by community-syndication | Sep 30, 2008 | BizTalk Community Blogs via Syndication
By popular demand I have made some significant changes to the EDI logger. None I don’t think are more important than the rest, but some do address a REAL thorn in a lot of peoples sides. I will get to that in the next entry about the change to the message. This one deals with the pipeline itself. Below is a picture of the receive pipeline configuration:
The send pipeline configuration:
And the following table on how to configure the values:
| Row |
Type |
Meaning |
| Database |
string |
BAM Database to store data |
| Server |
string |
BAM Server to store data |
| Active |
boolean |
Activates the logging mechanism, if not, it is simply a pass thru pipeline component |
| Count1 |
string |
Either XPath or Regex.Match (string count) |
| Count2 |
string |
Either XPath or Regex.Match (string count) |
| Count3 |
string |
Either XPath or Regex.Match (string count) |
| FromAddress |
string |
email address representing BizTalk as source |
| FromName |
string |
Friendly Name representing FromAddress (ex: BizTalk Prod [email protected]) |
| Notify |
boolean |
Activate flag for email notification |
| NotifyOnlyOnError |
boolean |
Only send out email if there are validation errors |
| SMTPHost |
string |
SMTP Host address |
| Secure |
boolean |
True: Do not include ISA01/02/03/04 as components to be used
False: Include ISA01/02/03/04 as components to be used |
| SubjectLine |
string |
Macros and regular text to create customized email subject line |
| ToAddress |
string |
Allows multiple email addresses to be included in email notification (semicolon separates email addresses) |
by community-syndication | Sep 29, 2008 | BizTalk Community Blogs via Syndication
Reveals extensive enhancements for simplified application life-cycle management, provides sneak peek at all key focus areas for Visual Studio 2010 and the .NET Framework 4.0. Find the press release here: http://www.microsoft.com/presspass/press/2008/sep08 Read More……(read more)
by community-syndication | Sep 29, 2008 | BizTalk Community Blogs via Syndication
Hi all
Today i read an email from a guy who had a problem with optional elements in an input
giving problems in a positional flat file output. The issue being, of course, that
if an element in the input of a map is optional, it might be missing. If the element
is missing, it will not be created in the destination of a map, and therefore, the
flat file assembler will complain because it needs the element to create the correct
positional structure.
I seem to have it working, and will here walk through my solution to explain it.
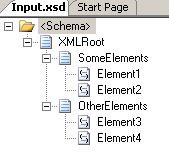
First of all, I have a Schema for the XML input:

All elements are 1..1 except Element2, which has minOccurs=0.
Secondly, I have a schema for the flat file output:
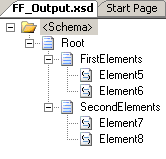
All elements are mandatory. The record delimiter is 0x0d 0x0a and the two subrecords
to the root are positional records.
The map is pretty straight forward:
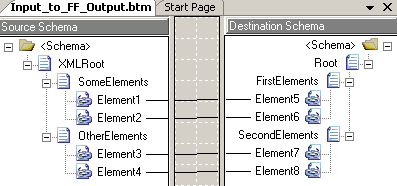
Just plain connections between the elements.
For testing purposes, I have two test instances, that validate against the input schema.
They are exactly the same, except one doesn’t have the “Element2”-element in it.
If I try to test the map with the input that has the “Element2”-element, and
turn on validation of both input and output, and let the output be “Native”, then
it will work. If, however, I test the map inside Visual Studio .NET with the example
that does not have the Element2 element, it will fail. It will report that:
Output validation error: The element ‘FirstElements’ has incomplete content. List
of possible elements expected: ‘Element6’.
So basically, the map does not create the Element6 element in the destination schema,
and since the Element6 element is required, it fails validation.
BUT, here comes the surprise; It works if it is deployed. So basically, there must
be some inconstency between how the map tester in VS.NET works and how the stuff works
when running.
