by michaelstephensonuk | Oct 1, 2017 | BizTalk Community Blogs via Syndication
Recently I had a chat with a few people at a company about integration solutions and a question came up which I remember not having been asked in a while. “Will the business users be able to modify the solution after its live”. Back in the day you used to get asked this quite often but I don’t remember being asked this one for a while. I do know that the technology landscape has changed a lot since I last got asked this and after a very interesting discussion I thought id share my thinking of this space.
Why would the user want to modify the solution
There are a few different things that come up as the reason for this desire. It’s a good idea in this discussion with a customer to find out their drivers, they may not always be the same. Some of the common ones include:
- IT guys are expensive so we don’t want to constantly need to pay a premium for changes
- IT take too long to make the changes
- A change may seem very simple yet IT seem to turn it into a project
- We need to react to customer’s needs and changes quickly
What are the ways in which the user may modify the solution
Different solutions will have different things that can be changed or tuned but if we think of common solutions we see these are some of the areas we can change things:
- Config settings in the solution which are used to drive decision logic. EG a threshold for an order which is considered large. Depending upon where the config settings are stored they may be able to be modified by the business user
- Business Rules may be editable by a business user
- Flow logic, the solution may have a workflow which could be edited by the user
- On boarding new customers/partners is a part of the integration solution the business user may wish to take control of
- Data mapping and transformation rules
Im sure there are probably plenty of other areas but above are just a few off the top of my head
Should the user be allowed to modify the solution
Assuming the reason that the business users want to be able to take control of modifying the solution or parts of it is valid then a decision over if this should be allowed or not is likely to come down to the desire of the product owner or sponsor and the governance areas of the solution.
What we need to consider is that if we elevate the business users permissions to control parts of the integration solution, does this mean we trade off any other parts of the solution. In this area we need to consider the areas of the solution that the business user will often have low regard for such as performance, testing, application lifecycle management, security and risk. If for example we go and grant permissions for the business user to modify the work flow of an integration process then the changes are they will reactively go an do this in response to a change required by their customer. They may not think to communicate the planned change, they may not test it properly and may think their change has worked by they don’t understand that they have now broken 3 things down stream which have been affected by this change.
The one think you can guarantee is that the business user will very rarely have an understanding of dependencies and consequences within the system. I say this quite boldly because often many IT people do not have this understanding either. When it comes to making changes, even if you have a very good IT architecture, treating the change like pulling out a piece of a Jenga puzzle is a good approach to make. First you need to work out if this is a good piece to be messing around with or not. Maybe its pretty safe and you can let your business user get on with it and at other times you need to be very cautious and through.
Having a view on the changes the business would like to make overlayed with some kind of heat map of your architecture will tell you the safe Jenga pieces for the business to take control of and the areas of risk when you need to keep in IT.
When you then let the business make these changes themselves, you still need to implement a change management process for them to follow. You don’t want to be in a position where the business user made a change which wasn’t reflected back into the system source configuration so that next time there is a major release the change is regressed. Teams still need to work together.
Types of solution
Once you have identified areas and rules around the business user making changes in isolation, I guess you have laid out your rules for engagement as you begin democratizing integration in certain areas.
I would expect that you find solutions would fall into certain types which are more and less acceptable for the business to change.
Citizen Integrator
Citizen Integrator solutions are those ones which were either built by the business or built by IT but can be handed over to be looked after day to day by business users. These may be solutions for individuals or solutions for teams.
In this space you will find super users in the business such as Excel guru’s begin to thrive. They can build solutions for their team and themselves and really innovate.
One of the challenges from an IT perspective is that if the Citizen Integrator builds a solution that becomes too important or if it becomes relevant to be managed by regulatory rules which the business function may not be aware of but IT have dedicated functions to support.
How do you as an IT function stop bob the HR junior intern from building the mission critical staff holiday system replacement project without anyone in IT being aware?
Id expect the business user to be able to make the following changes in this type of solution:
Lightweight Low Risk Integration
Lightweight integration projects may be good candidates for business users to “modify”. I would consider light weight to mean not lots of load, not very complex and fairly well isolated. In this scenario you may choose to allow a business super user to some changes in certain areas but it is likely some areas may require a more advanced skillset.
Id expect the business user to be able to make the following changes in this type of solution:
Mission Critical & High Risk
In a mission critical integration solution I would expect that there would be a pretty thourgh change management process that would control changes to the system. In these cases the consequences of breaking something out-weigh the benefits of quick changes. I would expect that most changes would involve a degree of impact analysis followed by a controlled change process involving making the change, deploying it in a repeatable way, testing the change and making the change live.
The intention of the process overhead is to remove risk of things going wrong and sometimes removing the risk of politics in the organisation if something was broken that affected the core business.
I would expect in this case the attitude to the business super user making changes would be:
Those examples above are just some of the ones you might come across. It really depends on the organisation and its attitude to risk and change. An example you might find is a mission critical system which has certain parts of the system which are very safe for business users to modify. An example might be an architecture where Dynamics CRM is used to provide a lot of the settings and configuration for a customer and then integration processes use these settings as required. This gives the user a place where they can safely modify some parts of the system which are used by others. I think the key point here though is it comes back to a heat map of your architecture so you know the safe Jenga pieces and the unsafe ones.
Technology Comparison
Up until this point I have tried to think about things agnostic of technology, but if we also bring in this angle it gets even more interesting. Back a number of years ago when we had a small set of tools available there were only a few limited choices in this space, but now we have many more choices.
Flow & Power Apps
If we know we have requirements for the business user to take an active part in the solution and its maintenance then Flow and Power Apps give us an ecosystem which is built for these users. In a solution we can incorporate these tools to provide a safe(ish) area for the business user to do their bits. We can even give the business user control of the entire solution if its appropriate.
Flow and Power Apps should be a part of our integration architecture anyway and give us a big tick in the box of empowering the business user to be an active stakeholder in an integration solution.
Logic Apps
Logic Apps are a really interesting one, they have the features or a high power mission critical integration tool but the ability to sandbox logic apps in resource groups means it is possible for us to use some logic apps for those IT only use cases and have other Logic Apps where the business user could be granted access to Azure and the resource group to be able to manage and modify if it was appropriate.
BizTalk
BizTalk is one of the tools where there are not that many choices for the business user. It is unlikely we would want the business user to make changes to anything which is not then handed over to IT for deployment. That said in an agile environment a BizTalk developer and business subject matter expert working closely on a solution can be a very good way to work.
Rules, Cross Reference Data, port settings and Configuration settings are the most likely candidates for a desire to change but I think the risks of doing this without an ALM process would outweigh any benefits.
One point to note with BizTalk is that BizTalk 360 provides a number of features which can allow a business user to manage their integration solution. While BizTalk might be one of the less friendly tools to allow a business super user to make changes, BizTalk 360 can allow the person to manage their messages and process instances if they want. This can be done in a safe way.
SSIS & Data Factory
Azure Data Factory and SSIS are like BizTalk in that it would be difficult to get a business user to be able to do anything with them. They are a fairly closed environment and require a significant skill set to do anything with them. Id see these as IT only tools.
Service Bus
Service Bus is an interesting one, you could imagine a scenario where the business user might request that all new customer messages are now also sent to a new application they are buying. Conceptually its not too much of a leap to see an advanced user setting up a new subscription from the new customer topic to the new application worker queue. In the real world however I can imagine that most of these changes would require some additional work around the applications either sending or receiving messages so I think the service bus change would be unlikely to be done in isolation.
I think a business user may also struggle to understand message flows without an upfront visualization tool.
With this in mind I suspect Service Bus would be unlikely to be a good fit for requirements for business users to modify.
Event Grid
My first thought is that event grid would fall into the same space as service bus messaging, but maybe in the future as the solution matures the fact that the data is events rather than messages may mean that there are certain scenarios that the business may dynamically change their interest in. In wonder about scenarios like a university clearing time where perhaps a super user gets a really cool idea of a way to improve the likelihood of a new student signing up and would like to explore events for just 2 or 3 conditions for a couple of days. Self service subscription to events in this nature could be a really powerful way of experimentation within the business.
