
by Gautam | Aug 10, 2016 | BizTalk Community Blogs via Syndication
Bill Chesnut, @BizTalkBill
Bill is Cloud Platform & API Evangelist at SixPivot located in Melbourne Australia. He started his career in 1983 with the US Defense as an IBM Systems Programmer. He switched to the Microsoft Windows platform in 1994, and has been involved with Windows development ever since.
Most recently, Bill has been driving various application integration projects using BizTalk Server 2000, 2002, 2004, 2006 and 2006 R2 to connect a variety of Microsoft Business Solutions applications with other systems. Bill is also a Microsoft Certified Trainer and has been actively training BizTalk developers since the release of BizTalk 2004. He is also a member of the elite Microsoft Virtual Technology Specialist (VTSP) team, a small group of selected industry experts working as an extension to the Microsoft Technology Specialist teams. He is also a Microsoft Integration Microsoft Valuable Professional (MVP)
Bill is very involved in the Microsoft User Group Community as leader of the Melbourne .Net User Group. Bill has also been working closely with Microsoft to run the BizTalk User group in Melbourne. Bill is also the primary organizer of the BizTalk Saturday BizTalk Hands on Days around Australia and New Zealand. Bill also maintain a blog at http://www.biztalkbill.com/
He has also spoke couple of times in Integration User Group – Integration Monday
Last year Bill also delivered sessions in Microsoft Ignite New Zealand and Microsoft Ignite Australia
It’s really great to have him as one of the reviewer of our book– Robust Cloud Integration with Azure. Here is his thoughts about the book.
1. What do you think about the outline of the book?
I think this book will be a great reference for those integration developers moving from on-premises to the cloud and to help those developers already working in the cloud leverage the full Microsoft PaaS Integration stack.
2. What is your expectation from the book or how do you think this book would be valuable for its reader’s time and money?
There are a number of different technologies in Azure and the question always come up about what particular component to use and when to use them, this book should offer some well needed guidance to help answer those question and get integration developers start on the cloud integration journey.
I welcome Bill to our book reviewer team and I am sure his guidance will shape the book to a valuable resource for cloud integration.
Related links:

by community-syndication | Aug 9, 2016 | BizTalk Community Blogs via Syndication
Last week I was in Las Vegas for SpringOne Platform. This conference had one of the greatest session lists I’ve ever seen, and brought together nearly 2,000 people interested in microservices, Java Spring, DevOps, agile, Cloud Foundry, and cloud-native development…. Read More ›
Blog Post by: Richard Seroter

by vijaymstech | Aug 9, 2016 | BizTalk Community Blogs via Syndication
MessageContextPropertyBase vs MessageDataPropertyBase vs PartContextPropertyBase
By default, none of the value for the property schema base will be selected. But even though you have not selected anything, once you promote a field and assign it to promoted property field in Property Schema, property schema base value will be
“MessageDataPropertyBase” by default when deployed.
If you select the property schema base as MessageContextPropertyBase, then it will be added to the context property of the message but not promoted. To promote the field you need to use custom pipeline component to add that to promoted property field.
To use MessageDataPropertyBase promoted field value, you need to create an instance of the message and use it, where as MessageContextPropertyBase value can be accessed without creating an instance of the message. This behavior is similar to the static variable in any programming language.
So many times, I have wondered how to have a global variable assigned, while doing BizTalk Process. If you think little bit aloud and you can treat this MessageContextPropertyBase as global variable. But you have to make sure, this gets added to the newly created message or you have to get it in local variable. When you need to pass to another orchestration, you can do so by passing it as an Orchestration Parameter.
PartContextPropertyBase:
PartContextPropertyBase is used for setting context properties for individual Message Parts of a Multipart Message. A multipart message can have more than one part.