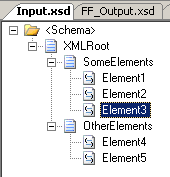
I tried changing the schemas to include an element inside the first record as the
last element, such that the input has a “SomeElements” record with three elements
inside it, of which only the second is optional. Likewise I added a new element in
the output schema and updated the map. You can see all three here:
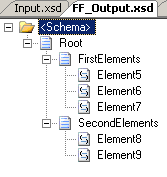
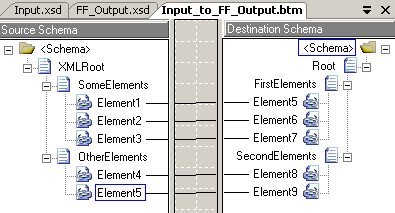
Still, I only get errors when testing inside Visual Studio .NET and not when things
are deployed and running… Which actually bugs me a bit, but that is a whole other
story.
So, to sum up, I only have three explanations as to why it works for me and not for
the fellow with the issue:
-
He is using a BizTalk version that is not BizTalk 2006 R2
-
He hasn’t tried deploying it, and is relying on the map tester
-
He has some bogus values for the two properties I will mention below
At the end of this post, let me just quickly mention to properties that are available
for flat file schemas:
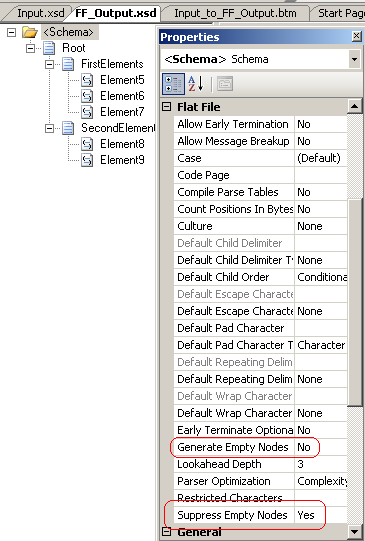
The “Generate Empty Nodes” and “Suppress Empty Nodes” properties might be helpful.
They are defined here: http://msdn.microsoft.com/en-us/library/aa559329.aspx
Hope this helps someone.
You can find my project here: FlatFileEmptyElements.zip
(27.55 KB)
—
eliasen
by community-syndication | Sep 29, 2008 | BizTalk Community Blogs via Syndication
I first saw this article in SDTimeson VSTS 2010, and then found some official word on the subject in Brian Harry’s post titled Shining the Light on Rosario which is a fairly detailed note (and an earlier note titled “Charting a course for Rosario”which provides even more infomation)
To quote a section from the article in […]
by community-syndication | Sep 29, 2008 | BizTalk Community Blogs via Syndication
Q: Can I run BizTalk Server 2006 R2 on Windows Server 2008? A: No. I've been asked this enough times in the last couple of weeks to take the few minutes it takes to write this post and link to the three main resources I give customers who wants to…(read more)
by community-syndication | Sep 29, 2008 | BizTalk Community Blogs via Syndication
This is the second part in the series of new things that are afoot with the MSDN websites. In this posting, I would like to discuss some changes in the posting of articles and code samples. As an example of the new experience, I’d like to draw attention to a refreshed article that was recently updated and reposted from Morgan Skinner, ’Creating a Custom WF Activity.’
In the prior years, we made extensive use of the MSDN Online Library. Information on the MSDN Online Library takes one of two forms. There is the documentation that is written by the product group, which is typically posted under the WF 3.5 documentation node and WCF 3.5 documentation node of the taxonomy tree. There is also the whitepapers that were created outside of the product group – be that folks from the field, Microsoft Consultants, or external MVPs; these typically were posted in the ’Articles and Overviews’ nodes (one for WCF Articles and Overviews, and one for WF Articles and Overviews) of the taxonomy tree.
Whitepaper Articles
Posting the whitepapers into the MSDN Online Library provided a series of benefits – including the inclusion in the installable documentation and consistency of the MTPS (MSDN & TechNet Publishing System); it also had drawbacks, primarily around flexibility, formatting, and discoverability. A major complaint that has come up about the way we’ve been doing things is that it makes it very hard to find new content that has been published into the systemwhich is a fair argument – the system has been well designed as a online version of an installed documentation library; it just wasn’t designed for the casual reader to regularly drop in and look for updates.
With the new MSDN Social Content servers, we now additional flexibility. Articles get the benefit of HTML (and are limited more by the CSS and ASP.NET template structure, rather than being limited to a handful of standard HTML tags).