Summary
I think the answer to the initial question has changed a lot over the last few years, its great to be in the position where we have loads of technical options and rather than being limited in how we could include those requirements into a solution its now a case of making sure we don’t go too over the top and remember that there is still an important place for governance and best practices in addition to agility and flexibility.
Exciting times really
by michaelstephensonuk | Aug 31, 2017 | BizTalk Community Blogs via Syndication
A quick you tube video to show how easy it is to send messages to to table storage from BizTalk
[embedded content]

by michaelstephensonuk | Jul 31, 2017 | BizTalk Community Blogs via Syndication
One of the biggest challenges in integration projects over the years is how to manage the relationship between the implementation of your solution and the documentation describing the intention of the solution and how it works and how to look after it.
We have been through paradigm shifts where projects were writing extensive documentation before a single line of code was written through to the more agile approaches with leaner documentation done in a just in time fashion. Regardless of these approaches the couple of common themes that still exist is:
- How do we relate the documentation to the implementation?
- How do we keep the documentation up to date?
- How do we make it transparent and accessible?
Ever since the guys at Mexia in Brisbane introduced me to Confluence, I have been a huge supporter of using this for integration. I have found the shift from people working over email and in word documents to truly collaborating in real time in Confluence to be one of the biggest factors for success in projects I have worked on. The challenge still remained how to create the relationship between the documentation and the implementation.
Fortunately with Azure we have the ability to put custom tags on most resources. This gives us a very easy way to start adding links to documentation to resources in Azure.
In the below article Ill show how we use this with a Logic Apps solution.
The Resource Group + Solution Level Documentation
In this particular case most of our solution is encapsulated within the resource group. This works great as we can have a document describing the solution. Below shows the confluence page we have outlining the solution blueprint and how it works.
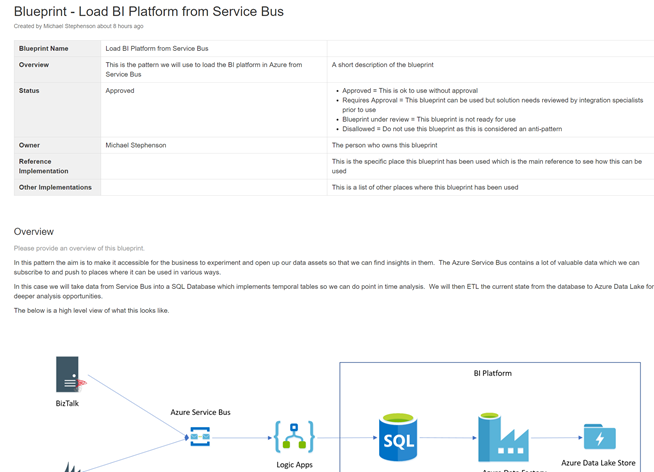
This solution documentation can then be added to the tags of the resource group as shown in the picture below.
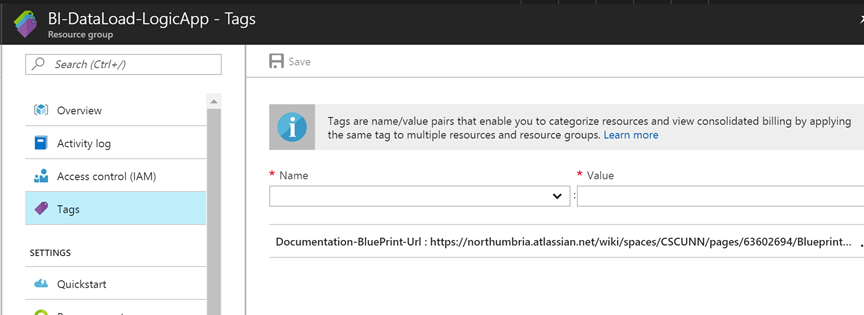
The Logic App + Interface Specific Documentation
Next up we have the interface specification from our interface catalogue. Below is an example page from confluence to show a small sample of what one of these pages may look like. The specification will typically include things like analysis, mappings and data formats, component diagrams, process diagrams, etc.
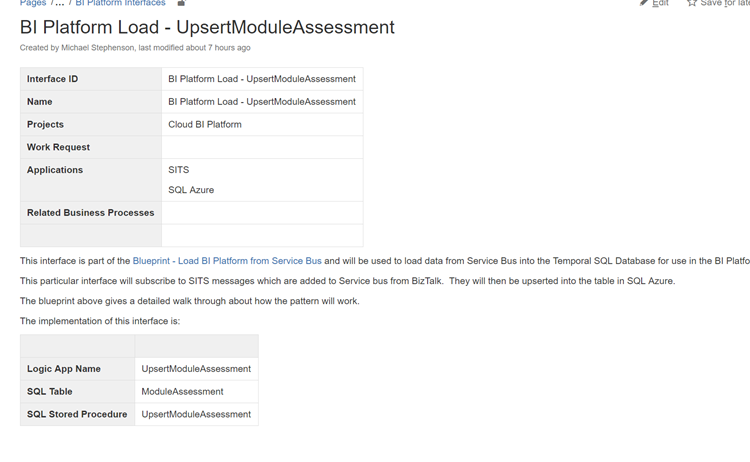
In the logic app we are able to use the tags against the logic app to create a relationship between our documentation and the implementation. In the below example I have added a link to the solution blueprint the locig app implements and also some specific documentation for that interface.
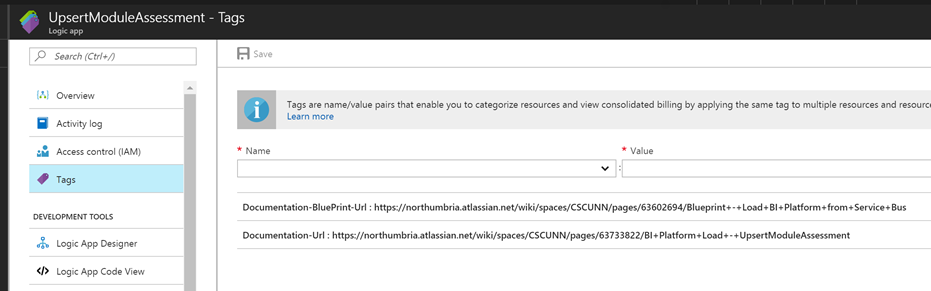
API Connector and Application specific connection documentation
Next up we have application connector and API documentation. In the resource group we have a set of API connectors we have created. In this case we have the SQL one for connecting to our SQL Azure database as shown below.
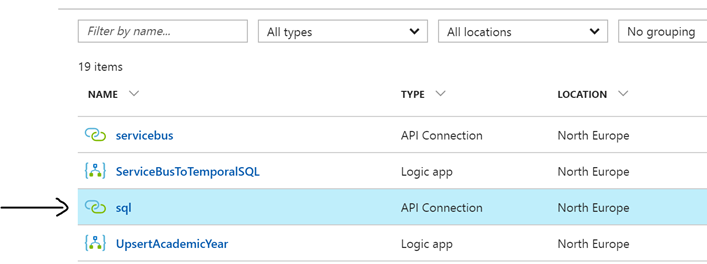
In its tags we can now add a link to a page in confluence where we will document specifics related to this connection.