It is similar to MessageContextPropertyBase and works on Multipart Messages
https://masteringbiztalkserver.wordpress.com/2011/06/06/using-partcontextpropertybase-in-biztalk-server/
http://sachipa.blogspot.in/2012/07/property-schema-property-schema-base.html
Related Links:
https://abdulrafaysbiztalk.wordpress.com/tag/messagecontextpropertybase/
https://masteringbiztalkserver.wordpress.com/2011/03/08/difference-between-messagecontextpropertybase-and-messagedatapropertybase/
https://masteringbiztalkserver.wordpress.com/2011/06/06/using-partcontextpropertybase-in-biztalk-server/
http://biztalkcollections.blogspot.in/2008/02/messagecontextpropertybase-magnified.html
http://iworkonsoftware.blogspot.in/2008/07/property-schema-base.html
http://www.codeproject.com/Articles/117356/Unleashing-the-Power-of-BizTalk-Multipart-Messages
http://blogical.se/blogs/johan/archive/2012/06/03/you-do-not-always-need-a-correlation-set-to-promote-properties-in-a-message-sent-from-an-orchestration.aspx
https://www.gittprogram.com/question/883951_define-correlation-type-of-type-part-context-property-base.html

by vijaymstech | Aug 9, 2016 | BizTalk Community Blogs via Syndication
Content vs Context vs Message Based Routing – Confusion Assured
Content vs Context vs Message Based Routing – Confusion Assured
To quote “Enterprise Integration Pattern Book” –
“The Content-Based Router examines the message content and routes the message onto a different channel based on data contained in the message. The routing can be based on a number of criteria such as existence of fields, specific field values
etc.“.
Most of the time I heard people use these three words as their flavour of the month and its all very confusing. Everyone has there own opinion of this terms and hell bend on trying to understand the different meaning it comes with. Adding spice to this mixture, Microsoft never gave a concrete definition on any of these terms and mostly they will talk about scenarios, where to use and when to use, but what it is, that a million dollar question. This article is not to give proper definition, but to understand its meaning. Only saving grace among those articles was from Leonid Ganeline, which
is provided below, and I kind of agree with him on the term Content and Context Based Routing.
Content-Based Routing:
This routing uses few values from message and route the message based on those values to appropriate destination or further processing.
Example:
If you receive a Loan Application through BizTalk, based on some parameter you want to accept or reject the application. Those values which you are looking for can be either distinguished or you are using XPath expression to get the values and send it to further processing. Remember I have not used the word “Promoted”. If I used Promoted variable, it will be easy to look upon and route to appropriate send port/orchestration for further processing. But once a field got promoted, it is going to attached with word “Context”. That’s where the confusion starts. I think these are the few scenarios which sits on the fence and create confusion.
Context-Based Routing:
In BizTalk term, Context is the term used to point to group of property or meta data that are created by BizTalk Adapter. This Context/Metadata property attach to the message for its whole life cycle. One caveat though, inside orchestration Context property get lost if you applied a map on received message and if you copy the message to another message, message data pay load will be copied but its context will not copied. To do that you need to copy the message context one by one and add to the context of newly created message.
In simple term, context gets lost in Message Assignment and Transform shape. To add context to the newly created message, it has to be added manually in code.
One more concept is the MessageContextPropertyBase ( Next post I will discuss this in detail, to the extend of my knowledge), which is used to get value from the message and added to the context.
Message-Based Routing:
Some weird definition of Message-Based routing from Google Search:
When a message is passed through biztalk without being processed then it is called Message Routing.
When a message is routed by BizTalk based on message Type.
Looking at the above definition 1, without message getting processed means you are not manipulating or applying any map on the message. And how those untouched message gets routed. Obviously through context of the messsage, what else right. Then it should be called as Context Based Routing.
Now comes MessageType, if I route my message based on MessageType, from where I will be getting the Message-Type from? Of course from message Context. Then it should be called as Context-Based Routing.
One more definition I keep on hearing is that if I use PassThrough Pipelines in my receive and send ports without applying Maps then it is called Message Based Routing. PassThrough Pipelines will not add lot more context properties, but still add few context properties related to Receive and Send Ports, and you will be using those to route messages. Still not convinced, that there is a concept called Message-Based Routing.
