Do you feel difficult to keep up to date on all the frequent updates and announcements in the Microsoft Integration platform and Azure iPaaS?
Integration weekly updates can be your solution. It’s a weekly update on the topics related to Integration – enterprise integration, robust & scalable messaging capabilities and Citizen Integration capabilities empowered by Microsoft platform to deliver value to the business.
Building an application with different deployment models, resources, and tools in Azure is not the end of the road. The ultimate goal of end-user experience, sustainability, and increased visibility could be achieved only with observability.
There are a lot of different tools available in the market. Azure has built-in tools, but many third-party solutions are available that stay on top of the native tooling to advance the observability functionality.
Today, I’ll take you through the common traits among the available tools and what you should consider while choosing an Azure observability tool.
What is the difference between monitoring and observability?
Before I go deep into observability, I would provide better clarity about its supplementary compatriot, monitoring. In fact, observability and monitoring are tightly connected, and you cannot achieve observability without monitoring.
Let us understand what they are, why they are essential, and when they are crucial to consider in your Azure ecosystem.
Monitoring
A monitoring system or tool actively tracks your application and continuously assesses it for any anomalies, flaws, or problems.
Monitoring gathers metrics and properties from the available sources like APIs and logs.
It passively tracks the performance and the amount of data it generates usually drowns the admin personnel.
Monitoring usually focuses on a point observation like integrations, infrastructure, and networks.
The data available through monitoring is often considered the final expected outcome.
Observability
The data collected from monitoring, like metrics and properties, set the base for observability. While monitoring focuses on incident reporting, observability provides insights into why the issue happened.
It collects various data like metrics, logs, and traces, which sets up the system to extract crucial insights into why things are happening.
It provides refined information after processing various data sources that pinpoint the exact root cause of the issue or incident.
Observability holistically focuses on both application and infrastructure to identify the root cause.
It collects data from sources contributing to the analytical process, representing the incident state.
At the bottom line, while many observability tools are available in the market, all of them have a shared data source platform: Azure Monitor.
Can you achieve better observability with Azure Monitor?
While Azure monitor could only generate metrics and logs, the users cannot achieve the advanced version of the monitoring, which is observability.
The platform should be able to refine various data sources like metrics, logs, and traces to focus on the relevant data, such as the factors that drive operations decisions and actions to fix incidents faster.
What should you consider while choosing an observability tool?
While many third-party and open-source solutions in the market utilize Azure Monitor export API to provide an upgraded experience beyond the threshold determined by the Azure cloud, I will explain the critical features that are expected to be present in any observability tool.
Analyze and predict anomalies in Azure
Leveraging custom algorithms to predict anomalies in Azure resources allows users to be proactive with critical performance issues. In addition, it correlates issues across hybrid and microservice architecture.
Real-time dependency mapping
This provides a sufficient view of the resources as a Line of Business Applications. Users can derive relationships between the resources that comprise the Business Application using this as a physical representation of the architecture with real-time health status.
Business KPI dashboard
Ability to auto-populate the dashboards that aggregates and presents the data to show the business goal achievements and bottlenecks.
Deep Analytical tool
Without switching between tabs, drill down into Azure services, components, or parameters using robust in-built tools to identify root causes.
Automatic remediation
The advanced automation capabilities help fix trivial incidents that may not require manual intervention.
List of Azure Observability Tools
Given the volume of tools available in the market, it might be daunting to compare every product and choose the wise one that suits your needs. Hence, we have hand-picked the top 5 observability tools that have advanced capabilities.
#1 Serverless360 (Best Overall)
Serverless360 is best for achieving advanced observability and end-to-end correlation tracking.
Serverelss360 is the provider of advanced monitoring and observability. It advances observability with contextual information, end-to-end correlation, and automation. It helps remove blind spots, resolve issues rapidly with minimal MTTR and deliver a superior customer experience.
It extends the three core pillars of observability with a topology map that correlates the dependencies between applications to provide contextual information.
It provides actionable answers rather than just producing severity alerts which could be more helpful. With advanced automation, you can ensure high scalability by auto-remediating trivial issues without manual intervention.
Features
Contextual information from the observed data about business goals impact
Precise answers to reduce Mean time to recovery
End-to-end correlation between the Azure service dependencies
Service map to get the real-time health status of the application architecture
Granular user access permission and team collaboration
Desperate notification channels like slack, service now, teams, and more
Price
Its base price starts at $150/month for 25 Azure resources. You can try their 15 days free trial.
#2) Dynatrace
Dynatrace is a comprehensive enterprise SaaS tool for a wide range of enterprise monitoring needs. Distributed Tracing provides a technology called Purepath that combines distributed tracing with code-level insight.
Features:
Automatic injection and collection of data
Code-level visibility across all application tiers for web and mobile apps together
Always-on code profiling and diagnostics tools for application analysis
#3) SigNoz
SigNoz is a full stack open source APM and observability tool. Collect both metrics and traces with log management, currently included in the product roadmap. Logs, metrics, and traces are considered the three pillars of observability in modern distributed systems.
Features:
User requests per second
50th, 90th, and 99th percentile latencies of microservices in your application
Error rate of requests to your services
#4) Honeycomb
Honeycomb is a full-stack cloud-based observability tool with support for events, logs, and traces. It provides easy to use UI for unified observability and some of its features includes:
Features:
Quickly diagnose issues and tweak performance with a top down approach to understand how your system is processing service requests
Full-text search over trace spans and toggle to collapse and expand sections of trace waterfalls
Provides Honeycomb beelines to automatically define key pieces of trace data like serviceName, name, timestamp, duration, traceID, etc.