Because of this, we’re trying to make articles posted to the new system a bit more interactive and easier to explore and relate to one another. To the right is a screenshot of Morgan’s article. I’ve called out a few of the new features, that I’m hoping help the reader get a better experience. There will likely be a few changes to the layout over the next couple weeks as we publish a few more articles up to the server and get a feel for what works (and what doesn’t), and based on community feedback (if you have feedback – as always – either post a comment below or use the contact link to the right to send us an e-mail).
In addition to the tagging capabilities (covered in my prior post on the new MSDN Dev Center pages), you’ll notice that we have created a grey ’About this Article’ box. I know grey isn’t all that inspiring, but we did it to be consistent with the MSDN Online Library ’This relates to version’ box, and it’s flexible – let me know if you feel strongly about it. Within this box, we try to provide a list of the related technologies, a link to related downloads and related articles, and a mini table of contents to let users jump to the section of the article they may be most interested in. Additionally, we’ve moved the ’About the Author’ up from the bottom to the right column.
Code Samples
For code samples, there really wasn’t a convenient place to put them. As a result, many of the code samples were posted up to the Microsoft.com Downloads website. Because of this limitation, the NetFX team had created the NetFX3.com website to host code samples. With the new MSDN platform, we now have two repositories for code samples and sample applications:
- CodePlex: CodePlex is Microsoft’s server for hosting open source projects. Projects hosted in the CodePlex environment can be both Microsoft sponsored, as well as community led/owned – and include a TFS backend, an integrated issue tracking database, and discussion boards for hosted projects. A few of the notable Microsoft-sponsored projects on CodePlex that stand out for me include AAA, BBB, and CCC.
- MSDN Code Gallery: The MSDN Code Gallery can be thought of as a place to post sample code and articles that involve Microsoft technologies. I believe that it is powered by the same engine as CodePlex, but isn’t intended for team-based development collaboration (Code Gallery doesn’t have the TFS backend for source control and issue tracking).
In the case of Morgan’s article, the source code has been posted up to the MSDN Code Gallery (screen shot of the Code Gallery page to the left). Posting the article via this method has many advantages over the prior method. Primary above them is the inclusion of the author in the project. In this project’s case, Morgan is co-owner of the Code Sample project, and can update the code sample as needed. As well, the author (and the MSDN Dev Center team – us) have the ability to update the project’s wiki page to point to relevant MSDN Forum posts and additional nuggets of wisdom that the community contribute to the project over its lifetime.
We’re hoping that this provides better context to those who come to the project years after it has been posted, allowing them to learn from those who came before them and hopefully not get frustrated with any issues in future service packs or DLL updates (should they occur; although we all know that code samples are perfect and never have quirks ^_^ ).
Over the coming months and years, expect to see WF and WCF projects showing up in these two repositories. We will make announcements on here and on the MSDN Dev Centers, and – as always – are interested in your opinions on what works and what doesn’t.
I hope you enjoy the new additions to the MSDN Dev Center family; happy reading – and happy coding!
by community-syndication | Sep 29, 2008 | BizTalk Community Blogs via Syndication
I have a situation in which I need to cache lookup data from a database tables that will be used in the BizTalk Mapper. The part that makes it interesting is that it is not just key value pairs that I need to cache. I need to return a value for a 4 part key. The key needs to be the context (domain), the effective start and end date and the source key.
The .NET framework does not contain an object that will allow you to have a key containing more than one part.
So, how do we make this happen? The first thing that we need to do is to create a class that represents the values that will be the key. The second is to implement the IEqualityComparer<T> interface.
So, lets create the class that we will use as the key in the dictionary.
public class LookupCacheKey
{
private string _sourceContext;
private string _sourceKey;
private DateTime _effectiveDate;
private DateTime _effectiveStartDate;
private DateTime _effectiveEndDate;
public LookupCacheKey()
{
}
public LookupCacheKey (string sourceContext, string sourceKey, DateTime effectiveDate)
{
this._sourceContext = sourceContext;
this._sourceKey = sourceKey;
this._effectiveDate = effectiveDate;
}
}
In addition to this code, I also have a method (directly after the LookupCacheKey method) that sets the values in this class. The setValues method takes all of the values that we received from the database query to create the collection. The database contains values for the lookup data’s valid use dates through a start and end date field. The value that comes from our application will have a date that we need to ensure falls between the start and end date or we can’t use the value (look at the Equals method below). In our implementation, if we have a date and doesn’t have a valid return value then we throw an exception. So, the code for our setValues method looks like:
public setValues string sourceContext, string sourceKey, DateTime effectiveStartDate, DateTime effectiveEndDate)
{
this._sourceContext = sourceContext;
this._sourceKey = sourceKey;
this._effectiveStartDate = effectiveStartDate;
this._effectiveEndDate = effectiveEndDate;
}
Now what I have is a class that can be instantiated but I still need to add the IEqualityComparer interface.
