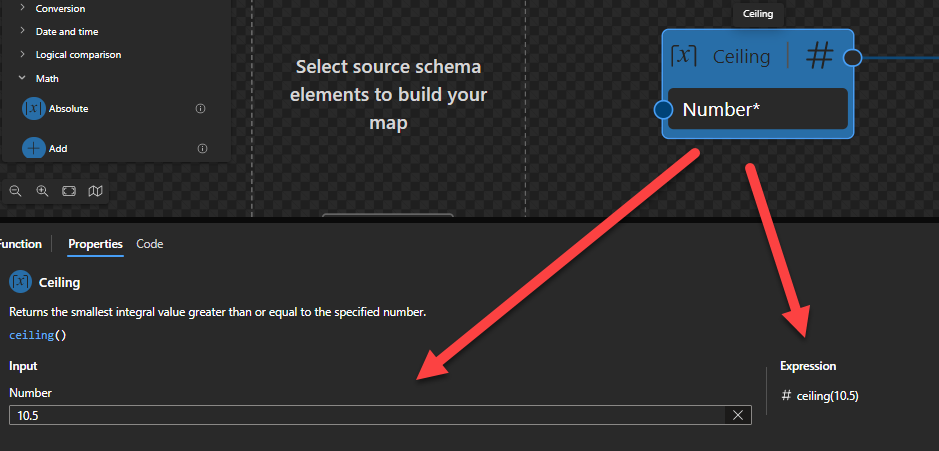
Ceiling
This function states that it will return the smallest integral value greater than or equal to the specified number.
Behind the scenes, this function is translated to the following XPath function: ceiling($arg)
fn:ceiling($arg as xs:numeric?) as xs:numeric?
Rules:
The function returns the smallest (closest to negative infinity) number with no fractional part that is not less than the value of $arg.
For the four types xs:float, xs:double, xs:decimal and xs:integer, it is guaranteed that if the type of $arg is an instance of type T then the result will also be an instance of T. The result may also be an instance of a type derived from one of these four by restriction. For example, if $arg is an instance of xs:decimal then the result may be an instance of xs:integer.
Sample:
The expression fn:ceiling(10.5) returns 11.
The expression fn:ceiling(-10.5) returns -10.
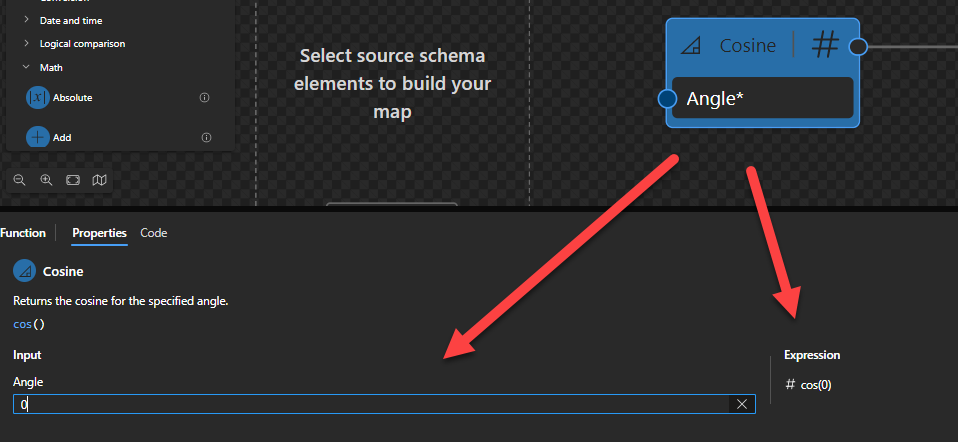
Cosine
This function states that it will return the cosine for the specified angle.
Behind the scenes, this function is translated to the following XPath function: math:cos($arg)
math:cos($arg as xs:double?) as xs:double?
Rules:
If $arg is positive or negative zero, the result is $arg.