Quote from “Leonid Ganeline” and Link to the Article:
BizTalk uses the promoted properties for routing. There are two kinds of the properties: the content properties and the context properties. The content property extracts its value from inside the message, it is a value of the element or attribute. [See MSDN] The context property gets its value from the message environment. It can be the port name that receive this message, it can be the message Id, created by the BizTalk. Context properties look like the headers in the SOAP message. Actually they are not the headers but behave like headers.
http://geekswithblogs.net/LeonidGaneline/archive/2011/02/27/biztalk-using-context-for-routing.aspx
Content Based Routing:
https://msdn.microsoft.com/en-us/library/aa548077(v=bts.20).aspx
https://msdn.microsoft.com/en-us/library/ff699643(v=bts.70).aspx
http://www.careerride.com/BizTalk-message-routing-and-content-routing.aspx
https://nethramysooru.wordpress.com/2014/01/10/content-based-and-context-based-routing/
http://mylifeismymessage.net/biztalk-orchestrations-vs-content-based-routing/
Context Based Routing:
http://geekswithblogs.net/LeonidGaneline/archive/2011/02/27/biztalk-using-context-for-routing.aspx
https://social.msdn.microsoft.com/Forums/en-US/5ae04752-78ce-4218-b67d-7900a03e8747/content-and-message-based-routing? forum=biztalkgeneral
Message Based Routing:
https://psrathoud.wordpress.com/2013/11/22/15/
https://www.ordina.nl/nl-nl/overige-content/2012/mei/biztalk-message-based-routing/
by community-syndication | Aug 8, 2016 | BizTalk Community Blogs via Syndication
We’re excited to announce the preview of the BizTalk Server 2016 connector for Logic Apps. This connector was first shown in May at Integrate 2016 in London and we’ve done a bunch of work to improve it since then. The biggest of these is that the connector now enables you to integrate Logic Apps with…
Blog Post by: BizTalk Team

by vijaymstech | Aug 7, 2016 | BizTalk Community Blogs via Syndication
Enterprise Integration Pattern – Design Patterns Notes – Message Construction – Part 1
Enterprise Integration Pattern – Design Patterns Notes – Message Construction
Message Construction:
Command Message:[Command Pattern]
http://www.enterpriseintegrationpatterns.com/patterns/messaging/CommandMessage.html
How can messaging be used to invoke a procedure in another application?
Use a Command Message to reliably invoke a procedure in another application.
There is no specific message type for commands; a Command Message is simply a regular message that happens to contain a
command.
This will be used in SOA Patterns using WCF/Web Service or A2A scenario. You can achieve this by creating a Data Contract/Message Contract in WCF and specifying message details as well as message Operation also. Message operation meaning
how we are going to use the message body and what operation are we going to perform, whether Insert/Update/Delete probably to the Backend Systems. Mostly this kind of design patterns are similar to DML statements of TSQL Database.
Most of this are defined inside SOAP body while you communicate to the Server to do particular operation on the message.
Disadvantages are that it is kind of defined message structure, so any changes has to be done both at server as well as with client also.
Example:
InsertNewCustomer
DeleteOldCustomer
UpdateExistingCustomer
[Refer : SOA Patterns in BizTalk 2009.pdf – Page 114]
Document Message:
http://www.enterpriseintegrationpatterns.com/patterns/messaging/DocumentMessage.html
How can messaging be used to transfer data between applications?
Use a Document Message to reliably transfer a data structure between applications. Whereas a Command Message tells the receiver to invoke certain behavior, a Document Message just passes data and lets the receiver decide what, if anything, to do with the data. The data is a single unit of data, a single object or data structure
which may decompose into smaller units.
This is similar to Command Message, but it will not let the server/application knows, what kind of operation will be done on the message body. It will just transfer the data between applications. It will provide sutle information to the called applications, but how it interpret data is upto them. NewCustomer details in Application A is inserting new Customer to their system. But if it is passed on to another Application B, NewCustomer details may be to send a welcome kit for NewCustomer etc. How the message get interpreted is upto the Business need of the application that is built on.