#5) Datadog
DataDog is an enterprise APM tool that offers a variety of monitoring products from infrastructure monitoring, log management, network monitoring to security monitoring.
Features:
Out of box performance dashboards for web services, queues, and databases to monitor requests, errors, and latency
Correlation of distributed tracing to browser sessions, logs, profiles, network, processes, and infrastructure metrics
Can ingest 50 traces per second per APM host
Service maps to understand service dependencies
Observability in Azure: Wrap up
Many tools are available at your disposal, while Azure Monitor is a solid out-of-the-box place to start if your organization decides to work with Azure. But at scale, you may need advanced and custom functionalities that go beyond the limitations of the native tool to help you understand the health of your application at a glance which will keep your business up and running.
The post Top 5 Azure Observability Tools in 2023 appeared first on Steef-Jan Wiggers Blog.
In today’s world, APIs have definitely advanced the way how applications communicate with each other. However, when several APIs are utilized in a business scenario, it would be challenging to retain insight into each API to make sure they work as intended.
This is where an Azure service like API Management turns out to be a significant aspect. It offers a centralized interface to publish, transform and manage numerous APIs, guaranteeing that they are secure and consumable.
Significance of Monitoring your Azure APIM
Since Azure APIM instances manage such business-critical APIs, monitoring them and their operations is crucial to better know their health and efficiency. Here are the top benefits that can be achieved with Azure APIM Monitoring,
Eliminate Bottlenecks:?Monitoring how your APIM APIs and Products (group of one or more APIs) perform is essential to quickly spot problems that might adversely affect the end-user experience.
Reduce latency gaps: API response time has a profound effect on the performance of an application. So with APIM monitoring, get to identify in case of response time delays, thereby eliminating latency gaps.
Ensure availability: When there are any API-related issues, an effective APIM monitoring setup will send instant alerts, allowing you to take the required remedial actions.
Detect failure anomalies: Rapidly figure out if there are outages or abnormal deviations like sudden rise in the rate of failed requests.
Understanding the importance, Azure itself offers its own suite of built-in tools for monitoring Azure APIM Instances.
Wide range of monitoring options available for Azure APIM
Native-Azure monitoring tools (Azure Monitor)
Azure Monitor is one of the primary built-in tools for monitoring Azure APIM instances. Basically, it enables the collection of metrics and logs from APIM, which can be further used for monitoring, visualizing, and alerting.
Capabilities
Monitor your APIM Instances on metrics like capacity and request rate
Set up alert rules based on metrics to get notified of critical issues
Provides dashboards for visualizing monitoring metrics
Get insights into the operations performed on your APIM Instances with Activity logs
Integration with App Insights lets you know the dependencies between APIM instances and other services.
Moreover, Azure Monitor focuses more on reactive monitoring – you get to react only after an incident has occurred.
But when it comes to APIM monitoring, business tends to be more proactive, constantly attempting to spot and fix potential issues before they have an impact on end users.
The limitations in using Azure Monitor for APIM
Azure Monitor allows you to configure only a limited number of metrics per alert rule
Monitoring an APIM instance on various metrics demands configuring a number of alerts, resulting in a cost spike.
No consolidated error reporting for multiple APIM instances
Doesn’t support visualizing how an API call traverses through various Azure services
It would be hard to perform root cause analysis in case of a performance or latency issue without end-to-end tracing.
Lack of automated features to execute remedial actions without manual intervention
This is where the necessity of having enterprise-grade monitoring tools comes in place. One such tool that can assist you in overcoming the above-listed drawbacks and help proactively monitor your Azure APIM is Serverless360.
How to be proactive and overcome limitations in Azure Monitor?
Serverless360 is an advanced cloud management platform that enables managing and monitoring different Azure services involved in your application from a unified view.
Considering APIs are critical in simplifying how an end user interacts with your application, Serverless360 offers out-of-the-box monitoring support for Azure APIM APIs, operations, and products.
Here is how Serverless360 can be extensively used for Azure APIM Monitoring.