Sample:
The expression math:cos(0) returns 1
The expression math:cos(1212) returns 0.7931914936378434
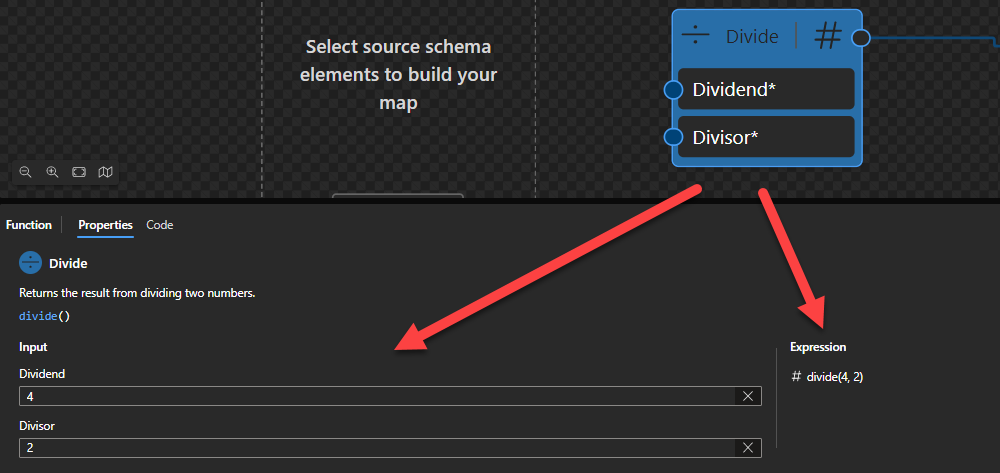
Divide
This function states that it will return the result from dividing two numbers.
Behind the scenes, this function is translated to the following XPath function: $arg1 div $arg2
$arg1 div $arg2 as xs:numeric?
Rules:
For the four types xs:float, xs:double, xs:decimal and xs:integer, it is guaranteed that if the type of $arg is an instance of type T then the result will also be an instance of T. The result may also be an instance of a type derived from one of these four by restriction. For example, if $arg is an instance of xs:decimal then the result may be an instance of xs:integer.
Sample:
The expression (10) div (3) returns 3.
The expression (-3) div (-2) returns 1.5.
The expression (-3) div (2) returns -1.
The expression (-3.5) div (3) returns 0.7.
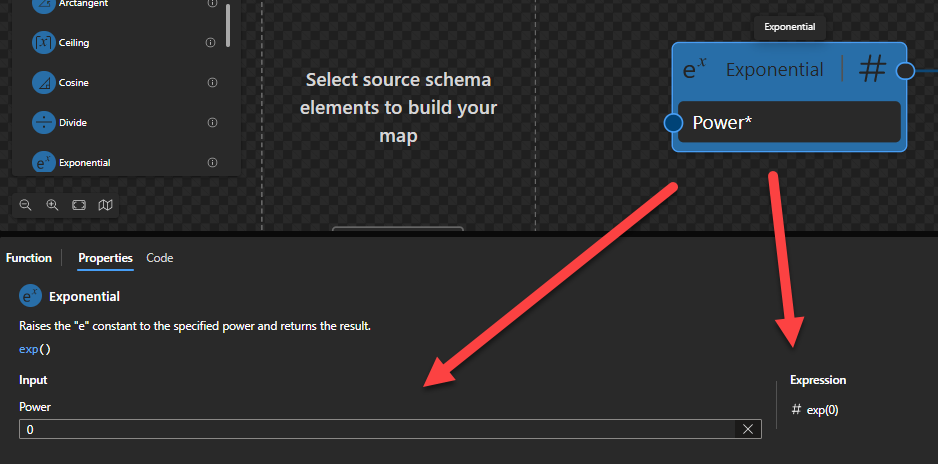
Exponential
This function states that it will raise the “e” constant to the specified power and returns the result.
Behind the scenes, this function is translated to the following XPath function: math:exp($arg)
math:exp($arg as xs:double?) as xs:double?