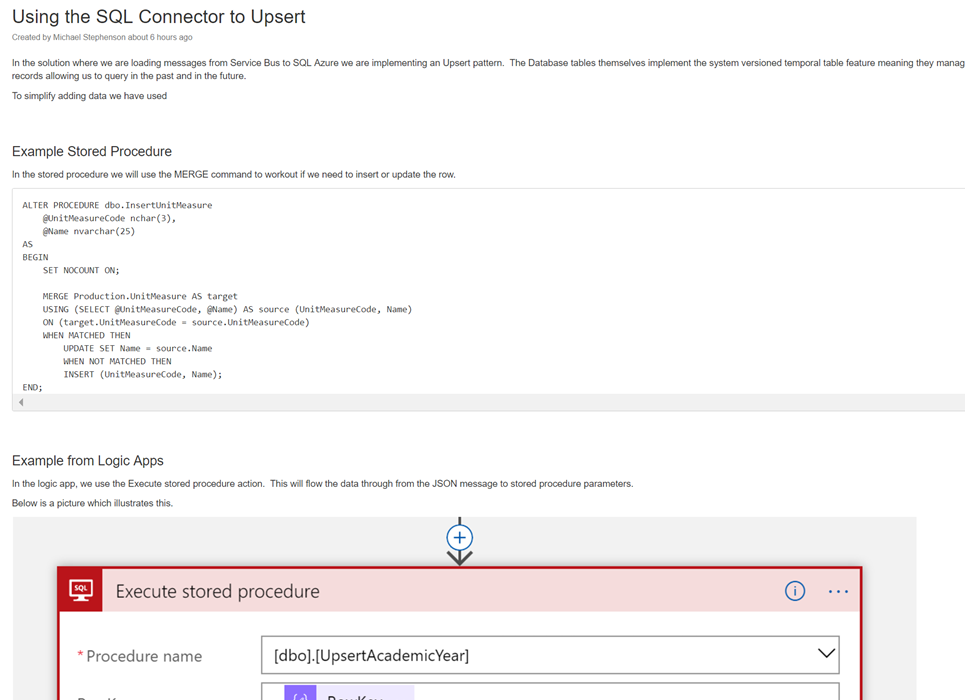
In this particular case one of the interesting things is how we will be using the MERGE command in SQL to upsert a record to the database, we have documented how this works in Confluence and we can easily link to it from the SQL connector. Below is an example of this documentation.
Summary
In summary you can see that tags enables us to close the gap between implementation and documentation/guidance. This is a feature we should be able to use a lot!

by michaelstephensonuk | Jul 22, 2017 | BizTalk Community Blogs via Syndication
I wanted to talk a little about the architecture I designed recently for a Dynamics CRM + Portal + Integration project. In the initial stages of the project a number of options were considered for a Portal (or group of portals) which would support staff, students and other users which would integrate with Dynamics CRM and other applications in the application estate. One of the challenges I could see coming up in the architecture was the level of coupling between the Portal and Dynamics CRM. Ive seen this a few times where an architecture has been designed where the portal is directly querying CRM and has the CRM SDK embedded in it which is an obviously highly coupled integration between the two. What I think is a far bigger challenge however is the fact that CRM Online is a SaaS application and you have very little control over the tuning and performance of CRM.
Lets imagine you have 1000 CRM user licenses for staff and back office users. CRM is going to be your core system of record for customers but you want to build systems of engagement to drive a positive customer experience and creating a Portal which can communicate with CRM is a very likely scenario. When you have bought your 1000 licenses from Microsoft you are going to be given the infrastructure to support the load from 1000 users. The problem however is your CRM portal being tightly coupled to CRM may introduce another amount of users on top of the 1000 back office users. Well whats going to happen when you have 50,000 students or a thousands/millions of customers starting to use your portal. You now have a problem that CRM may become a bottle neck to performance but because its SaaS you have almost no options to scale up or out your system.
With this kind of architecture you have the choices to roll your own portal using .net and either Web API or CRM SDK integration directly to CRM. There are also options to use products like ADXStudio which can help you build a portal too. The main reason these options are very attractive is because they are probably the quickest to build and minimize the number of moving parts. From a productivity perspective they are very good.
An illustration of this architecture could look something like the below:
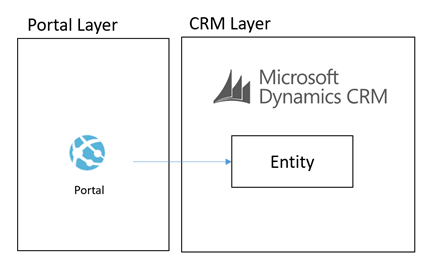
What we were proposing to do instead was to leverage some of the powerful features of Azure to allow us to build an architecture for a Portal which was integrated with CRM Online and other stuff which would scale to a much higher user base without having performance problems on CRM. Noting that problems in CRM could create a negative experience for Portal Users but also could significantly effect the performance of staff in the back office is CRM was running slow.
To achieve this we decided that using asynchronous approaches with CRM and hosting an intermediate data layer in Azure would allow us at a relatively low cost have a much faster and more scalable data layer to base the core architecture on. We would call this our cloud data layer and it would sit behind an API for consumers but be fed with data from CRM and other applications which were both on premise and in the cloud. From here the API was to expose this data to the various portals we may build.
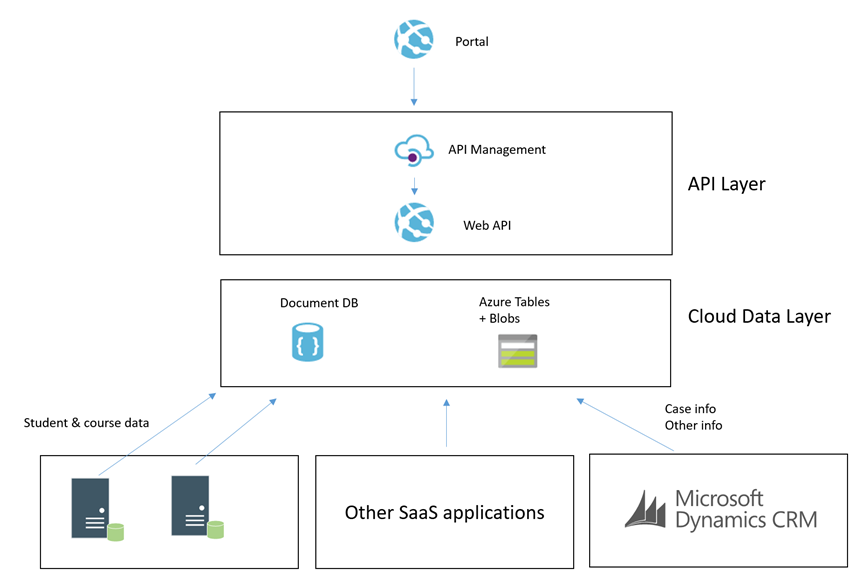
The core idea was that the more we could minimize the use of RPC calls to any of our SaaS or On Premise applications the better we would be able to scale the portal we would build. Also at the same time the more resilient they would be to any of the applications going down.
Hopefully at this point you have an understanding of the aim and can visualise the high level architecture. I will next talk through some of the patterns in the implementation.
Simple Command from Portal
In this patter we have the scenario where the portal needs to send a simple command for something to happen. The below diagram will show how this works.
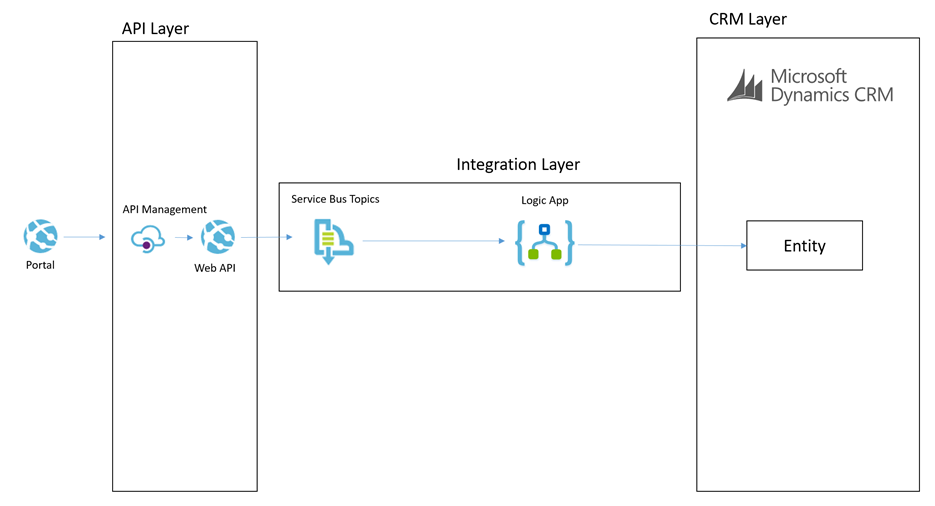
Lets imagine a scenario of a user in the portal adding a chat comment to a case.
The process for the simple command is:
- The portal will send a message to the API which will do some basic processing but then it will off load the message to a service bus topic
- The topic allows us to route the message to many places if we want to
- The main subscriber is a Logic App and it will use the CRM connectors to be able to interact with the appropriate entities to create the chat command as an annotation in CRM
This particular approach is pretty simple and the interaction with CRM is not overly complicated. This is a good candidate to use the Logic App to process this message.