Example:
PurchaseOrder created by Purchasing department application is to fulfill the order and this information gets passed on to the Account Department application is to start creating Invoice for received Purchase Order and send the bill to the client.
If you think beyond SOA architecture, this can be implemented in normal B2B scenario using different format like EDI/AS2, Rosattanet, SAP-IDOCs.
[Refer : SOA Patterns in BizTalk 2009.pdf – Page 115]
Event Message:
http://www.enterpriseintegrationpatterns.com/patterns/messaging/EventMessage.html
How can messaging be used to transmit events from one application to another?
Use an Event Message for reliable, asynchronous event notification between applications.
When a subject has an event to announce, it will create an event object, wrap it in a message, and send it on a channel. The observer will receive the event message, get the event, and process it. Messaging does not change the event notification, just makes sure that the notification gets to the observer.
Event message based Message Construction design patterns are used to let other applications know that something happens and that will kick start series of other processes.
Example:
In B2B/SOA scenario, Purchase order gets created event will trigger Fullfillment Notification to Order FullFillment Department, inturn it will create Shipment Notification to Logistics department and so on.
[Refer : SOA Patterns in BizTalk 2009.pdf – Page 117]
Request – Reply:
http://www.enterpriseintegrationpatterns.com/patterns/messaging/RequestReply.html
When two applications communicate via Messaging, the communication is one-way. The applications may want a two-way conversation.
https://msdn.microsoft.com/en-us/library/aa559029.aspx
When an application sends a message, how can it get a response from the receiver?
In a request/response messaging pattern, one party sends a request message and the receiving party returns a response message. Two typical examples of request/response processing are the interaction that a browser has with a Web server using the HTTP adapter, and Web service processing using the Simple Object Access Protocol (SOAP) adapter. In BizTalk Server, both the request and the response messages are handled in a typical publish/subscribe fashion. This is an important consideration to understand when you performance-tune a BizTalk application, because a system requiring high throughput might be configured differently than one requiring low latency for individual messages.
When a message is received by a request/response style receive adapter, BizTalk Server first publishes the request message to the MessageBox database. Next this message is received by the appropriate subscriber, which is likely an orchestration bound to a receive port. This subscriber formulates a response message and publishes it to the MessageBox, along with properties that cause it to be sent back to the receive port from which the request came. Finally, the response message is picked up by the publisher of the request, the receive adapter that submitted the request, and is returned to the calling application. The diagram below provides a detailed graphical representation of these steps.
Flow of request/response message received by SOAP adapter:
- The SOAP adapter submits messages to the Endpoint Manager.
- The Endpoint Manager publishes the message into the MessageBox.
- The orchestration, which is bound to the receive port and therefore has a subscription for the message, receives the message and processes it.
- The orchestration sends a response message that is published to the MessageBox.
- The Endpoint Manager receives the response message.
- The Endpoint Manager returns the response to the SOAP adapter
Return Address:
http://www.enterpriseintegrationpatterns.com/patterns/messaging/ReturnAddress.html
The request message should contain a Return Address that indicates where to send the reply message.
The request message should contain a Return Address that indicates where to send the reply message.
Steps to create Return Address Design pattern in BizTalk:
Create a schema with structure of you business details like purchase order details and add return address http URL in it.
Create Orchestration which will be exposed as http WCF Service.
In Orchestration, start another orchestration and pass on the request message and finish the orchestration immediately.
In Child/started orchestration, process your message like inserting PO to the database, but if the PO Quantity cannot be fulfilled , send the PO change/Reject reply to the caller by dynamic send port using Return Address URL. For testing purpose, you can also use File port to send the message, or else you need to create a WCF Service and host it in Console/IIS to listen to your response message. If you are sending it to HTTP Dynamic Send port, you have to wait for the response message in the child orchestration.
Briefly considered Self-Correlating Port is similar to Return Address, but dismissed it. Self-Correlating Port is similar to asynchronous callback in WCF, but it is happening inside Single BizTalk Orchestration process. Both caller and callee are in residing in same process.