Rules:
Returns the value of e
Sample:
The expression math:exp(0) returns 1.
The expression math:exp(1) returns 2.7182818284590455.
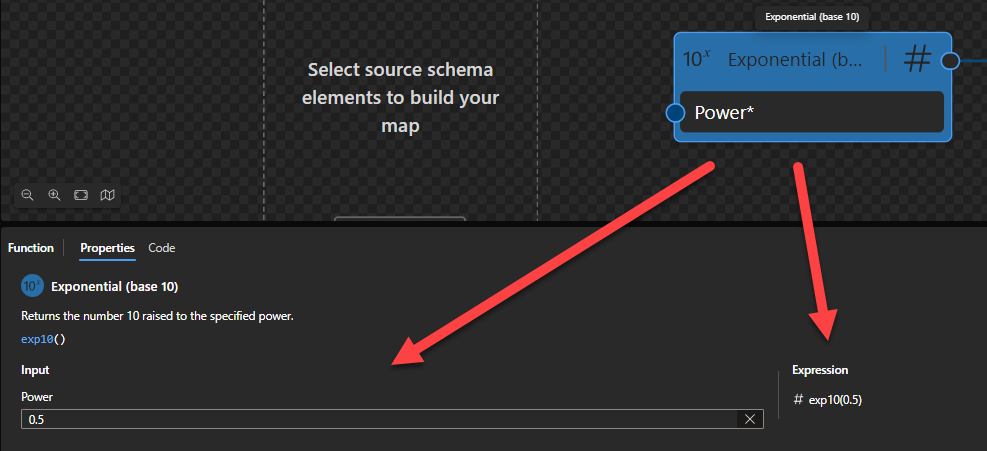
Exponential (base 10)
This function states that it will return the number 10 raised to the specified power.
Behind the scenes, this function is translated to the following XPath function: math:exp10($arg)
math:exp10($arg as xs:double?) as xs:double?
Rules:
Returns the value of 10
Sample:
The expression math:exp10(0) returns 1
The expression math:exp10(1) returns 1.0e1.
The expression math:exp10(0.5) returns 3.1622776601683795
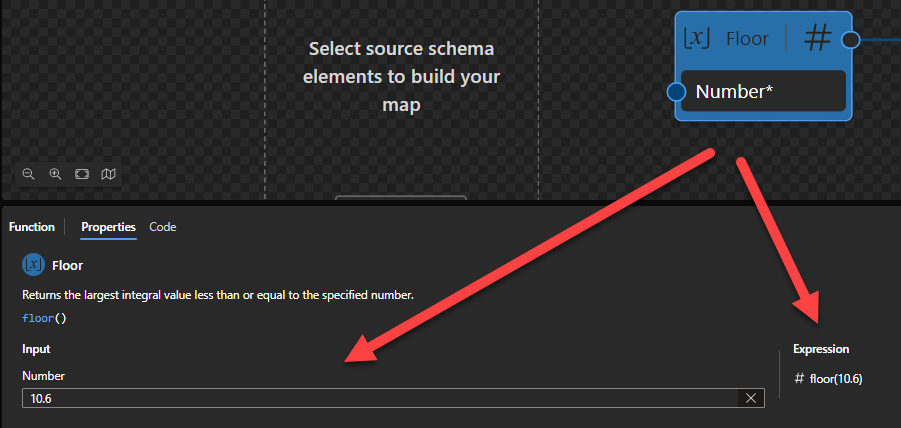
Floor
This function states that it will return the largest integral value less than or equal to the specified number.
Behind the scenes, this function is translated to the following XPath function: floor($arg)
fn:error($code as xs:QName?, $description as xs:string) as none
Rules:
The function returns the largest (closest to positive infinity) number with no fractional part that is not greater than the value of $arg.