Complex Command from Portal
In some cases the portal would publish a command which would require a more complex processing path. Lets imagine a scenario where the customer or student raised a case from the portal. In this scenario the processing could be:
- Portal calls the API to submit a case
- API drops a message onto a service bus topic
- BizTalk picks up the message and enriches with additional data from some on premise systems
- BizTalk then updates some on premise applications with some data
- BizTalk then creates the case in CRM
The below picture might illustrate this scenario
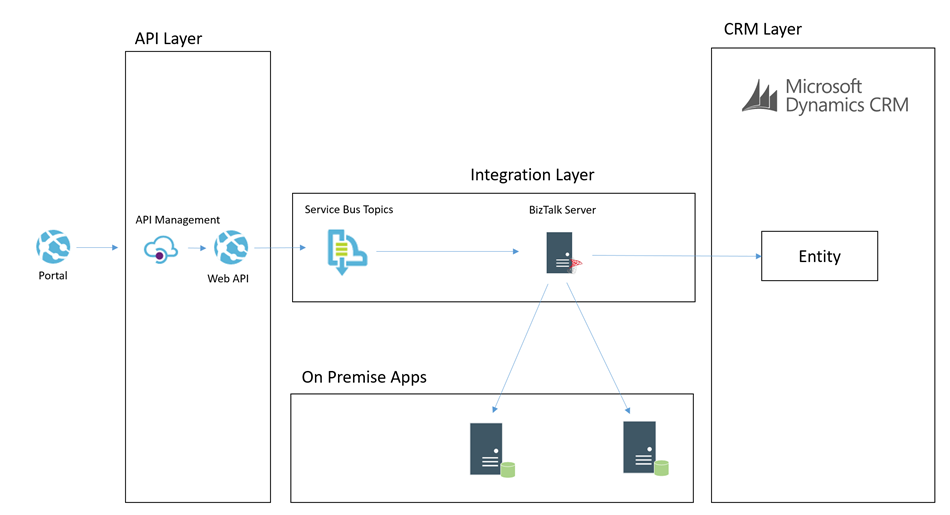
In this case we choose to use BizTalk rather than Logic Apps to process the message. I think as a general rule the more complex the processing requirements, the more I would tend to lean towards BizTalk than Logic Apps. BizTalks support for more complex orchestration, compensation approaches and advanced mapping just lends itself a little better in this case.
I think the great thing in the Microsoft stack is that you can choose from the following technologies to implement the above two patterns behind the scenes:
- Web Jobs
- Functions
- Logic Apps
- BizTalk
Each have their pro’s and con’s which make them suit different scenarios better but also it allows you to work in a skillset your most comfortable with.
Cloud Data Layer
Earlier in the article I mentioned that we have the cloud data layer as one of our architectural components. I guess in some ways this follows the CQRS pattern to some degree but we are not specifically implementing CQRS for the entire system. Data in the Cloud Data Layer is owned by some other application and we are simply choosing to copy some of it to the cloud so it is in a place which will allow us to build better applications. Exposing this data via an API means that we can leverage a data platform based on Cosmos DB (Document DB) and Azure Table Storage and Azure Blob Storage.
If you look at Cosmos DB and Azure Storage, they are all very easy to use and to get up and running with but the other big benefits is they offer high performance if used right. By comparison we have little control over the performance of CRM online, but with Cosmos DB and Azure Storage we have lots of options over the way we index and store data to make it suit a high performing application without all of the baggage CRM would bring with it.
The main difference over how we use these data stored to make a combines data layer is:
- Cosmos DB is used for a small amount of meta data related to entities to aid complex searching
- Azure Table store is used to store related info for fast retrieval by good partitioning
- Azure Blob Storage is used for storing larger json objects
Some examples of how we may use this would be:
- In an azure table a students courses, modules, etc may be partitioned by the student id so it is fast to retrieve the information related to one student
- In Cosmos DB we may store info to make advanced searching efficient and easy. For example find all of the students who are on course 123
- In blob storage we may store objects like the details of a KB article which might be a big dataset. We may use Cosmos DB to search for KB articles by keywords and tags but then pull the detail from Blob Storage
CRM Event to Cloud Data Layer
Now that we understand that queries of data will not come directly from CRM but instead via an API which exposes an intermediate data layer hosted on Azure. The question is how is this data layer populated from CRM. We will use a couple of patterns to achieve this. The first of which is event based.
Imagine that in CRM each time an entity is updated/etc we can use the CRM plugin for Service Bus to publish that event externally. We can then subscribe to the queue and with the data from CRM we can look up additional entities if required and then we can transform and push this data some where. In our architecture we may choose to use a Logic App to collect the message. Lets imagine a case was updated. The Logic App may then use info from the case to look up related entity data such as a contact and other similar entities. It will build up a canonical message related to the event and then it can store it in the cloud data layer.
Lets imagine a specific example. We have a knowledge base article in CRM. It is updated by a user and the event fires. The Logic App will get the event and lookup the KB article. The Logic App will then update Cosmos DB to update the metadata of the article for searching by apps. The Logic App will then transform the various related entities to a canonical json format and save them to Blob storage. When the application searches for KB articles via the API it will be under the hood retrieving data from Cosmos DB. When it has chosen a KB article to display then it will retrieve the KB article details from blob storage.
The below picture shows how this pattern will work.
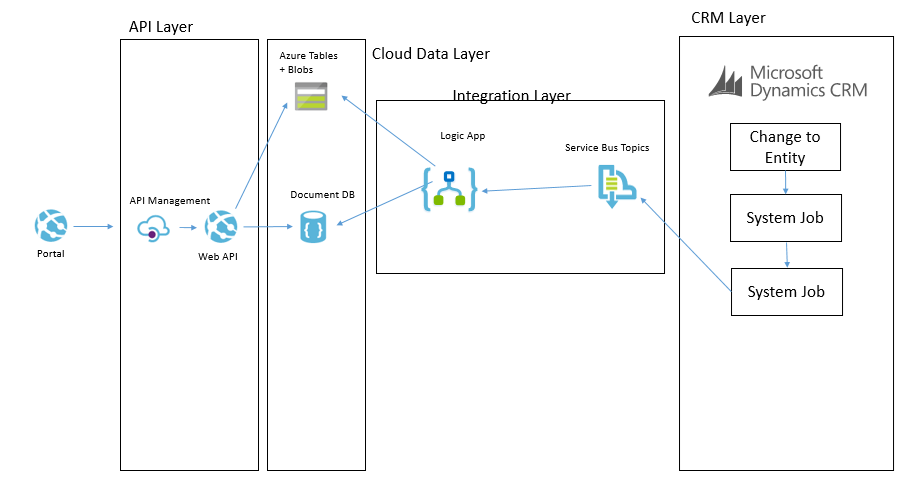
CRM Entity Sync to Cloud Data Layer
One of the other ways we can populate the cloud data layer from CRM is via a with a job that will copy data. There are a few different ways this can be done. The main way will involve executing a fetch xml query against CRM to retrieve all of the records from an entity or all of the records that have been changed recently. They will then be pushed over to the cloud data layer and stored in one of the data stores depending on which is used for that data type. It is likely there will be some form of transformation on the way too.
An example of where we may do this is if we had a list of reference data in CRM such as the nationalities of contacts. We may want to display this list in the portal but without querying CRM directly. In this case we could copy the list of entities from CRM to the cloud data layer on a weekly basis where we copy the whole table. There are other cases where we may copy data more frequently and we may use different data sources in the cloud data layer depending upon the data type and how we expect to use it.
The below example shows how we may use BizTalk to query some data from CRM and then we may send messages to table storage and Cosmos DB.