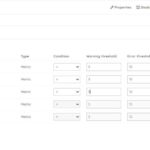
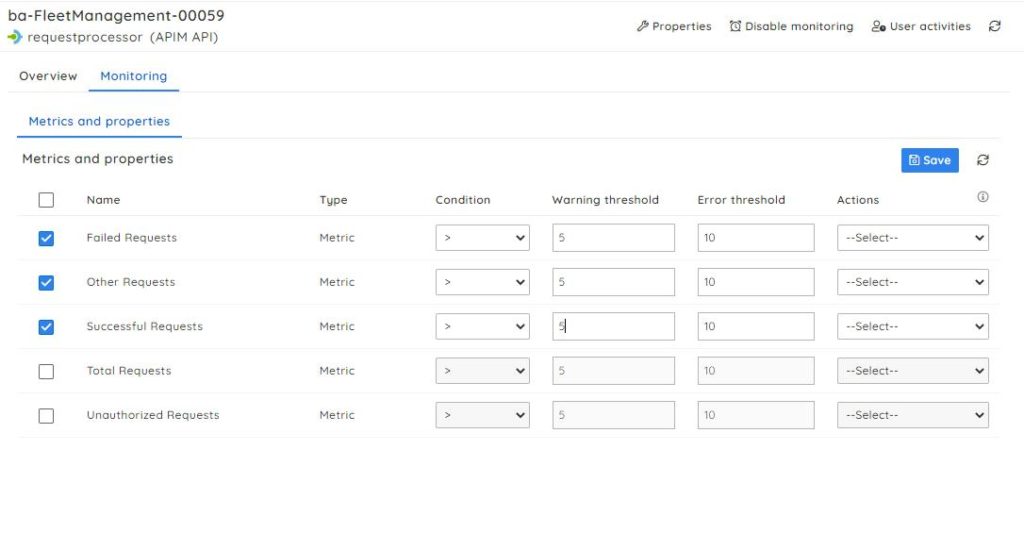
Proactive monitoring for Azure APIM: Monitor all your APIM instances on multiple metrics and properties (Failed Requests, Successful Requests, etc) at no additional cost by setting up maximum thresholds to get an alert whenever there is a violation.
With this, get to overcome one of the major limitations in Azure Monitor – The restriction to monitor only countable metrics under a single alert.
Real-time consolidated error reports: In any sort of traditional monitoring, error reports will be generated for each APIM API, operation, or product, making it very difficult to identify the root cause of an issue.
But Serverless360 can mitigate the challenge by sending you a consolidated report on all the APIM Instances at desired time intervals, eliminating false or alert storms.
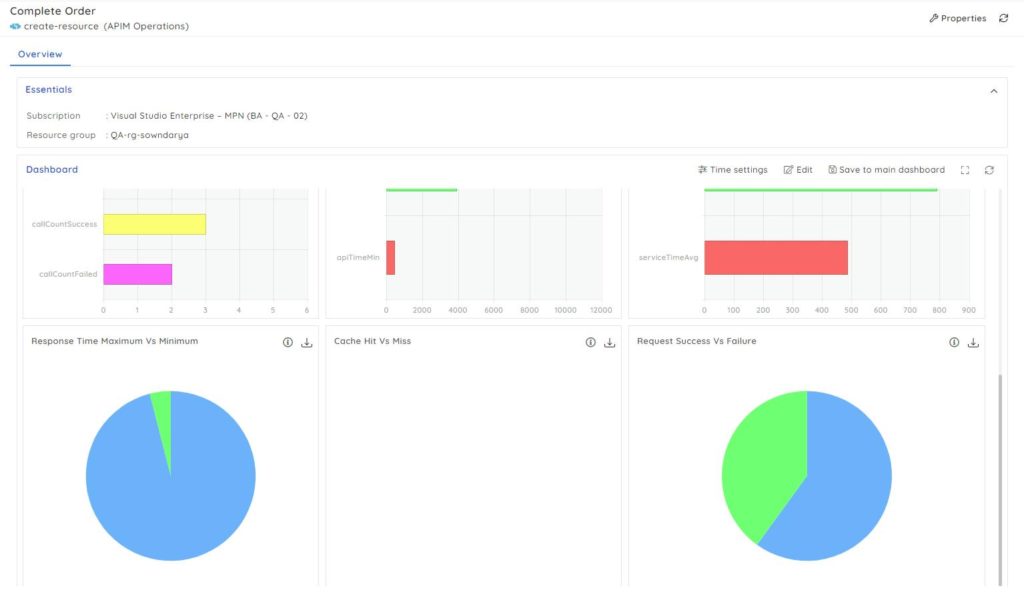
Discover failure trends: Serverless360 offers customizable, plug-and-play dashboards to provide a unified view of the metrics monitored. For instance, Visualize business-centric metrics like the response rates of APIs in a single place to avoid latency issues.