For the four types xs:float, xs:double, xs:decimal and xs:integer, it is guaranteed that if the type of $arg is an instance of type T then the result will also be an instance of T. The result may also be an instance of a type derived from one of these four by restriction. For example, if $arg is an instance of xs:decimal then the result may be an instance of xs:integer.
Sample:
The expression fn:floor(10.5) returns 10.
The expression fn:floor(10.9) returns 10.
The expression fn:floor(-10.5) returns -11.
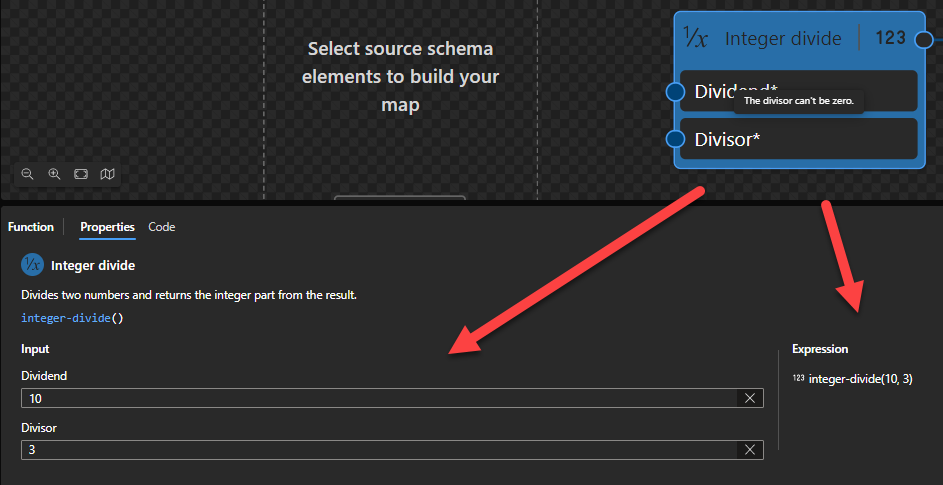
Integer divide
This function states that it will divide two numbers and returns the integer part from the result.
Behind the scenes, this function is translated to the following XPath expression: ($arg1) idiv ($arg2)
($arg1) idiv ($arg2) as xs:integer
Rules:
Performs an integer division.
For the four types xs:float, xs:double, xs:decimal and xs:integer, it is guaranteed that if the type of $arg is an instance of type T then the result will also be an instance of T. The result may also be an instance of a type derived from one of these four by restriction. For example, if $arg is an instance of xs:decimal then the result may be an instance of xs:integer.
Sample:
The expression (10) idiv (3) returns 3.
The expression (-3) idiv (-2) returns 1.
The expression (-3) idiv (2) returns -1.
The expression (-3.5) idiv (3) returns -1.
Stay tune for the second part of this blog post.
Hope you find this helpful! So, if you liked the content or found it useful and want to help me write more, you can buy (or help buy) my son a Star Wars Lego!
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc.
He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community.
View all posts by Sandro Pereira
Utility functions are used to perform a variety of additional and distinct operations that don’t fit in the above Categories, such as stopping a transformation and returning the specified error code and description or format, etc.
Available Functions
The Utility functions are:
Copy: Copies any and all of the input’s substructure.
Error: Stops a transformation and returns the specified error code and description.
Format date: Returns a date in the specified format.
Format number: Returns a number in the specified format.
Format time: Returns a time in the specified format.