The IEqualityComparer has two methods that you need to implement. They are the Equals and GetHashCode methods.
The Equals method provides the functionality necessary to compare the two object instances (comparing the values within the instance). The method returns true if the classes are equal.
The GetHashCode method provides a hash code for object. This is used within the dictionary to divide the dictionary items in the buckets – subgroups to provide the speed that we expect from the dictionary object. For more information on creating good hash keys and more information on the performance and implementation options check out this on MSDN.
To implement the IEqualityComparer interface for our LookupCacheKey class we will add an additional class called EqualityComparer. This implementation the EqualityComparer class will placed inside the LookupCacheKey class so that we have access to the private variables in the LookupCacheKey class from within the EqualityComparer class. This class will implement the Equals method to compare each of the 4 variables to let the dictionary object know if there is a match.
public class LookupCacheKey
{
private string _sourceContext;
private string _sourceKey;
private DateTime _effectiveStartDate;
private DateTime _effectiveEndDate;
public LookupCacheKey()
{
}
public LookupCacheKey (……)
{
……..
}
public class EqualityComparer: IEqualityComparer<LookupCacheKey>
{
public bool Equals(LookupCacheKey lc1, LookupCacheKey lc2)
{
return lc1._sourceContext == lc2._sourceContext &&
lc1._sourceKey == lc2._sourceKey &&
lc1._effectiveDate >= lc2._effectiveStartDate &&
lc1._effectiveDate <= lc2._effectiveEndDate;
}
public int GetHashCode(LookupCacheKey lc)
{
return 0;
}
}
}
We now have a complete custom key class for the dictionary. The dictionary does not care what the key contains, only that it can compare the key values. Lets create a dictionary object that uses the class we just created.
public class BizTalkCacheHelper
{
private static Dictionary<LookupCacheKey, string> LookUpCacheDictionary =
new Dictionary<LookupCacheKey, string>(new LookupCacheKey.EqualityComparer());
…..
}
One thing that will be evident very quickly is that if you don’t create an instance of the EqualityComparer then the dictionary will use its default method of comparing objects – which will not match even when the keys are the same.
Now we have two more steps to use the Dictionary. We need to populate the Dictionary and then we need to call the the class to get our value.
To populate the Dictionary object we used the SQL Dependency functionality. The BizTalkCacheHelper class also included a function to populate the Dictionary through a DataReader (along with the setValues method). After the initial data load, the function then sets up the SQL Dependency subscription. Take a look at the Query Notifications page on MSDN for samples and requirements. So, once we loaded the Dictionary we then needed to create the SQLDependency object and set the OnChange event so that we could listen to the event which would tell us when a change occurred in the database. In the OnChange event handler, we then repopulated the Dictionary object. One thing to note about the SQL Dependency functionality is that you create a subscription based on a Select query and you get one notification per change. What that means is that you need to setup your subscription again after each notification (which you can see at the bottom of the PopulateDictionary method).
The code within the BizTalkCacheHelper function looks like:
private void PopulateDictionary()
{
SqlConnection conn = null;
SqlCommand comm = null;
SqlCommand commDependency = null;
conn = new SqlConnection(connString);
conn.Open();
comm = new SqlCommand();
……
SqlDataReader dataReader = comm.ExecuteReader();
while (dataReader.Read())
{
LookupCacheKey key = new LookupCacheKey();
key.setValues(……);
string value = dataReader[“TargetValue”].ToString();
LookUpCacheDictionary.Add(key, value);
}
dataReader.Close();
//Now we set up the SQL Dependency Functionality
commDependency = new SqlCommand();
commDependency.Connection = conn;
commDependency.CommandText = “…………”;
commDependency.Notification = null;
SqlDependency dependency = new SqlDependency(commDependency);
dependency.OnChange += new OnChangeEventHandler(dependency_OnChange);
commDependency.ExecuteNonQuery();
}
and the OnChange event handler receives the event and calls the PopulateDictionary method to reload the cache as well as to setup the next subscriptions. It looks like this.