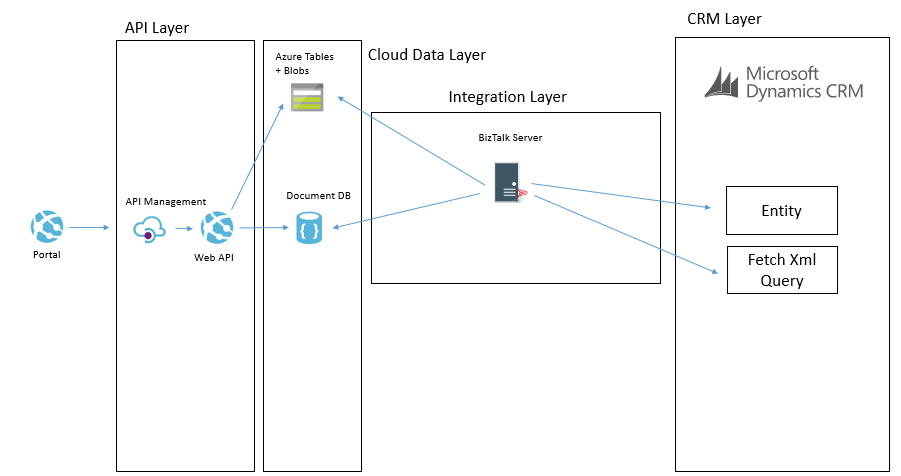
Another way we may solve this problem is using Data Factory in Azure. In Data Factory we can do a more traditional ETL style interface where we will copy data from CRM using the OData feeds and download it into the target data sources. The transformation and advanced features in Data Factory are a bit more limited but in the right case this can be done like in the below picture.
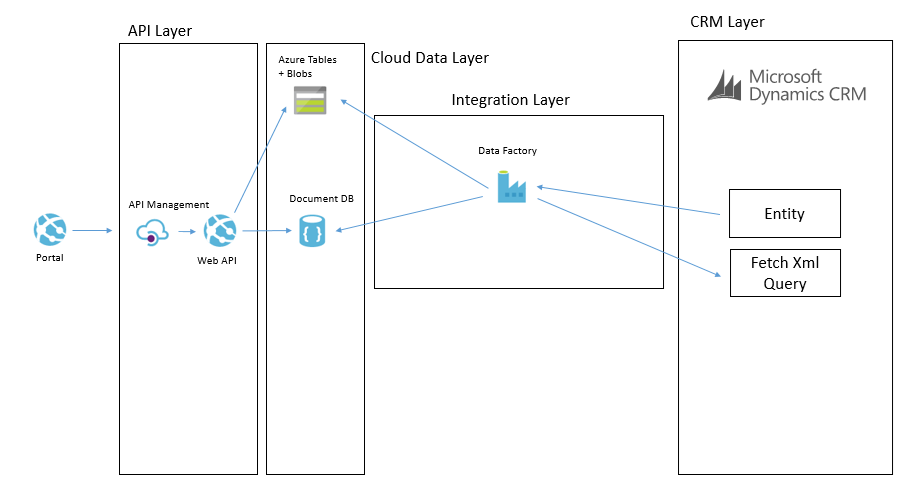
In these data synchronisation interfaces it will tend to be data that doesn’t change that often and data which you don’t need the real time event to update it which it will work the best with. While I have mentioned Data Factory and BizTalk as the options we used, you could also use SSIS, custom code and a web job or other options to implement it.
Summary
Hopefully the above approach gives you some ideas how you can build a high performing portal which integrated with CRM Online and potentially other applications but by using a slightly more complex architecture which introduces asynchronous processing in places and CQRS in others you can create a decoupling between the portal(s) you build and CRM and other back end systems. In this case it has allowed us to introduce a data layer in Azure which will scale and perform better than CRM will but also give us significant control over things rather than having a bottle neck on a black box outside of our control.
In addition to the performance benefits its also potentially possible for CRM to go completely off line without bringing down the portal and only having a minimal effect on functionality. While the cloud data layer could still have problems, firstly it is much simpler but it is also using services which can easily be geo-redundant so reducing your risks. An example here of one of the practical aspects of this is if CRM was off line for a few hours while a deployment is performed I would not expect the portal to be effected except for a delay in processing messages.
I hope this is useful for others and gives people a few ideas to think about when integrating with CRM.
by michaelstephensonuk | Jul 2, 2017 | BizTalk Community Blogs via Syndication
Recently I wrote an article about how I was uploading bank info from Barclays to my Office 365 environment and into a SharePoint list.
http://microsoftintegration.guru/2017/06/29/logic-apps-integration-for-small-business/
In the article I got the scenario working but I mentioned that I didn’t really like the implementation too much and I felt sure there were tidier ways to implement the Logic App. This prompted swapping a few emails with Jeff Holland on the product team at Microsoft and he gave me some cool tips on how best to implement the pattern.
At a high level the actions required are:
- Receive a message
- Look up in a SharePoint list to see if the record exists
- If it exists update it
- If it doesn’t exist then create it
In the rest of the article ill talk about some of the tweaks I ended up making.
Get Item – Action – Doesn’t help
First off I noticed there was a Get Item action in the list which I hadn’t noticed the other day so I thought id have a look and see if it would do the job for me. I set up my test logic app as below.
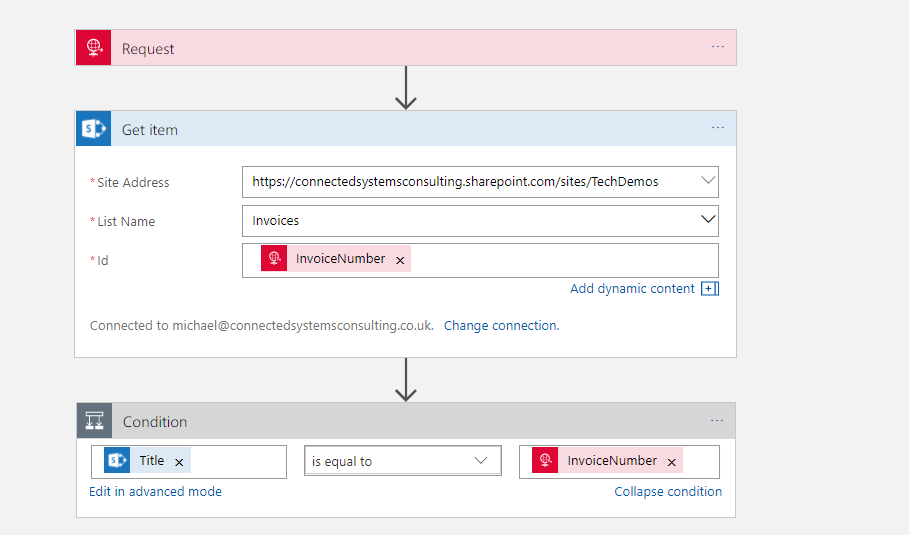
The problem here however is that Get Item requires the ID which appears to resolve to a sort of internal id from SharePoint. In the real world your unlikely to have this id in other systems and you cant set the id when creating a record so I imagine its like an auto number. I quickly found Get Item wasn’t going to help short cut my implementation so it was back to Get Items.
In the picture below you can see how I use Get Items with a filter query to check for a record where the Title is equal to the invoice number. In my implementation I decided to store the unique id for each invoice in the Title field as well as in a custom Invoice Number field. This makes the look up work well and also to be explicit I set the maximum get count property to 1 so I am expecting either an empty array if it’s a new record or an array with 1 element if the record already exists.
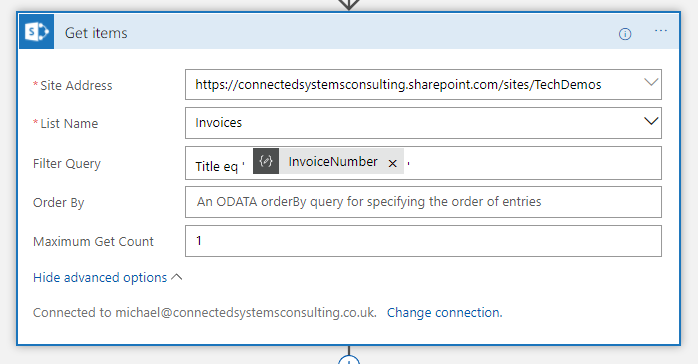
Getting Json for Single SharePoint Item
The next problem after the look up is working with the object from the array. I didn’t really fancy working with complex expressions to reference each property on the item in the array or doing it in an unnecessary loop so my plan was to try and create a reference to the first element in the array using a json schema and the Parse Json action.
