by community-syndication | Mar 31, 2007 | BizTalk Community Blogs via Syndication
Howdy everyone,
So first off, I should probably say that my posts might be a bit more far and few between (not that they are all that often as it stands :). A long time co-worker, Kartik, will probably be manning the ship on the blog as I have decided to expand my skills a bit and work on SQL Server Analysis Services. Figured I had been helping people build the processes which actually executed their business logic, now I wanted a bit more experience with the tools they use to analyze what exactly they have been doing at their business. This blog, though, will remain a BizTalk blog since it was never meant to be “my” blog … just look at the name. Okay, enough of that. 🙂
As a “parting gift”, I managed to convince the team to let me add a small enhancement to persistence as long as I did not push changes to the UI. Ostensibly, this was really meant for PSS, but personally, I would rather have everyone else fix / figure out their problems without having to call PSS. So don’t tell them I told you, but here you go 🙂
As part of default dehydration now, the orchestration engine also persists, in the clear, the name of the shape on which it was blocked. I have seen many customers which turn on shape level tracking for orchestration just so that if things get “hung up” and lots of orchestrations end up in the dehydrated state, they can open the orchestration in the debugger view and see what it has executed and what it is waiting on. Using orchestration debugger for this is just a tremendous overkill and adds overhead to the processing and now you have to manage the potential buildup of this information in the tracking db. All just so you can know what an orchestration is blocked on. With R2, you have the potential to figure this out yourself. 🙂
Unfortunately, we did not get this into the UI. Would have been really cool to view it in the MMC and dehydrated orchestrations would have the string of the blocking shape. But we gave you a start and now if we ever did add the UI tools, we wouldn’t have to change to underlying db schema or any of the engine. So here are the details.
In the Instances table in the messagebox there is a new column called nvcLastAction. This column contains a guid for dehydrated instances. Sorry, all I had access to in the engine was a guid. However, in the DTA database you will find a table called dta_ServiceSymbols which contains some xml for each service which is deployed, regardless of whether you have any tracking on. This xml is used to translate the guids into string names for some of our tools. It is relatively easy to look at this and build a little tool which will map the guid to the actual shape name. Sorry I have not written the tool … Remember about being very careful when looking directly in the messagebox. Be careful of locking tables and causing all sorts of blocking issues. Use NOLOCK hints and never, ever, ever update / delete anything. If you are at all unsure about rules around this, please see http://blogs.msdn.com/biztalk_core_engine/archive/2004/09/20/231974.aspx which is specific to 2004 and mostly obsolete for 2006 with the new enhancements to the MMC which makes these direct queries unnecessary, but the rules for quering are still valid. Be very, very, very careful. If you change things or cause problems by introducing blocking, your chances of support are pretty much nill.
Couple of caveats. We did not do extensive testing on this for parallels where you might be blocking on more than one shape. It could technically pick either shape with no gaurantees. Also, we are simply depending on the orchestration engine to provide this information as we hook in to grab it in the same fashion as the tracking interceptors do.
So there you go. Have some fun with it. Perhaps if you ask nicely, you could convince someone to put this in for 2006 SP1. You have to ask nicely, though. 🙂
Hope everyone is having a great day.
Lee

by community-syndication | Mar 31, 2007 | BizTalk Community Blogs via Syndication
Hey everyone, I’ve finally managed to upload the v2006_R2 release. Its actually a rather small release and i know i’ve got to sort out my version numbering really soon. I promise to do that in the next release. I’ve been struggling with a VPC from hell that just crawls all the time and doesnt let me write any code at all and combined with the general lumbering behemoth that is VSTS, i’m just about stuffed Since i dont have anything installed on my base laptop(and the workstation in the office wont allow me to connect to CodePlex) i’m forced to work with the VM and i’ve spent long nights just disabling services and trying to get it to perform, but it wont. Ok, thats enough of my rant for the day.
This
new release has the first cut of entlib logging added in and a new
“MapExecutingStep” to test maps. The AltovaXmlValidateStep has also been
enhanced and it now allows the user to specify whether the file is expected to
fail or pass the validation (to cater to scenarios where we need to test invalid
files). I’ve also added in some strongnamed EntLib2.0 dlls and a snk file into the References folder. You can of course choose to use your own entlib dlls. There is no separate test as such for entlib logging and the same test base is run and the system logs to a logfile specified in the config file for the tests.exe. I’m thinking of making the core libraries as exe’s because we can add references to exe’s now and this way i can supply a set of entlib config files with the library if people are interested.
Check it out and let me know if you encounter any problems. If you open
the solution and the system complains about not being able to locate TFS just
let it remove all the bindings. When you run the tests the perfmon test still fails but thats because there are some hardcoded paths in the tests that i inherited and i still havent had time to fix them. But the step works so ignore the failing test.