private void dependency_OnChange(object sender, SqlNotificationEventArgs e)
{
if (e.Info != SqlNotificationInfo.Invalid)
{
PopulateDictionary();
}
}
Now we have a cache component that is populated with data and is setup to receive and handle notification whenever data in the database changes. Lastly, we just need to call into the component and get back our value for the key parameters we pass it. To do this we will add a method like the following:
public string GetValue(string sourceContextName, string domainName, string sourceKey, string effectiveDate)
{
string lookupValue = string.Empty;
try
{
LookupCacheKey lookupKey = new LookupCacheKey(sourceContextName, domainName, sourceKey, DateTime.Parse(effectiveDate));
if (LookUpCacheDictionary.ContainsKey(lookupKey))
{
string lookupValue = LookUpCacheDictionary[lookupKey].TargetValue.ToString();
}
}
………
if(lookupValue == string.Empty)
{
//throw exception
}
return lookupValue;
}
Now we can call directly from the Mapper (or any front end) into the GetValue function and we will finally have the value that is needed from the cached component.
by community-syndication | Sep 29, 2008 | BizTalk Community Blogs via Syndication
I’ve been looking into the possibility of updating the highly successful Professional BizTalk Server 2006 book to take into account new features and capabilities in BizTalk Server 2006 R2 and the recently announced BizTalk Server 2009 product.
A fair bit has changed to warrant new chapters and updating of various chapters but of course the main body of content is still accurate and will be brought forward into any new edition.
The current book is of course still absolutely usable for both BizTalk Server 2006, R2 and even 2009 as the main engine, features and best practices are unchanged.
I’ve listed some of my thoughts around what needs to be covered to expand the reach of the book given the new version but would love to hear of topics and sections that you would like to see added if you’ve already read the current edition.
Please send me a mail with your thoughts via my blog site or add comments to this posting, I’d really appreciate your views on what we should consider.
I haven’t got formal commitment from Wiley yet as I’m still at the Table of Contents stage, here are my outline thoughts as it currently stands.
Technology Primer – Update
%u00b7 Cover WCF basics
%u00b7 Cover the penalty of XmlDocument vs Serializable Classes vs XPath with real-examples of overhead
BizTalk Architecture – Update
%u00b7 Emphasise further how important testing is, don’t expect performance and how critical the performance of supporting systems is. Detail techniques for isolating and testing performance of supporting systems
%u00b7 Cover any changes with BTS2009
%u00b7 Potentially position BTS2009 vs Oslo at the architectural level
Adapters – Update
%u00b7 Include drill-down on WCF Adapter topics
%u00b7 Overview
%u00b7 Different WCF-* adapters
%u00b7 Walkthrough
%u00b7 Demonstrate how a custom binding can be developed using the WCF Adapter SDK (null adapter?)
%u00b7 Cover the new WCF Adapter bindings (SQL, MQS, etc)
Business Activity Monitoring – Update
%u00b7 Provide implementation of BAM Latency Timer pipeline component
%u00b7 Provide more real-world and common questions/issues guidance
Business Rules Engine – Update
%u00b7 Position BRE vs the WF rules engine and futures
RFID – New Chapter
%u00b7 Drill-down chapter into the RFID features of BizTalk complete with real-world examples
Testing – Update
%u00b7 Provide more real-world “case studies” of how it’s been done right and the benefits..
%u00b7 New BizUnit features (Excel)
%u00b7 Update with any new VS2008 (and maybe future release features)
Performance and Scalability – Update
%u00b7 PAL for analysis of performance logs
%u00b7 Discuss SAN technology improvements
%u00b7 ’n’ step plan for identifying where bottlenecks lie within a BizTalk rig
%u00b7 Expand throttling “plain” English guide, step-by-step diagnosis guide
Low Latency – Update
%u00b7 Cover new options such as NetTcp and NetNamedPipe WCF bindings
%u00b7 Include real-world perf-test results, step by step guide
Administration – Update
%u00b7 Virtualization (HyperV)
%u00b7 Best Practice Analyser
%u00b7 MSBuild
%u00b7 SQL2008 differences
BizTalk Best Practices – Update
%u00b7 Add further best practices, small and large – with evidence as to why
Cloud Services (BizTalk Services, SSDS, etc.) – New Chapter
%u00b7 Overview
%u00b7 Connectivity
%u00b7 Identity
%u00b7 Cloud Workflow
%u00b7 SSDS
%u00b7 Cloud Commerce scenario code and walkthrough
First look at Oslo futures – New Chapter
%u00b7 More soon 😉

by community-syndication | Sep 28, 2008 | BizTalk Community Blogs via Syndication
jQuery is a lightweight open source JavaScript library (only 15kb in size) that in a relatively short span of time has become one of the most popular libraries on the web.