To do this I left my Logic App in a position where it just did the look up and I then called it from Postman like in the picture below.
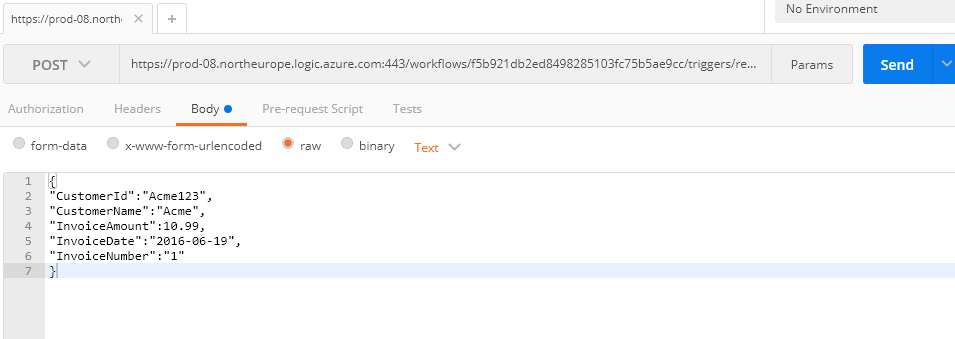
When the Logic App executed I was able to go into the diagnostics of the run and look at the Get Items to see the Json that was returned. (id already manually added 1 record to the SharePoint list so I knew id get 1 back). In the picture below you can see I opened the execution of Get Items.
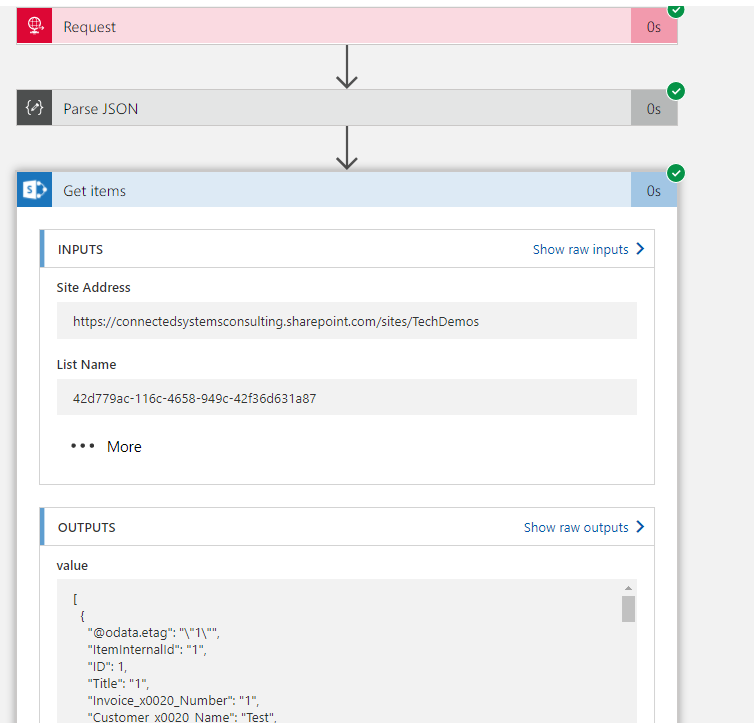
In the outputs section I can see the Json returned from the action and I copied this into notepad. I then removed the square brackets from the start and end which turn the json into an array. What im left with is the json representing the first element in the array. I put this to one side and kept it for later.
Make the Lookup Work
Now we wanted to make the look up work properly so lets review what id done so far. First off I had my request action which receives data over http. As a preference I tend to not add a schema to the request unless it’s a Logic App im calling from another Logic App. I prefer to use a Parse Json with a schema as the 2nd step. Ive just felt this decouples it a little and gives me scope to change stuff around a little more in the Logic App without the dependency on Request. A good example of this was once I needed to change the input from Request to Queue and if I had used the schema on Request it would have meant changing the entire logic app.
Anyway so we parse the json and then execute Get Items like we discussed above.
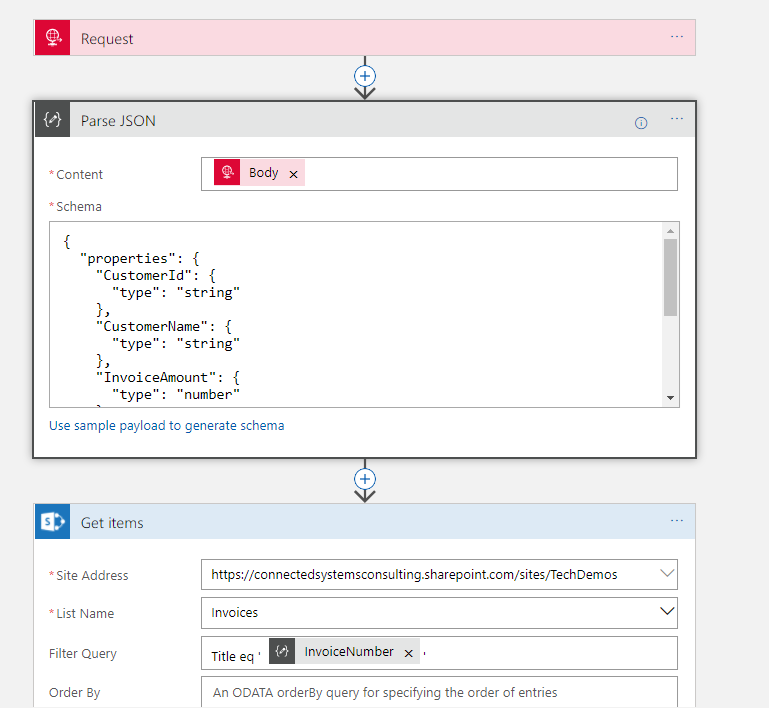
At this point I know im above to execute the Logic App and get a single element array if the invoice exists and an empty array if it doesn’t.
Workout if to Insert of Update
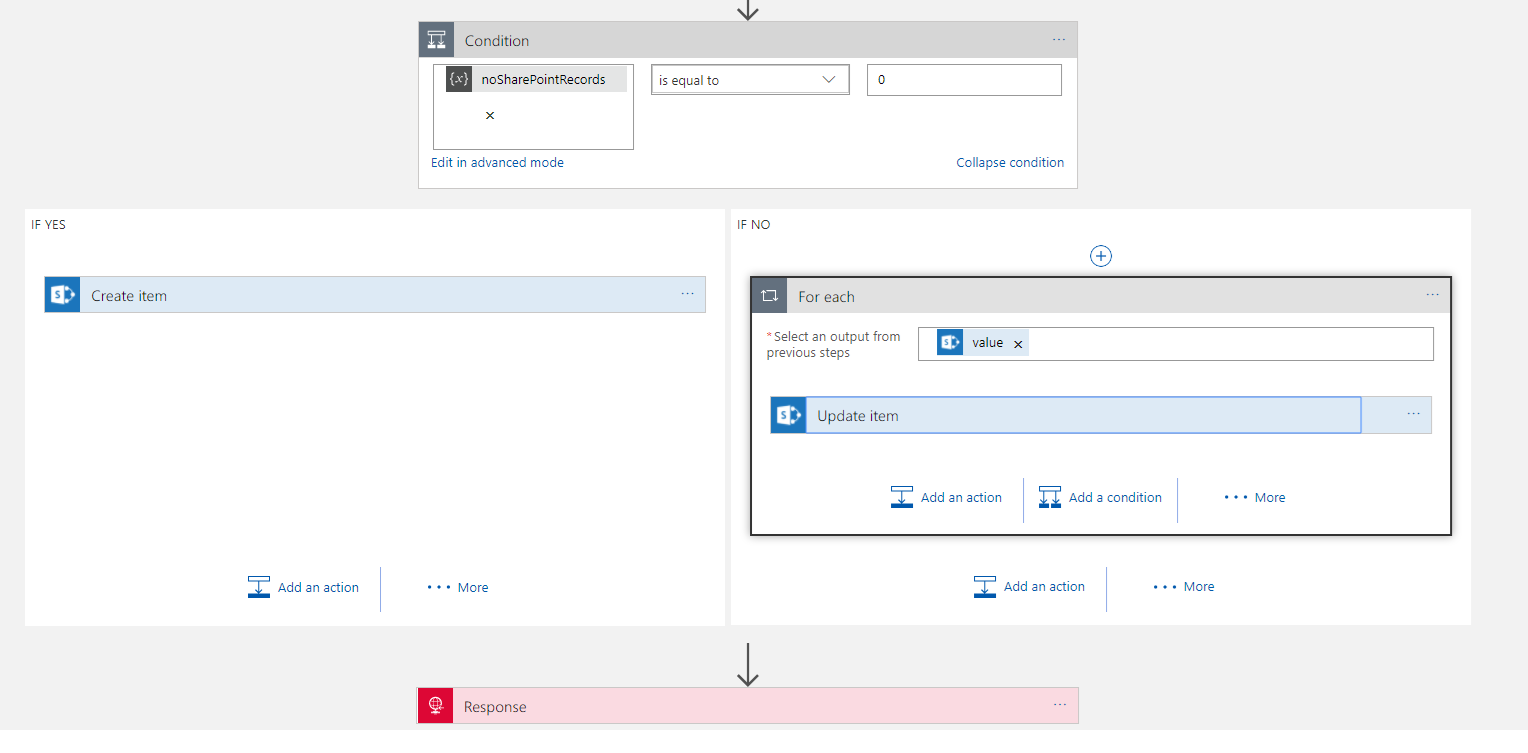
The next step which Jeff gave me some good tips on was how to workout if to do the insert or update. Previously id don’t this weird little counter pattern to count the elements in the array then decide the branch to execute based on that, but Jeff suggested an expression which can check for an empty array.