The next version will incorporate the latest from Kevin Smiths core code base and i will make all the modifications needed to the BizUnit() and Context() classes, or i may just add another BizUnitEx() class and a ContextEx() class so i can continue making my changes without breaking any of his code. I’ll also try and make all the properties public. From reading the description on his releases page and blog, it appears that Kevin is planning to do more stuff with BizUnit and im still waiting to hear from him about the possibility of collaborating. If i dont hear soon, then i guess it will be time to make a hard decision about whether to continue with the “extensions” tag for this project or just move to a completely separate code-base. Do stop by on the forums and let me know what you think about this.
Anyway, i hope you find the latest code base useful.


by community-syndication | Mar 31, 2007 | BizTalk Community Blogs via Syndication
Hey everyone, I’ve finally managed to upload the v2006_R2 release. Its actually a rather small release and i know i’ve got to sort out my version numbering really soon. I promise to do that in the next release. I’ve been struggling with a VPC from hell that just crawls all the time and doesnt let me write any code at all and combined with the general lumbering behemoth that is VSTS, i’m just about stuffed Since i dont have anything installed on my base laptop(and the workstation in the office wont allow me to connect to CodePlex) i’m forced to work with the VM and i’ve spent long nights just disabling services and trying to get it to perform, but it wont. Ok, thats enough of my rant for the day.
This
new release has the first cut of entlib logging added in and a new
“MapExecutingStep” to test maps. The AltovaXmlValidateStep has also been
enhanced and it now allows the user to specify whether the file is expected to
fail or pass the validation (to cater to scenarios where we need to test invalid
files). I’ve also added in some strongnamed EntLib2.0 dlls and a snk file into the References folder. You can of course choose to use your own entlib dlls. There is no separate test as such for entlib logging and the same test base is run and the system logs to a logfile specified in the config file for the tests.exe. I’m thinking of making the core libraries as exe’s because we can add references to exe’s now and this way i can supply a set of entlib config files with the library if people are interested.
Check it out and let me know if you encounter any problems. If you open
the solution and the system complains about not being able to locate TFS just
let it remove all the bindings. When you run the tests the perfmon test still fails but thats because there are some hardcoded paths in the tests that i inherited and i still havent had time to fix them. But the step works so ignore the failing test.
The next version will incorporate the latest from Kevin Smiths core code base and i will make all the modifications needed to the BizUnit() and Context() classes, or i may just add another BizUnitEx() class and a ContextEx() class so i can continue making my changes without breaking any of his code. I’ll also try and make all the properties public. From reading the description on his releases page and blog, it appears that Kevin is planning to do more stuff with BizUnit and im still waiting to hear from him about the possibility of collaborating. If i dont hear soon, then i guess it will be time to make a hard decision about whether to continue with the “extensions” tag for this project or just move to a completely separate code-base. Do stop by on the forums and let me know what you think about this.
Anyway, i hope you find the latest code base useful.

by community-syndication | Mar 30, 2007 | BizTalk Community Blogs via Syndication
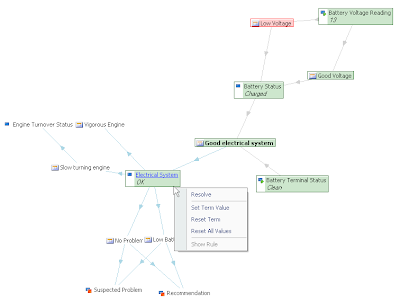
The Rule Manager will soon be enhanced with a new feature that allows the Interactive Rule Map as a Rule Debugger. See a video here: Rule Validation Video. It’s almost an action movie.
This is part one of providing Rule Validation (testing your rules) with the Rule Manager.
Color legend for Rule:
- Green: Rule fired
- Red: Rule failed
- Orange: Rule is pending
Color legend for Term:
- Green: Term is assigned
- Orange: Term is unknown
How it works? We use the backward chaining algorithm to resolve a goal. The user can select any business term as a goal.
- When the user clicks resolve, the inference engine will try to resolve this goal by executing the rules.
- When a term is encountered that can not be derived from other rules, an ask dialog will be shown to the user. The user value will be stored into an internal table, so consecutive runs will first use this table before asking the user. Internally the rule manager supports defining restrictions on business terms. This allows the inference engine to show input options when asking a value for a term.
About the user data value table:
- The table can be cleared by clicking on ‘Reset All Values’ from the context menu.
- You can change the value of one particular term by selecting the ‘Reset Term’ on the Term context menu.
- Note: also business terms that are inferred by the inference engine can be overwritten by the user. Be careful with this because this would skip the backward-chaining of this rule branch.
Just leave a comment what you think about this one.
Marco
by community-syndication | Mar 29, 2007 | BizTalk Community Blogs via Syndication
Everybody these days seems to be pretty excited about the new PDF version of BizTalk 2006 documentation (Btw, a latest .CHM version is out as well, but there is no hoopla around that).
So thought I’ll download the PDF version and check it out as I have been using only the .CHM version extensively. But I was not very impressed with what I saw.