Even though it make sense to implement this kind of design patterns in SOA or web based scenario. If we eliminate the web based scenario, we already implementing this pattern in B2B scenarios. On second thought, may be not. Because in B2B scenarios, we will know static client response location and return adddress is not part of the message. This will work only return address should be part of the incoming message.
Thinking further, sending email response message to the consumer about their application status, may be considered as Return Address Design Patterns. Since consumer email is part of incoming message details.
Correlation Identifier:
http://www.enterpriseintegrationpatterns.com/patterns/messaging/CorrelationIdentifier.html
Each reply message should contain a Correlation Identifier, a unique identifier that indicates which request message this reply is for.
https://msdn.microsoft.com/en-us/library/aa578692?f=255&MSPPError=-2147217396 https://blogs.msdn.microsoft.com/richardbpi/2006/05/01/biztalk-correlation-of-untyped-messages/
http://www.cloudcasts.net/ViewWebcast.aspx?webcastid=2521599734904944607
This is implemented in BizTalk using Correlation. Take for example, we will be receiving a Purchase Order from the client and based on the purchase order, we have to send back a Invoice. This can be achieved by the Promoting PO Number, and creating Correlation Set and Type using PO Number and PO message will be send Invoice Orchestration. Invoice Orchestration will create Invoice and send it back to PO orchestration based on the correlated PO Number.
Message Sequence:
http://www.enterpriseintegrationpatterns.com/patterns/messaging/MessageSequence.html
Whenever a large set of data may need to be broken into message-size chunks, send the data as a Message Sequence and mark each message with sequence identification fields.
https://blogs.msdn.microsoft.com/richardbpi/2006/05/08/biztalk-aggregation-pattern-for-large-batches/
Links on How to deal with Large Message Size in Biztalk:
https://msdn.microsoft.com/en-us/library/aa560481.aspx
https://blogs.msdn.microsoft.com/biztalkcpr/2008/11/04/tuning-large-message-threshold-and-fragment-size/
https://msdn.microsoft.com/en-us/library/aa547883.aspx
https://social.msdn.microsoft.com/Forums/en-US/f0eae8b8-b241-4b38-8726-1a4c4fdf51ed/handling-large-messages-in-biztalk-2010? forum=biztalkgeneral
http://social.technet.microsoft.com/wiki/contents/articles/7801.biztalk-server-performance-tuning-optimization.aspx
http://www.codeproject.com/Articles/180216/Transfer-Large-Files-using-BizTalk-Receive-Side
http://www.codeproject.com/Articles/180333/Transfer-Large-Files-using-BizTalk-Send-Side
http://www.codeproject.com/Articles/142171/Transfer-Extremely-Large-Files-Using-Windows-Servi
https://blogs.msdn.microsoft.com/biztalk_core_engine/2005/02/28/large-messages-in-biztalk-2004-whats-the-deal/
Message Expiration:
http://www.enterpriseintegrationpatterns.com/patterns/messaging/MessageExpiration.html
How can a sender indicate when a message should be considered stale and thus shouldn’t be processed?
Messaging practically guarantees that the Message will eventually be delivered to the receiver. What it cannot guarantee is how long the delivery may take. For example, if the network connecting the sender and receiver is down for a week, then it could take a week to deliver a message. Messaging is highly reliable, even when the participants (sender, network, and receiver) are not, but messages can take a very long time to transmit in unreliable circumstances. (For more details, see Guaranteed Delivery.)
Example from Enterprise Intergration Patterns Book:
Often, a message’s contents have a practical limit for how long they’re useful. A caller issuing a stock quote request probably looses interest if it does not receive an answer within a minute or so. That means the request should not take more than a minute to transmit, but also that the answer had better transmit back very quickly. A stock quote reply more than a minute or two old is probably too old and therefore unreliable.
Once the sender sends a message and does not get a reply, it has no way to cancel or recall the message. Likewise, a receiver could check when a message was sent and reject the message if it’s too old, but different senders under different circumstances may have different ideas about how long is too long, so how does the receiver know which messages to reject?
Example/Scenarios:
In BizTalk, you can handle this in 2 different ways I can think off. Both of them use correlation to implement this scenario.