In the below picture you can see the expression checks the Get Items action and sees if the value is empty.
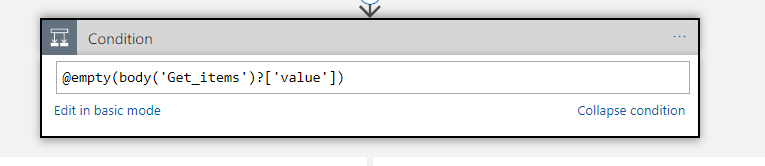
This has greatly simplified my condition so im happy!
The Create
The creation step was really just the same as before. We flow in properties from the inbound json into fiends on the SharePoint list and it gets created. See below pic.
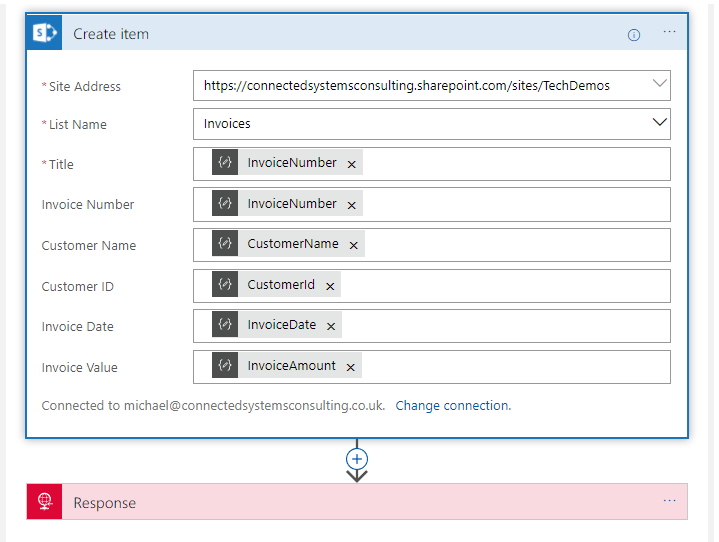
The Update
The bit where things got tidier is in the update. Previously I had a loop around the update action meaning it was executed once for every element, even though there should only ever be 1 element. While this works it looked untidy and didn’t make sense in the Logic App. I knew if I looked at it in 6 months time it would be a WTF moment. The problem was that for the update we need some fields from the query response and some fields from the input json to pass to the update action and it was awkward to make them resolve without the loop.
Combining Jeff’s tips and a little item of my own I decided to use the Parse Json action and the json id put to one side earlier which represented a single element in the Get Items response array. I used this json to have a schema for that item from the list and then in the content of the action Jeff suggested I used the @first expression. This basically meant that I could have a new pointer to that first element in the array which means when I used it downstream in the logic app I can reference it with nice parameters instead of repeatedly using the expression.
The below picture shows how I did this.
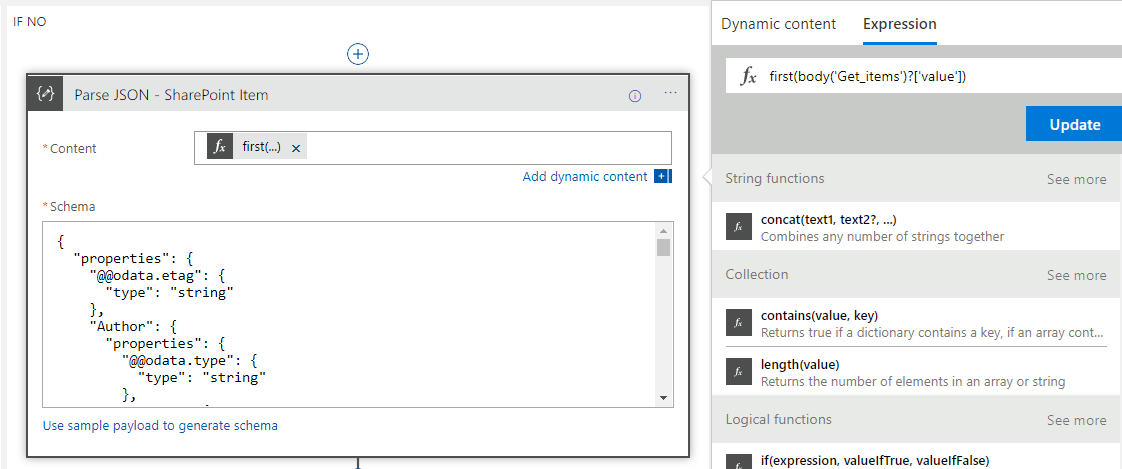
The next step was to do the Update Item action. At this point I effectively have pointers to two objects in the Logic App created by the Parse Json. The first is the input object and the second is the item queried from SharePoint. I now simply had to map the right properties to the right fields on the update action like in the below picture.

One caveat to note is that although the icons look the same the fields above actually come from 2 different Parse Json instances.
Wrap Up
At this point it now meant that when I execute my logic app via Postman I now get the SharePoint list updated and having new items inserted exactly as I wanted. Below is a pic of the list just to show this for completeness.
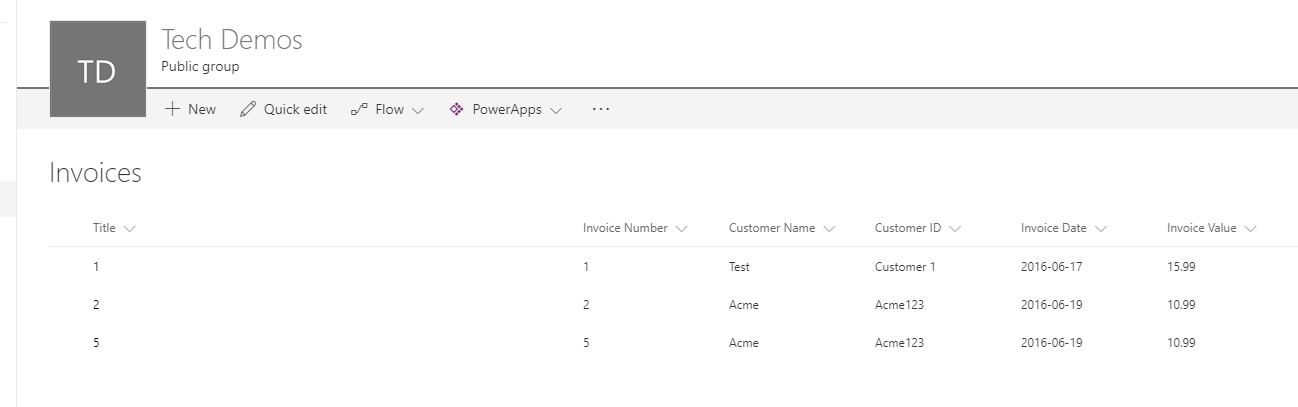
Also the below picture shows the full Logic App so you can see it all hanging together
In summary with some help from Jeff I am much happier with how I implemented this upsert functionality. Ive said a few times it will be better when the API connectors support this functionality so the Logic App doesn’t need to care and becomes much simpler, but to be fair most API implementations tend to go for basic CRUD approaches so its common to face this scenario. Hopefully with the write up above that will make it easier for everyone to be able to write a tidier implementation of this pattern. I have a feeling it will be quite reusable for other application scenarios such as CRM which have similar API connectors. Maybe there is even the opportunity for these to become Logic App templates.