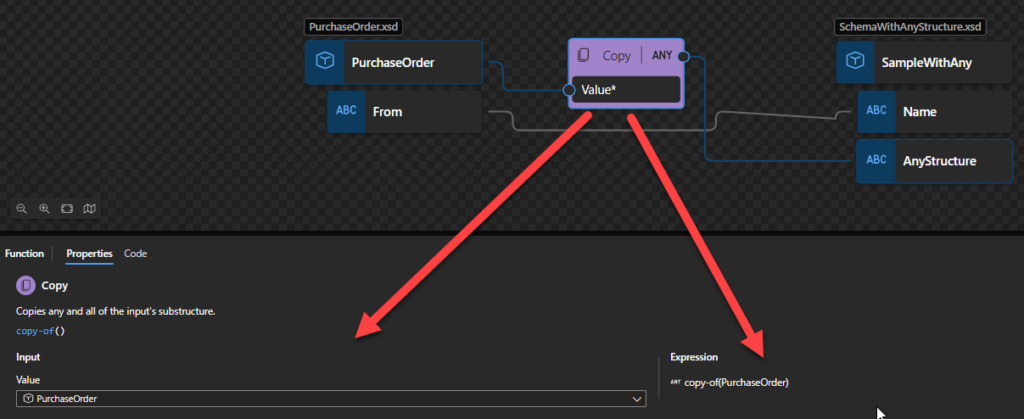
Copy
This function states that it will copy any and all of the input’s substructure. It enables your maps to use schemas that include any and anyAttribute elements. These elements are, in essence, wildcards provided in the Schema definition language to match unknown structures or attributes.
The following figure shows the Copy function used in a map.
Behind the scenes, this function is translated to the following XPath expression: copy-of($arg)
Rules:
The Copy function copies the element in the input instance message corresponding to the source schema node connected to the Copy function. The function also copies any and all of its substructure and re-creates it in the output instance message at the linked node in the destination schema. Thus, you can also use the Copy function to copy any source and destination records having identical substructures.
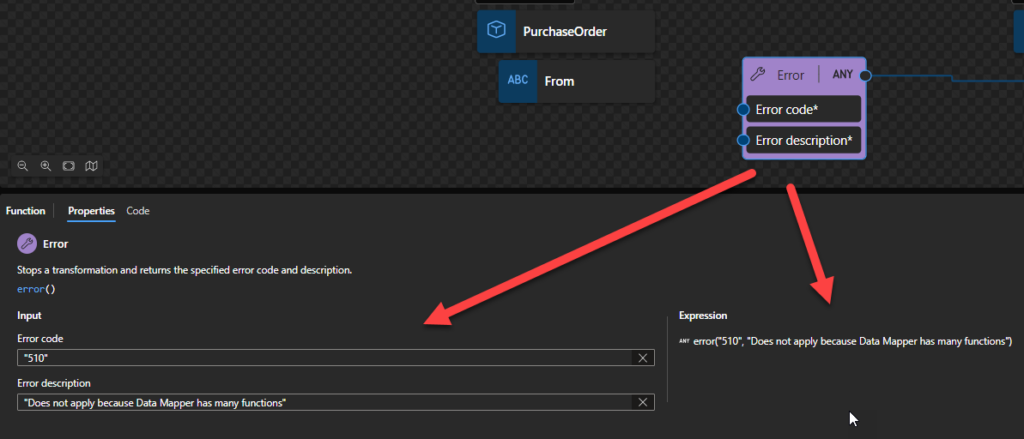
Error
This function states that it will stop a transformation and returns the specified error code and description.
Behind the scenes, this function is translated to the following XPath function: error($code, $description)
fn:error($code as xs:QName?, $description as xs:string) as none
Rules:
Calling the fn:error function raises an application-defined error.
This function never returns a value. Instead, it always raises an error. The effect of the error is identical to the effect of dynamic errors raised implicitly, for example, when an incorrect argument is supplied to a function.
The $code is an error code that distinguishes this error from others. It is an xs:QName; the namespace URI conventionally identifies the component, subsystem, or authority responsible for defining the meaning of the error code, while the local part identifies the specific error condition. The namespace URI http://www.w3.org/2005/xqt-errors is used for errors defined in this specification; other namespace URIs may be used for errors defined by the application.
The $description is a natural-language description of the error condition.