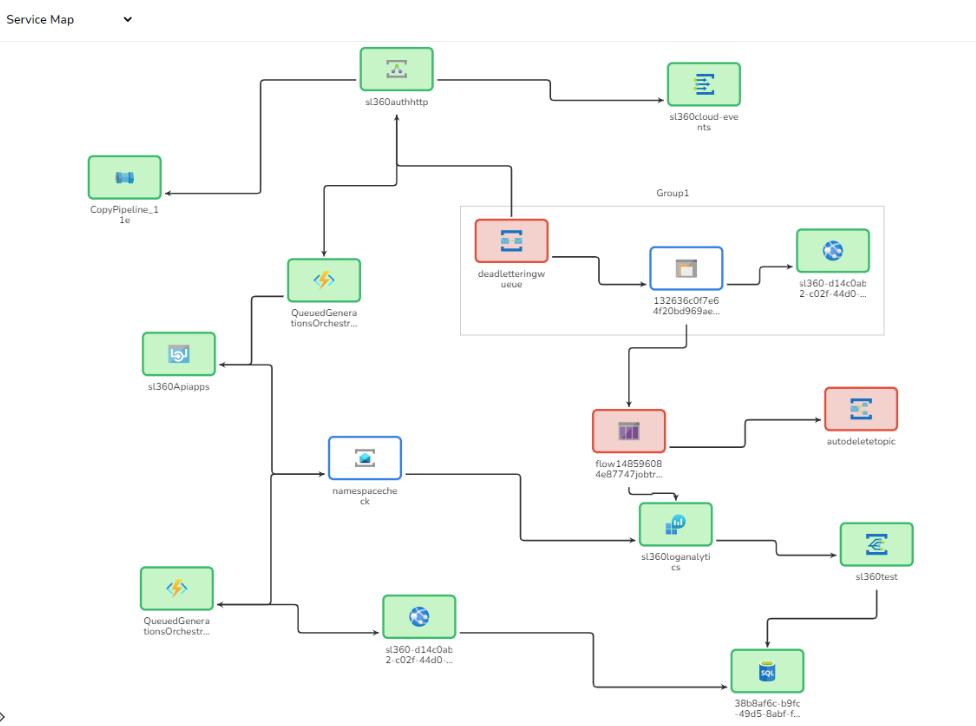
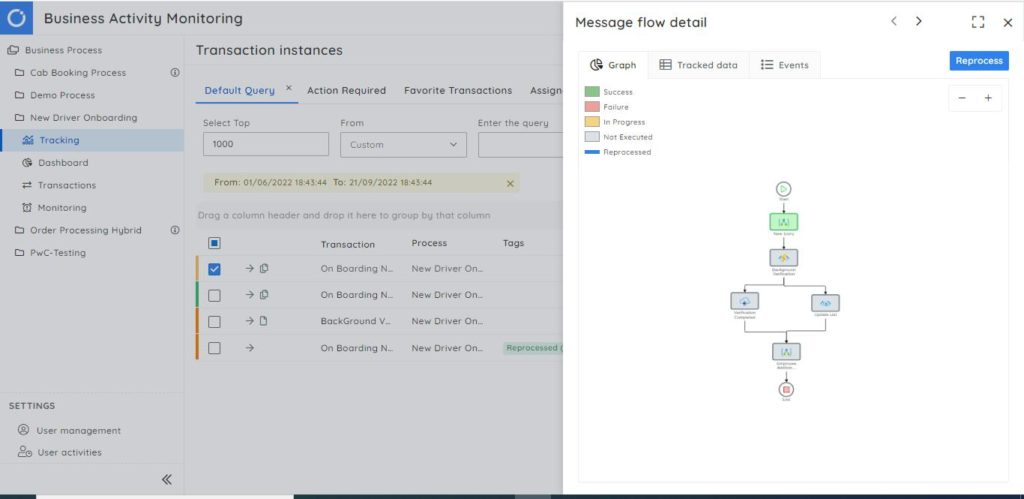
End-to-end tracking: An Azure application will have various Azure services along with other APIM Instances, so tracking how an API call flows through each of those services is required to perform root cause analysis and troubleshoot issues faster than ever.
App Insights in Azure Monitor just lets you visualize how services interact with each other whereas Serverless360 supports end-to-end tracking along with dependency mapping.
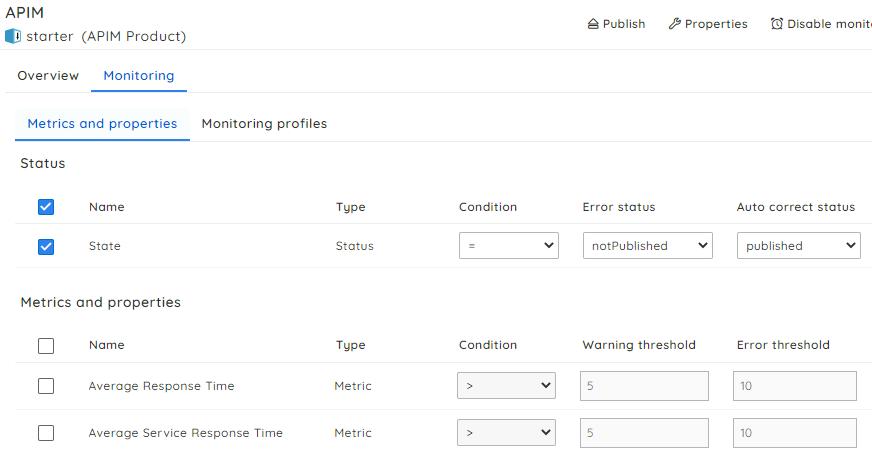
Auto-correct the status of APIM Products: Automationis very crucial to reduce themanualworkloadinvolved in resolving recurring incidents.
Serverless360 offers unique functionality to monitor the status of APIM products and auto-correct them during unintended interruptions. Also, it lets you configure various automated actions to be triggered whenever there is a threshold violation.
Optimize costs associated with APIM Instances: Save time and cost by auto-generating documentation on your entire Azure environment/infrastructure. These documents help keep track of the costs associated with your APIM APIs, operations, and products. They enable you to compare the costs incurred across various time periods and to gain a full analysis of the expenditures made for each of those components.
No room for security breaches: Understanding the importance of governance and auditing in enhancing security, Serverless360 comes with features to audit every action performed on your APIM instances and enable advanced role-based access control.
Decode App Insights and Log Analytics: Enabling App Insights and Log Analytics can derive useful data on the APIM performance, however, Serverless360 can make this information more usable to the support team. Refer to this blog to learn more: Serverless360 to enable your Security Manager to Azure WAF data
Offload support: Serverless360 offers an operation-friendly interface simple and straightforward for support users to infer the status of the resource and remediate identified issues. This can facilitate offloading support from the Azure team allowing them to innovate in business.