Method 1:
Assuming, when we send message to BizTalk Orchestration, we also include message expiration as an element in the form of notice period. You can use XPath or distinguished field to get this value from xml element. Use correlation to send message to other application/component/Third Party, then we can use this expiration element in the message as waiting period in the listen shape to receive the request back, else close the instance and log an appropriate error message.
Method 2:
If you want to set the expiration date of a business process but not have an option in the xml or flat file message, there are few non-promoted properties available in message context property. FileCreationTime and AdapterReceiveComplete Time are
those 2 properties. To use them, these properties need to be promoted in the custom pipeline component. Both of them are shown using GMT time format and you need to add/subtract the difference in the hosted Biztalk server time zone and need to be
modified. Inside Orchestration use this properties to come up with the time for listen shape to receive the request back, else close the instance and log an appropriate error message.
Format Indicator:
http://www.enterpriseintegrationpatterns.com/patterns/messaging/FormatIndicator.html
How can a message’s data format be designed to allow for possible future changes?
Even when you design a data format that works for all participating applications, future requirements may change. New applications may be added that have new format requirements, new data may need to be added to the messages, or developers may find better ways to structure the same data. Whatever the case, designing a single enterprise data model is difficult enough; designing one that will never need to change in the future is darn near impossible.
When an enterprise’s data format changes, there would be no problem if all of the applications change with it. If every application stopped using the old format and started using the new format, and all did so at exactly the same time, then conversion would be simple. The problem is that some applications will be converted before others, while some less-used applications may never be converted at all. Even if all applications could be converted at the same time, all messages would have to be consumed so that all channels are empty before the conversion could occur.
Realistically, applications are going to have to be able to support the old format and the new format simultaneously. To do this, applications will need to be able to tell which messages follow the old format and which use the new.
https://www.packtpub.com/networking-and-servers/soa-patterns-biztalk-server-2009
Richard Seroter books reference given in this article mostly talks about versioning of the schemas and other artifacts, and it talks in detail about the Major and Minor Versioning changes. Those are all valid point but not able to understand how it will be related to data format.
Say for example I have 2 clients/customers, I need to send PO 850 with different EDI version namely 4010 and 4050. For those I need to execute two different maps, schemas, etc. Those I will term as data format, not the one with simple adding of xml
element in the schema.
If you add couple of extra fields in the message but it still need to be passed to orchestration and to send port, you can still do that by making ValidateDocument = false in the XML Receive Pipeline Property. By default it is false.
Check below article which talk about simple BizTalk Hack in detail.
https://masteringbiztalkserver.wordpress.com/2011/03/02/how-to-validate-incoming-messages-for-xml-structure-and-data-type-using-existing-xmlreceive-pipeline/
https://blogs.msdn.microsoft.com/nabeelp/2008/05/14/biztalk-does-not-validate-my-message/

by vijaymstech | Aug 4, 2016 | BizTalk Community Blogs via Syndication
BizTalk Self Correlating port
Self Correlating is one of the type of Direct Binding in orchestration. This is mainly used for starting child orchestration from parent orchestration and get a response from the child orchestration. This will work similar to call orchestration, but more towards asynchronize ways and we will not be using any correlation to implement this. This works like a loop back adapter. To implement self correlating direct binding, you have to perform few steps.
Parent Orchestration:
In parent orchestration, create a self correlating receive port with message type which you will be receiving from child orchestration. Connect it to a receive shape to receive message.
Before receive shape, place an start orchestration shape and it will pass on few orchestration parameters to the child orchestration.
Child Orchestration:
In child orchestration, have few orchestration parameters as you required. Add a configured port parameter with send communication direction and it will be connected with Send shape in the child orchestration.
This child orchestration configured port parameter will have value of Parent orchestration self correlating port in the Start Orchestration shape.
Once you deployed the orchestration by your preferred method, binding will be little bit tricky. You will not see any Orchestration port binding for this self correlating ports both in Parent as well as child orchestration. It will seems like a invisible/virtual port which does work for you.
This mechanism can be used in Scatter Gather Design Pattern.