To start with, the PDF version is really huge file 114 MB (whereas the .CHM version is only 44MB), there is no way my PDA mobile device will load that kind of thing even with external memory card.
The links in the PDF version are not active (not clickable), so you cannot navigate through the document
Searching through the pdf document is very slow and the interface not as user friendly as the .CHM version.
The CHM version on the other hand (IMHO) is more convenient, and the search is blazing fast, you can do incremental search as well using the index tab.
You can even maintain a list of favorite pages just like keeping shortcuts, and the best part is, when I overwrote the old .CHM file with the latest version, all the old favorite pages (shortcuts) appeared intact.
I am not sure why we have a PDF version in the first place, I am sure missing out on something, someone kindly enlighten me please.
Thanks & Regards
Benny Mathew
Seamless Integration Solutions
BizTalk Consulting, Development, Training
Bangalore, India
Website: http://www.seamless.in
Blog: http://GeeksWithBlogs.net/benny
BizTalk Usergroup: http://groups.google.co.in/group/b-bug
by community-syndication | Mar 29, 2007 | BizTalk Community Blogs via Syndication
Hi,
I’m reliably informed by Wiley that the book should be in-stock at their warehouse on the 23rd April 2007 and should then ship to distributors/stores in the US followed by international outlets subject to delivery times. Enjoy!
Woo Hoo!
by community-syndication | Mar 29, 2007 | BizTalk Community Blogs via Syndication
Every organization (and developer) has their own development project structure. I’ve set up a BizTalk project structure that my company will use for all new BizTalk projects. To make life easy, I also built a simple VBScript file to automatically build the structure for us.
My folder structure looks like this:
I’ve got a spot […]
by community-syndication | Mar 29, 2007 | BizTalk Community Blogs via Syndication
Hi,
I’m reliably informed by Wiley that the book should be in-stock at their warehouse on the 23rd April 2007 and should then ship to distributors/stores in the US followed by international outlets subject to delivery times. Enjoy!
Woo Hoo!
by community-syndication | Mar 29, 2007 | BizTalk Community Blogs via Syndication
Some of us when new to building custom pipeline components would have faced this problem, especially with long messages.
You have a custom pipeline component placed downstream after the disassembler component and expect that the disassembler component would have promoted / written the required schema fields into the context, so that your component can reach out to the context and access them, but you find that it fetches a null even when the message has a value.
This is because the pipeline works in a streaming fashion, which means, all components in the pipeline gets started as the message flows through them. For example, before the disassembler has finished its work, your custom component kicks-in and tries to access the context. Now if the value that you are looking for is somewhere at the end of a lengthy message, it would not yet have got read by the disassembler to be able to promote it into the context, but your custom component already tried fetching it and failed.
One easy solution to this is to read the entire stream from your custom component before accessing the context, this will make sure that all previous components have finished its job and have promoted / written the value into the context. However this is not a good approach as you will end up reading the whole message into memory and may cause an Out-Of-Memory error. You will also anyway need to convert it back to a stream and reset the stream pointers before you can pass it on further since the whole BizTalk architecture is stream based.
Another option (the correct way, but a bit more complex) is to wrap the stream in your own stream and hook to its events to notify when it had finished the reading fully, so that you can go ahead and access the context.
If you are building a custom pipeline component, maybe its worth checking out an undocumented class called XpathMutatorStream, defined within the Microsoft.BizTalk.Streaming namespace (available only in the GAC, Microsoft.BizTalk.Streaming.dll)
Check out the following article by Martijn Hoogendoorn for more on this:
http://martijnh.blogspot.com/2006/03/xpathmutatorstream.html
Thanks & Regards
Benny Mathew
Seamless Integration Solutions
BizTalk Consulting, Development, Training
Bangalore, India
Website: http://www.seamless.in
Blog: http://GeeksWithBlogs.net/benny
BizTalk Usergroup: http://groups.google.co.in/group/b-bug
by community-syndication | Mar 28, 2007 | BizTalk Community Blogs via Syndication
Eric (MS) has been working hard in providing us (loving your work Eric!) with updated
BizTalk documentation.
The folks are doing a great job over all of this. This is a massive PDF – a single
one which encompasses a great deal of things within it.
Here’s the email I got earlier.
——
Hello,
We have provided a new, updated Monster
PDF of the BizTalk Server 2006 documentation set. It is also available off
of a link on the BizTalk Server 2006 Developer Center at http://msdn.microsoft.com/biztalk.
Highlights include:
%u00b7 The
PDF is in a self-extracting zip file that is approximately 57megs.
%u00b7 The
PDF tips the scales at 117 megabytes and includes almost 20,000 pages.
%u00b7 Links
are rendered in blue with underlines but do not work. This may be addressed
in a future enhancement.
%u00b7 Searching
may be slow due to the size of the document.
%u00b7 Feedback,
banners, and other content items have been removed to improve the PDF experience.
If you have any comments including ideas for PDF subset collections or for other content,
please send them along.
Thanks,
Eric