Conclusion
Having a solid tool for Azure APIM monitoring is mandatory for any organization, as the failure of an API could result in critical performance issues for the whole application.
But there are plenty of choices available for Azure APIM monitoring and it is important that you choose the most apt one for your business. Thus, this blog discusses the features of native-Azure monitoring tools, their drawbacks, and a solution (Serverless360) to overcome them with consolidated monitoring for Azure APIM APIs, Products, and Operations.
The post Azure API Management Monitoring and Alerting made simpler appeared first on Steef-Jan Wiggers Blog.
Do you feel difficult to keep up to date on all the frequent updates and announcements in the Microsoft Integration platform and Azure iPaaS?
Integration weekly updates can be your solution. It’s a weekly update on the topics related to Integration – enterprise integration, robust & scalable messaging capabilities and Citizen Integration capabilities empowered by Microsoft platform to deliver value to the business.
You may already know that I usually use the series A fish out of water when I want to write something that goes a little bit off-topic on my main blog topic: Enterprise Integration. This time is not an Enterprise Integration topic but is somehow related to it since we are going to learn a possible way to try or troubleshoot SMTP issues that can be used as a channel on our integration solutions.
While working with BizTalk Server, sometimes I had the need to send email notifications or send messages thru email. In some cases, we use Office365 accounts to authenticate on the SMTP Server and send emails thru that account, but in some cases, we may have an internal SMTP Server with anonymous authentication that doesn’t require any account to send emails or a valid email to specify on the from. Of course, normally, that doesn’t mean that it is an “open bar” where everyone can send emails from and to anywhere they want. You should find some limitations thru other types of setting you can perform on the SMTP server or in the network layer like:
Only specific machines can access and send emails thru that SMTP Server.
You can only use a specific sender, or you can only send emails internally to the organization.
and so on.
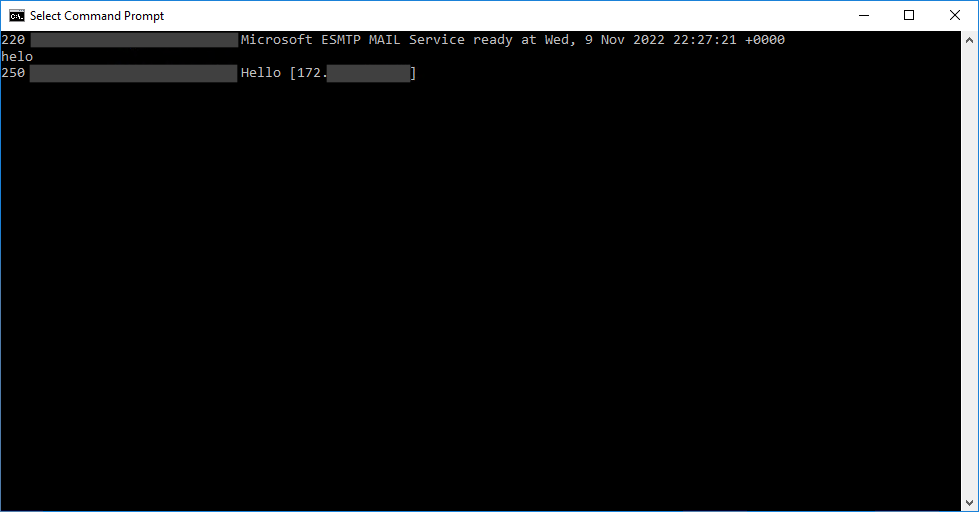
To try to see if everything is set up correctly before you use BizTalk Server, for example, or even thru troubleshooting errors, you can try to send an email thru the Command Prompt. To do that, you need to:
Open Command Prompt using Start > Command Prompt or via Run > cmd
You then need to do a telnet to the mail server by typing telnet <domain> <port> (usually, it is 25) and then pressing Enter.
Once connected, we must initiate the mail-sending process by typing helo
The server will reply with 250 and Hello if successful.
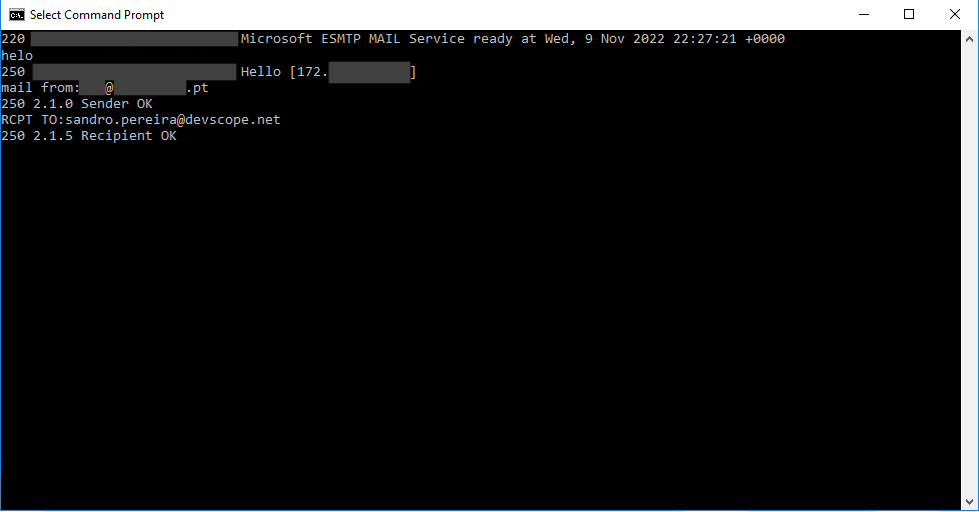
We now need to specify the sending mail address by typing mail from:<email address> and then pressing Enter.