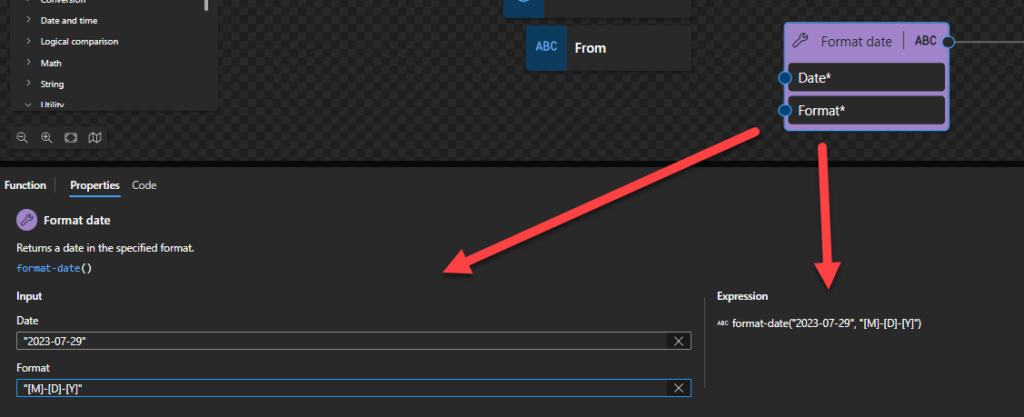
Format date
This function states that it returns a date in the specified format.
Behind the scenes, this function is translated to the following XPath function: format-date($arg1, $arg2)
fn:format-date($value as xs:date?, $picture as xs:string) as xs:string?
Rules:
The $arg1 needs to be an xs:date in the following format yyyy-MM-DD or yyyy-MM-DDZ.
The $arg2 (or picture) consists of a sequence of variable markers and literal substrings. A substring enclosed in square brackets is interpreted as a variable marker; substrings not enclosed in square brackets are taken as literal substrings. The literal substrings are optional and, if present, are rendered unchanged, including any whitespace. The variable markers are replaced in the result by strings representing aspects of the date and/or time to be formatted. These are described in detail below:
Y – year (absolute value);
M – month in the year
D – day in the month
d – day in the year
F – day of the week
W – week in year
w – week in the month
C – calendar: the name or abbreviation of a calendar name
E – era: the name of a baseline for the numbering of years, for example, the reign of a monarch
Sample:
The expression fn:format-date($d, “[Y0001]-[M01]-[D01]”) returns 2002-12-31
The expression fn:format-date($d, "[M]-[D]-[Y]") returns 12-31-2002.
The expression fn:format-date($d, "[D1] [MI] [Y]") returns 31 XII 2002.
The expression fn:format-date($d, “[D1o] [MNn], [Y]”) returns 31st December, 2002
The expression fn:format-date($d, "[D01] [MN,*-3] [Y0001]") returns 31 DEC 2002.
The expression fn:format-date($d, "[YWw]") returns Two Thousand and Three.
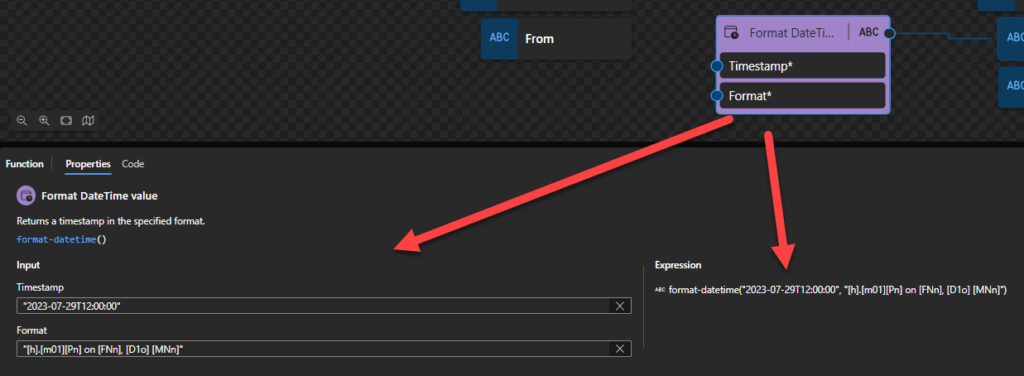
Format DateTime value
Returns a timestamp in the specified format.