Related Articles:
https://msdn.microsoft.com/en-us/library/aa954477.aspx
https://abdulrafaysbiztalk.wordpress.com/tag/self-correlating-ports/
http://geekswithblogs.net/sthomas/archive/2006/02/27/70886.aspx
Code Samples:
http://geekswithblogs.net/nestor/archive/2006/12/21/101772.aspx

by community-syndication | Aug 4, 2016 | BizTalk Community Blogs via Syndication
Error: The Message “Request” has an incorrect type for operation ” port_2.operation_1.Request” Solution: This error occurs if the you messed around Orchestration parameters while using Call/Start Orchestration shape. Verify Parameter in the called orchestration. Also delete the call/start orchestration shape and place new call/start shape and configure it one more time.
Blog Post by: vijaymstech
by Daniel probert | Aug 3, 2016 | BizTalk Community Blogs via Syndication
In case you missed it, Logic Apps moved to General Availability last week.
At the same time, pricing for Logic Apps gained a new option: Consumption charging i.e. pay by use.
I‘ve been talking to a number of clients about this new pricing model, and every single one has expressed concerns: it‘s these concerns that I wanted to touch upon in this post. Most of these concerns are based around the fact that these customers feel they can no longer accurately calculate the monthly cost for their Logic Apps in advance.
I also feel that the whole discussion might be a bit overblown, as once you remove the cost of having to pay for servers and server licenses for a traditional on-premises application (not to mention the run and maintain costs), Logic Apps can be significantly cheaper, regardless of which pricing model you use.
Old Pricing Model vs New
Prior to GA, Logic Apps were charged as part of the App Service Plan (ASP) to which they belong: An App Service Plan has a monthly charge (based on the number of compute units used in the plan), but also throttles a Logic App once a certain number of executions are exceeded in a month (the limit changes depending on the type of ASP the Logic App uses).
Effectively the old way was Pay Monthly, the new way is Pay As You Go.
This table outlines the changes:
|
|
App Service Plan Model
|
Consumption Model
|
|
Static Monthly Charge
|
TRUE
|
FALSE
|
|
Throttling
|
TRUE
|
FALSE
|
|
Limit on Number of Logic App Executions
|
TRUE
|
FALSE
|
|
Pay per Logic App Execution
|
FALSE
|
TRUE
|
I can understand why Microsoft are making the change: consumption pricing favours those that have either a small number of Logic App executions per month (as they only pay for what they use); or who have large numbers of executions per month (and were therefore being throttled as they exceeded the ASP limits).
I‘m not sure yet if the ASP-style pricing model will stay: there‘s no mention of it any more in the Logic Apps pricing page, but you can still (optionally) associate a Logic App with an ASP when you create it.
How to select either pricing model when creating or updating a Logic App
When you create a new Logic App, you used to be able to select an App Service Plan: now this option is no longer available, and all new Logic Apps use the Consumption pricing plan by default.
However, if you have an existing Logic App and you wish to switch the billing model, you can do so via PowerShell here. You can also follow the instructions at the bottom of this blog post here (I suspect this will get surfaced in the Portal if both billing models are kept).
Why the new model can be confusing
Consumption pricing makes sense: one of the benefits of Azure is that you pay for what you use. Instead of paying upfront for an expensive license fee (e.g. SQL Server and BizTalk Server licenses) you can instead pay a smaller amount every month. A lot of businesses prefer this as it helps with cash flow, and reduces capital expenditure.
The main issue with consumption pricing for Logic Apps is that instead of paying for each execution of the Logic App, you‘re paying for the execution of the actions within that Logic App. And this is the problem, as a Logic App is opaque: when you‘re designing a solution, you may know how many Logic Apps you‘ll have, but you may not know exactly how many actions each will contain (or how many pf those actions will be executed) and this makes it difficult to estimate the runtime cost.
Up to now, it‘s been easy to work out what a Logic App will cost to run. And that‘s usually one of the first questions from a client: how much will this cost me per month.