The server will reply with 250 if it is a valid sender.
After that, we specify the recipients by typing RCPT TO:<email address> and then pressing Enter.
The server will reply with 250 if it is a valid receiver.
Most of the time, if errors exist, you will find them in this first part of the process.
Now to actually send an email, you need to:
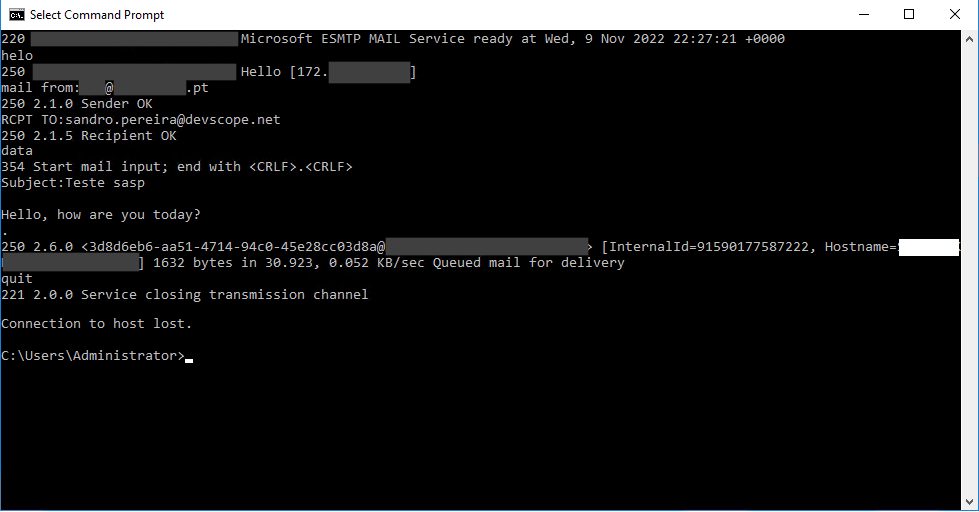
Type data and press ENTER to begin the email content.
We first need to set the subject of the email by typing Subject:<Your Subject> and then pressing Enter twice.
Now start typing the message content of your email.
To finish and close the message, do the following sequence
Press Enter
Type . (Period Key)
and press Enter again.
You may then receive a server response saying, for example, that the mail was queued for delivery.
Type Quit and press Enter to exit telnet.
Now you just need to verify if your email was received.
Continuous integration/continuous delivery (CI/CD) pipelines are a practice focused on improving software delivery using a DevOps approach.?
A CI/CD pipeline may sound like overhead, but it isn’t. It’s essentially a runnable specification of the steps that any developer needs to perform to deliver a new software product version. In the absence of an automated pipeline, Engineers would still need to perform these steps manually and, therefore, be far less productive.
This is a must to have when deploying resources to Azure! Especially for non-development environments.
In this whitepaper, I will address and explain in a detailed way a complete guide for automating the implementation of Logic Apps Standard using Azure DevOps Pipelines.
I will explain in detail all the basic things you have to know, from the creation of a Logic App Standard on Visual Studio Code to everything you need to create and configure inside DevOps to archive the implementation of the CI/CD process.
What’s in store for you?
This whitepaper will give you a detailed understanding of the following:
An introduction to:
What are Continuous Integration (CI) and Continuous Deployment (CD)?
What are CI/CD Pipelines?
What is Azure DevOps?
Create an organization or project collection in Azure DevOps
Create a project in Azure DevOps
Building your Logic App Standard from scratch
Publish your code from Visual Studio Code
A step-by-step approach to building Azure Pipelines
A step-by-step approach to building Azure Release Pipelines
As service instances (receive ports, orchestrations, send ports) process messages moving through BizTalk Server, these service instances can be in one of several states.
In Breakpoint: An active orchestration hits a breakpoint, typically one set by a BizTalk Server solutions developer. This state is valid only for orchestrations.
Ready to run: A service instance that has been activated but has not yet started running, typically due to temporary unavailability of resources, such as a heavy processing load on the server. Active Running service instance.
Dehydrated: The instance state persists in the MessageBox database, and no Windows service is running that instance.
Completed with discarded messages: The service instance was completed, but some messages were not consumed by the instance.
Suspended (resumable): Instance is suspended, you can resume it.
Important: Resuming a messaging instance will do the following:
Resume the messaging instance.
Send the message to the send port. The send port delivers the message to the destination, even if the send port is not in a Started state.
Note that when you suspend a scheduled instance and then resume it, the instance goes into a dehydrated state.
Suspended (not-resumable): The instance is suspended, but you cannot resume it. You can save the Messages referenced by the instance, and then you can terminate the instance.
Note that when you suspend a scheduled instance and then resume it, the instance goes into a dehydrated state.
Pending suspend/Pending terminate: A status, not an independent state. You can combine it with other states.
A control message to suspend or terminate was sent to a service instance but has not yet been picked up by the instance. Only one pending operation is allowed at a time. When an instance with a pending operation becomes dehydrated, you can terminate the instance.