This function states that it returns the specified value as an integer.
Behind the scenes, this function is translated to the following XPath function: format-dateTime($arg1, $arg2)
fn:format-dateTime($value as xs:dateTime?, $picture as xs:string) as xs:string?
Rules:
The $arg1 needs to be an xs:dateTime in the following format yyyy-MM-DDTHH:mm:ssZ or yyyy-MM-DDTHH:mm:ss-hh:mm.
The $arg2 (or picture) consists of a sequence of variable markers and literal substrings. A substring enclosed in square brackets is interpreted as a variable marker; substrings not enclosed in square brackets are taken as literal substrings. The literal substrings are optional and, if present, are rendered unchanged, including any whitespace. The variable markers are replaced in the result by strings representing aspects of the date and/or time to be formatted. These are described in detail below:
Y – year (absolute value);
M – month in the year
D – day in the month
d – day in the year
F – day of the week
W – week in year
w – week in the month
H – hour in the day (24 hours)
h – hour in half-day (12 hours)
P – am/pm marker
m – minute in the hour
s – second in a minute
f – fractional seconds
Z – timezone
z – timezone (same as Z, but modified where appropriate to include a prefix as a time offset using GMT, for example, GMT+1 or GMT-05:00. For this component, there is a fixed prefix of GMT or a localized variation thereof for the chosen language, and the remainder of the value is formatted as for specifier Z. 01:01
C – calendar: the name or abbreviation of a calendar name
E – era: the name of a baseline for the numbering of years, for example, the reign of a monarch
Sample:
The expression fn:format-dateTime($dt, “[h].[m01][Pn] on [FNn], [D1o] [MNn]”) returns 3.58pm on Tuesday, 31st December
The expression fn:format-date($d, "[M]-[D]-[Y]") returns 12-31-2002.
The expression fn:format-dateTime($dt, "[M01]/[D01]/[Y0001] at [H01]:[m01]:[s01]") returns 12/31/2002 at 15:58:45.
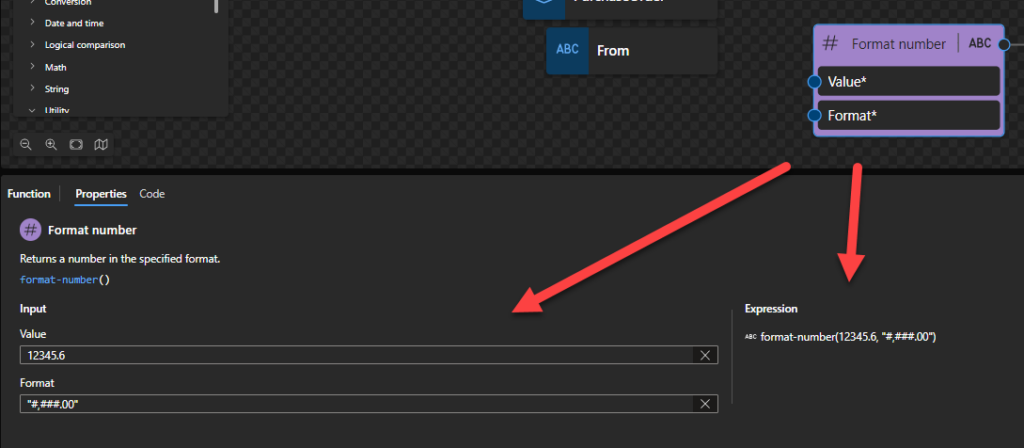
Format number
Returns a number in the specified format.
This function states that it returns the specified value as an integer.
Behind the scenes, this function is translated to the following XPath function: format-number($arg1, $arg2)
fn:format-number($value as xs:numeric?, $picture as xs:string) as xs:string
Rules:
Returns a string containing a number formatted according to a given picture string, taking account of decimal formats specified in the static context.