But now, it‘s harder: instead of knowing exactly you have to estimate, and this estimate has to be based not only on how many times a Logic App will execute, but also *what* the Logic App will be doing i.e. if it will be looping, or if actions in an IF branch will execute.
Effect of the consumption model on development and testing
The main concern I (and others) have with the Consumption billing model is the effect it will have on development and testing: developers (and testers) are used to executing their applications with little or no cost (other than maybe the cost of an dev/test server and dev/test licenses).
Take a BizTalk Developer: chances are the BizTalk and SQL Server Licenses they are using came from an MSDN subscription, or they bought the Dev edition. In either case, they will execute their code during the development process without paying any attention to cost.
The same applies to testers.
An argument can be made that the cost per action of a Logic App is so low that this wouldn‘t be an issue (e.g. a reasonably complex Logic App with 50 actions per execution would cost 2.5p (4c) per execution. But the pennies do add up: imagine a corporate customer with 100 developers: each time those developers execute a Logic App like this, it costs the company £2.50 (US $4.00) – and that‘s just executing it once.
Microsoft will likely point out that an MSDN Subscription comes with free Azure credit, and that therefore there is no extra cost to execute these Logic Apps as they‘re covered in this free credit. But this doesn‘t apply to most of my clients: although the developers have MSDN, the free credit applies only to their MSDN subscription not the corporate subscription where they perform dev and testing. The MSDN subscriptions are usually used for prototyping, as they‘re not shared amongst multiple developers, unlike the corporate subscriptions.
So to summarise:
Consumption pricing could lead to:
- A preference against Test Driven Development due to perceived cost of executing code frequently against tests
- Corporates hesitant to allow developers to execute code during development whenever they want due to perceived cost
- A hesitation on performing Load/Perf Testing on Logic Apps due to the cost of doing so e.g. with our sample 50 action Logic App, executing it a million times for load testing would cost £4500 (about US $6000) – consumption pricing gets cheaper once you get over a certain number of actions (so a million actions is £0.00009 per action) – this is retail pricing though, some large customers will benefit from a volume licensing discount e.g. for an Enterprise Agreement.
Note: There is questionable value in performing Load/Perf Testing on Logic Apps, as there is little you can do to tune the environment, which is the usual rationale behind Load Testing (especially in a BizTalk environment). However, some level of testing may be required if your Logic App is designed to process multiple messages and there is either a time limit or the messages are connected in some way (e.g. debatching a request and then collating responses).
The solution
The solution (in my view) is to keep both billing models:
- ASP pricing can be kept for development/testing, which will have the effect of putting a cap on the cost of development and testing (although will hamper Load Testing). ASP pricing also benefits customers who have a reasonable number of executions per month, but aren‘t hitting the throttling limits. ASP pricing also allows for customer to try out Logic Apps for free by using the Free pricing tier.
- Consumption pricing can then be used for Production workloads, or for those who find that consumption pricing is cheaper for them for dev/test than ASP pricing
In addition, it would help if Microsoft provided more examples on monthly cost; provided some way to help calculate the monthly cost under the consumption model; and highlighted the overall reduction in cost through using Logic Apps for most customers. For example, if your Logic App is under the ASP pricing model, and you execute it, then the portal could tell you what that execution would have cost you under the consumption model (using retail pricing). Just an idea!
Let me know if you have other opinions, or agree/disagree with this.
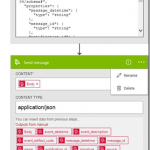
by mbrimble | Aug 2, 2016 | BizTalk Community Blogs via Syndication
August 2, 2016
My First Logic App
I really like this logic app pattern.
The NZ Post parcel events application (https://www.nzpost.co.nz/business/developer-centre/tracking-notification-api/watch-method) will not repeat an event. I decided to expose http endpoint in an azure Logic App and send these to a Azure Service Bus. I then I retrieve the message using a BizTalk SB-Messaging adapter, whenever I am ready and then do all the heavy lifting.
This was a brilliant experience with a customer in front of me. All done in less than 15 minutes!
No comments yet.
RSS feed for comments on this post. TrackBack URI