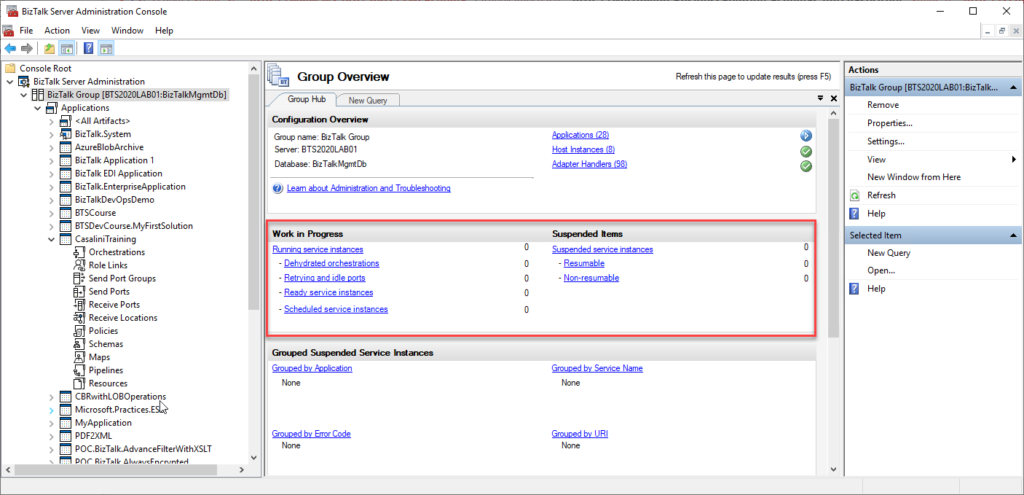
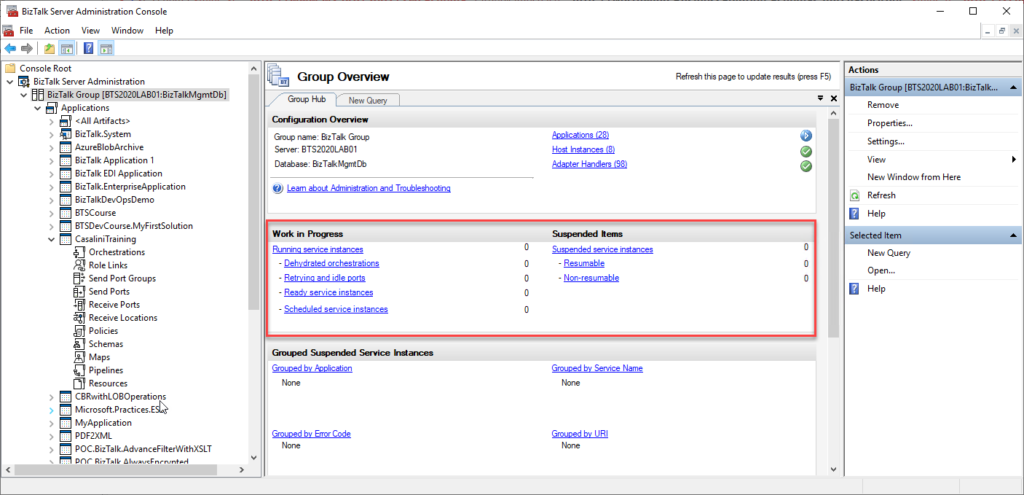
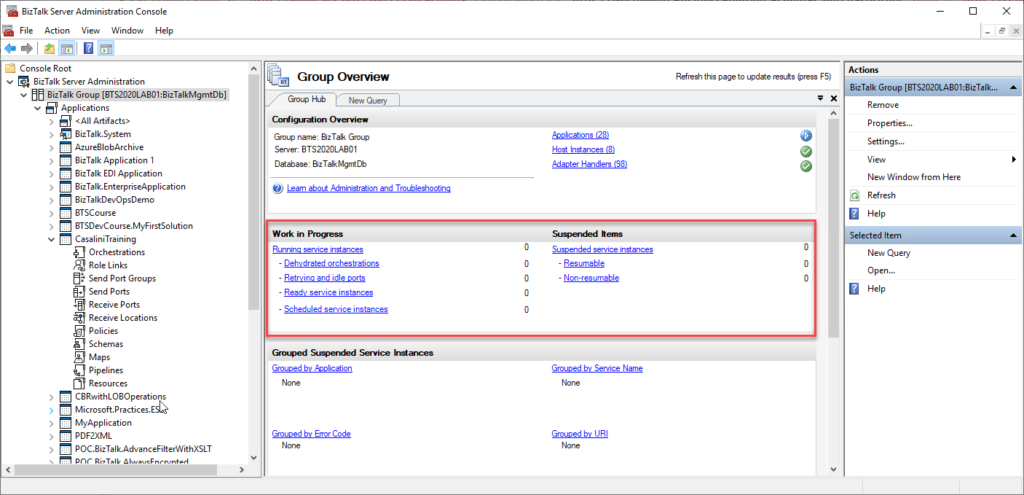
We can see all of these service instances in all different stages inside the BizTalk Server Administration Console:
The problem with the admin console is that it needs manual intervention to check all of this information, so we need to keep clicking F5 each time we want to check them. That is not an effective monitoring operation and quite a waste of human resource time. Of course, there are several other ways to archive this goal:
You can use third-party monitoring tools;
You can use PowerShell to extract this information;
or you can use a simple SQL query.