The $arg1 maybe of any numeric data type (xs:double, xs:float, xs:decimal, or their subtypes, including xs:integer).
Sample:
The expression format-number(12345.6, '#,###.00') returns "12,345.60".
The expression format-number(12345678.9, '9,999.99') returns "12,345,678.90".
The expression format-number(123.9, '9999') returns "0124".
The expression format-number(0.14, '01%') returns "14%".
The expression format-number(-6, '000') returns "-006".
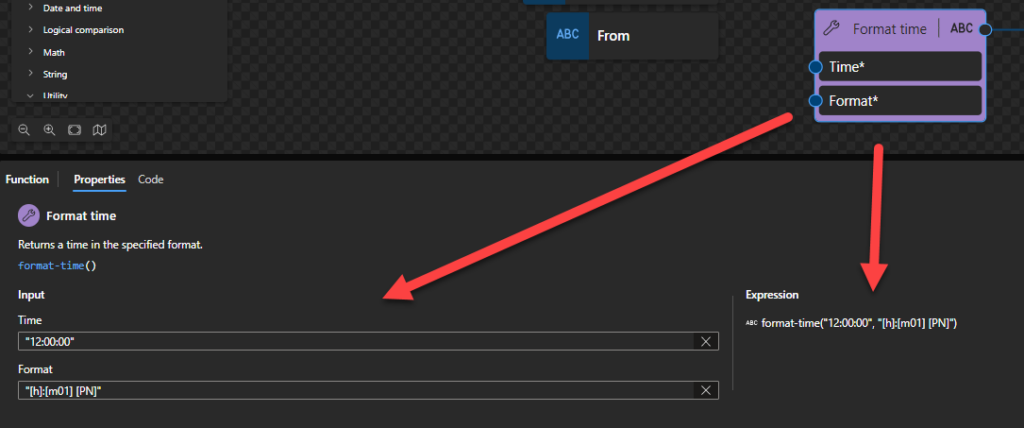
Format time
Returns a time in the specified format.
This function states that it returns the specified value as an integer.
Behind the scenes, this function is translated to the following XPath function: format-time($arg1, $arg2)
fn:format-time($value as xs:time?, $picture as xs:string) as xs:string?
Rules:
The $arg1 needs to be an xs:time in the following format HH:mm:ssZ or HH:mm:ss-hh:mm.
The $arg2 (or picture) consists of a sequence of variable markers and literal substrings. A substring enclosed in square brackets is interpreted as a variable marker; substrings not enclosed in square brackets are taken as literal substrings. The literal substrings are optional and, if present, are rendered unchanged, including any whitespace. The variable markers are replaced in the result by strings representing aspects of the date and/or time to be formatted. These are described in detail below:
H – hour in the day (24 hours)
h – hour in half-day (12 hours)
P – am/pm marker
m – minute in the hour
s – second in a minute
f – fractional seconds
Z – timezone
z – timezone (same as Z, but modified where appropriate to include a prefix as a time offset using GMT, for example, GMT+1 or GMT-05:00. For this component, there is a fixed prefix of GMT or a localized variation thereof for the chosen language, and the remainder of the value is formatted as for specifier Z. 01:01
C – calendar: the name or abbreviation of a calendar name
E – era: the name of a baseline for the numbering of years, for example, the reign of a monarch
Sample:
The expression fn:format-time($t, “[h]:[m01] [PN]”) returns 3:58 PM
The expression fn:format-time($t, "[h]:[m01]:[s01] [PN] [ZN,*-3]") returns 3:58:45 PM PDT.
The expression fn:format-time($t,”[H01]:[m01]:[s01] [z,6-6]”) returns 15:58:45 GMT+02:00.
Hope you find this helpful! So, if you liked the content or found it useful and want to help me write more, you can buy (or help buy) my son a Star Wars Lego!
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc.
He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community.
View all posts by Sandro Pereira