A big part of the appeal of jQuery is that it allows you to elegantly (and efficiently) find and manipulate HTML elements with minimum lines of code. jQuery supports this via a nice "selector" API that allows developers to query for HTML elements, and then apply "commands" to them. One of the characteristics of jQuery commands is that they can be "chained" together – so that the result of one command can feed into another. jQuery also includes a built-in set of animation APIs that can be used as commands. The combination allows you to do some really cool things with only a few keystrokes.
For example, the below JavaScript uses jQuery to find all <div> elements within a page that have a CSS class of "product", and then animate them to slowly disappear:

As another example, the JavaScript below uses jQuery to find a specific <table> on the page with an id of "datagrid1", then retrieves every other <tr> row within the datagrid, and sets those <tr> elements to have a CSS class of "even" – which could be used to alternate the background color of each row:

[Note: both of these samples were adapted from code snippets in the excellent jQuery in Action book]
Providing the ability to perform selection and animation operations like above is something that a lot of developers have asked us to add to ASP.NET AJAX, and this support was something we listed as a proposed feature in the ASP.NET AJAX Roadmap we published a few months ago. As the team started to investigate building it, though, they quickly realized that the jQuery support for these scenarios is already excellent, and that there is a huge ecosystem and community built up around it already. The jQuery library also works well on the same page with ASP.NET AJAX and the ASP.NET AJAX Control Toolkit.
Rather than duplicate functionality, we thought, wouldn’t it be great to just use jQuery as-is, and add it as a standard, supported, library in VS/ASP.NET, and then focus our energy building new features that took advantage of it? We sent mail the jQuery team to gauge their interest in this, and quickly heard back that they thought that it sounded like an interesting idea too.
Supporting jQuery
I’m excited today to announce that Microsoft will be shipping jQuery with Visual Studio going forward. We will distribute the jQuery JavaScript library as-is, and will not be forking or changing the source from the main jQuery branch. The files will continue to use and ship under the existing jQuery MIT license.
We will also distribute intellisense-annotated versions that provide great Visual Studio intellisense and help-integration at design-time. For example:

and with a chained command:

The jQuery intellisense annotation support will be available as a free web-download in a few weeks (and will work great with VS 2008 SP1 and the free Visual Web Developer 2008 Express SP1). The new ASP.NET MVC download will also distribute it, and add the jQuery library by default to all new projects.
We will also extend Microsoft product support to jQuery beginning later this year, which will enable developers and enterprises to call and open jQuery support cases 24×7 with Microsoft PSS.
Going forward we’ll use jQuery as one of the libraries used to implement higher-level controls in the ASP.NET AJAX Control Toolkit, as well as to implement new Ajax server-side helper methods for ASP.NET MVC. New features we add to ASP.NET AJAX (like the new client template support) will be designed to integrate nicely with jQuery as well.
We also plan to contribute tests, bug fixes, and patches back to the jQuery open source project. These will all go through the standard jQuery patch review process.
Summary
We are really excited to be able to partner with the jQuery team on this. jQuery is a fantastic library, and something we think can really benefit ASP.NET and ASP.NET AJAX developers. We are looking forward to having it work great with Visual Studio and ASP.NET, and to help bring it to an even larger set of developers.
For more details on today’s announcement, please check out John Resig’s post on the jQuery team blog. Scott Hanselman is also about to post a nice tutorial that shows off integrating jQuery with ASP.NET AJAX (including the new client templating engine) as well as ADO.NET Data Services (which shipped in .NET 3.5 SP1 and was previously code-named "Astoria").
Hope this helps,
Scott
by community-syndication | Sep 28, 2008 | BizTalk Community Blogs via Syndication
To me there are three distinct type of developers. There are the day-job developers, the lazy developers, the average developer, the programatic developers, and the passionate developers. These are the main types by my definitions. The day-job developers…(read more)