Well, here is how you do a simple SQL query to count the number of Non-Resumable suspended service instances:
USE BizTalkMsgBoxDb;
SELECT COUNT(nstate) SuspendedNonResumable
FROM Instances WITH (NOLOCK)
WHERE nstate = 3
You need to run this script against BizTalkMsgBoxDB, and it will return the count of instances Suspended that cannot be resumable. Equal to what you see in the BizTalk Server Administration Console.
Do you feel difficult to keep up to date on all the frequent updates and announcements in the Microsoft Integration platform and Azure iPaaS?
Integration weekly updates can be your solution. It’s a weekly update on the topics related to Integration – enterprise integration, robust & scalable messaging capabilities, and Citizen Integration capabilities empowered by the Microsoft platform to deliver value to the business.
As service instances (receive ports, orchestrations, send ports) process messages moving through BizTalk Server, these service instances can be in one of several states.
In Breakpoint: An active orchestration hits a breakpoint, typically one set by a BizTalk Server solutions developer. This state is valid only for orchestrations.
Ready to run: A service instance that has been activated but has not yet started running, typically due to temporary unavailability of resources, such as a heavy processing load on the server. Active Running service instance.
Dehydrated: The instance state persists in the MessageBox database, and no Windows service is running that instance.
Completed with discarded messages: The service instance was completed, but some messages were not consumed by the instance.
Suspended (resumable): Instance is suspended, you can resume it.
Important: Resuming a messaging instance will do the following:
Resume the messaging instance.
Send the message to the send port. The send port delivers the message to the destination, even if the send port is not in a Started state.
Note that when you suspend a scheduled instance and then resume it, the instance goes into a dehydrated state.
Suspended (not-resumable): The instance is suspended, but you cannot resume it. You can save the Messages referenced by the instance, and then you can terminate the instance.
Note that when you suspend a scheduled instance and then resume it, the instance goes into a dehydrated state.
Pending suspend/Pending terminate: A status, not an independent state. You can combine it with other states.
A control message to suspend or terminate was sent to a service instance but has not yet been picked up by the instance. Only one pending operation is allowed at a time. When an instance with a pending operation becomes dehydrated, you can terminate the instance.
We can see all of these service instances in all different stages inside the BizTalk Server Administration Console:
The problem with the admin console is that it needs manual intervention to check all of this information, so we need to keep clicking F5 each time we want to check them. That is not an effective monitoring operation and quite a waste of human resource time. Of course, there are several other ways to archive this goal:
You can use third-party monitoring tools;
You can use PowerShell to extract this information;
or you can use a simple SQL query.
Well, here is how you do a simple SQL query to count the number of Resumable suspended service instances:
USE BizTalkMsgBoxDb;
SELECT COUNT(nstate) SuspendedResumable
FROM Instances WITH (NOLOCK)
WHERE nstate = 4
You need to run this script against BizTalkMsgBoxDB, and it will return the count of instances Suspended that can be resumable. Equal to what you see in the BizTalk Server Administration Console.
As service instances (receive ports, orchestrations, send ports) process messages moving through BizTalk Server, these service instances can be in one of several states.
In Breakpoint: An active orchestration hits a breakpoint, typically one set by a BizTalk Server solutions developer. This state is valid only for orchestrations.
Ready to run: A service instance that has been activated but has not yet started running, typically due to temporary unavailability of resources, such as a heavy processing load on the server. Active Running service instance.
Dehydrated: The instance state persists in the MessageBox database, and no Windows service is running that instance.
Completed with discarded messages: The service instance was completed, but some messages were not consumed by the instance.
Suspended (resumable): Instance is suspended, you can resume it.
Important: Resuming a messaging instance will do the following:
Resume the messaging instance.
Send the message to the send port. The send port delivers the message to the destination, even if the send port is not in a Started state.
Note that when you suspend a scheduled instance and then resume it, the instance goes into a dehydrated state.
Suspended (not-resumable): The instance is suspended, but you cannot resume it. You can save the Messages referenced by the instance, and then you can terminate the instance.
Note that when you suspend a scheduled instance and then resume it, the instance goes into a dehydrated state.
Pending suspend/Pending terminate: A status, not an independent state. You can combine it with other states.
A control message to suspend or terminate was sent to a service instance but has not yet been picked up by the instance. Only one pending operation is allowed at a time. When an instance with a pending operation becomes dehydrated, you can terminate the instance.
We can see all of these service instances in all different stages inside the BizTalk Server Administration Console:
The problem with the admin console is that it needs manual intervention to check all of this information, so we need to keep clicking F5 each time we want to check them. That is not an effective monitoring operation and quite a waste of human resource time. Of course, there are several other ways to archive this goal:
You can use third-party monitoring tools;
You can use PowerShell to extract this information;
or you can use a simple SQL query.
Well, here is how you do a simple SQL query to extract Dehydrated service instances:
USE BizTalkMsgBoxDb;
SELECT COUNT(nstate) Dehydrated
FROM Instances WITH (NOLOCK)
WHERE nstate = 8
You need to run this script against BizTalkMsgBoxDB, and it will return the count of instances Dehydrated. Equal to what you see in the BizTalk Server Administration Console.
 for Full Life Cycle API Management
for Full Life Cycle API Management