by michaelstephensonuk | Jun 29, 2017 | BizTalk Community Blogs via Syndication
When Logic Apps was first announced at the Integrate summit in Seattle a few years ago one of my first comments was that I felt that this could be an integration game changer for small business in due course. The reason I said this was if you look across the vendor estate for integration products you have 2 main areas. The first is the traditional integration broker and ESB type products such as BizTalk, Oracle Fusion, Websphere and others. The 2nd area is the newer generation of iPaas such as Mulesoft, Dell Boomi, etc. While the technicalities of how they solve problems has changed and their deployment models are different they all have 1 key thing in common. They all view integration as a high value premium thing that customers will pay a lot of money to do well.
This has always rules them out of the equation for small business and meant that over the years many SME companies will typically implement integration solutions with custom code from their small development teams. This was often their only choice and made it difficult because as they grow they would reach a point where they got to a certain size yet their integration estate would be a mess of custom scripts, components and other things.
What excites me with Logic Apps is that Microsoft have viewed the cost model in a different way. While it is possible to spend a lot of money on some premium features it is also possible to create complex integration solutions that have zero up front cost and a running cost of less than a cup of coffee. This mindset that integration is a commodity not a premium service can be put forward by Microsoft because they have a wide cloud platform and offering low cost integration will increase the compute usage by customers across their cloud platform. Other than the big cloud players such as AWS and Google its much harder for them to think of integration in this way because the vendor doesn’t have the other cloud features to offer. Likewise AWS and Google who do have the platform play don’t have any integration heritage so this puts
Outside of the integration companies, small business has looked at products like Zapier and IFTTT for a few years but these products can only go so far in terms of complexity of processes you want to implement.
Microsoft in a unique position where they have an integration offering with something for the biggest enterprise right down the scale to something for a one man band.
In Microsoft world if you’re a small company the likelihood is your using Office 365, there are some great features available on that platform and for my own small business ive been an Office 365 user for years. One example of how I use it is for my accounts and business finance. While I use it a lot, I do have one legacy solution in place from my pre-office 365 days. I had a Microsoft Access database which I wrote a small console app which would load transactions from the CSV files from my bank into it so I could process them and keep my accounts up to date. Ive hated this access solution for years but it did the job.
I have decided that now is a good opportunity to migrate this to Office 365 along with the rest of my accounts and finance info and this will let me get rid the console app.
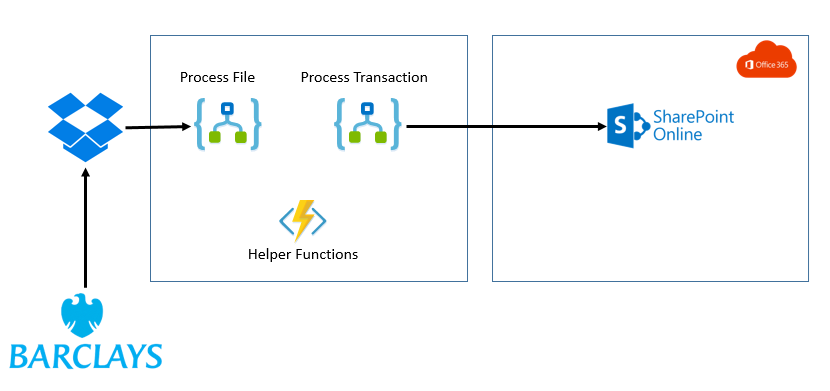
The plan for this new interface was to use Logic Apps to pick up the csv file I can download from my bank and then load the transactions into an Office 365 SharePoint list and then copy the file into a SharePoint document library for back up.
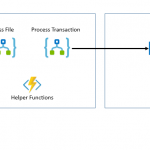
At a high level the architecture will look like the below picture.
While this integration may seem relatively straightforward there were a few hoops to jump through so I thought it might be interesting to share the journey.
Issues with Barclays File
First off the thing to think about would be the Barclays file. I will always have to download this manually (it would be nice if I could get them to deliver it to be monthly). The file was a pretty typical CSV file but a couple of things to consider.
First there is no unique id for each transaction!! – I found this very strange but the problem it causes is each time I download the file the same transaction may be in multiple files. A file would typically have around 3 months data in it. This means I need to check for transactions which have already been processes.
2nd there is a number field in the file but this is not populated so ill ignore this for now.
3rd and most awkwardly is that its possible to have 2 or more rows in the file which would be exactly the same but refer to different transactions. This happens if you pay the same place 2 or more times with the same amount on the same day. Id have to figure out how to handle this.
Logic App – Load Bank Transactions
I was going to implement the solution with 2 logic apps. The first one will collect the file, it will then process the file and do a loop over each record but each record will be processed individually by a separate Logic App. I like this separation as it makes it easier to test the Logic Apps.
Before I get into the details of the logic apps, the below picture shows what the logic app looks like.
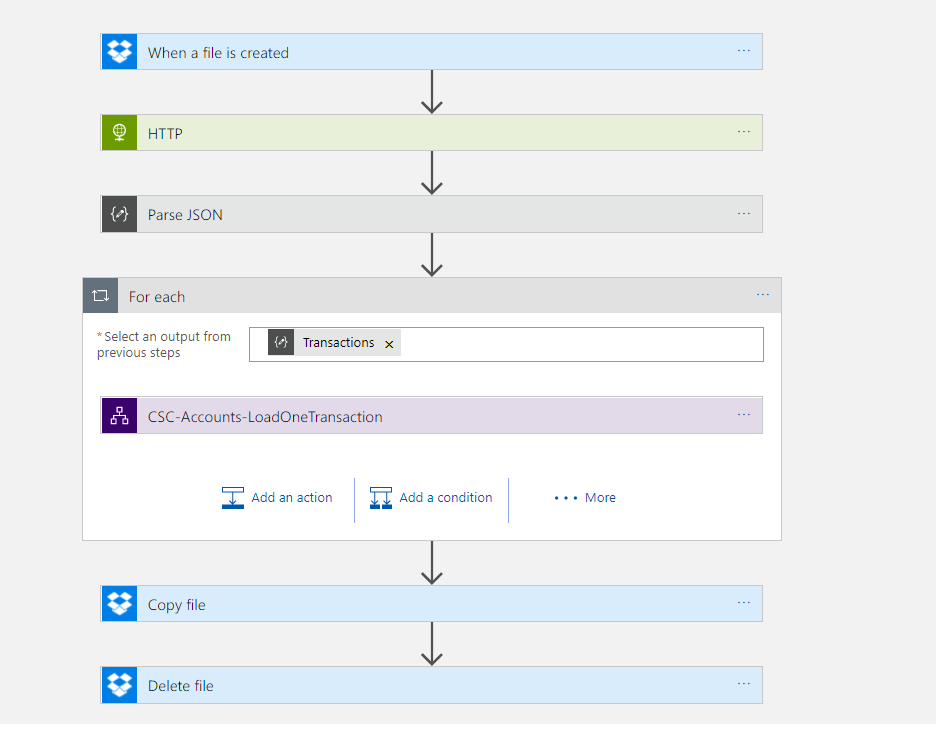
The main bit that is interesting in this Logic App is the parsing of the csv file. With Logic Apps if you have plenty of money to spend you can get an Enterprise Integration Account which includes flat file parsing capability. Unfortunately however I am a small business so I cant justify this cost. Instead I took advantage of the Azure Functions. In the Logic App I pass the file content to a function and then in the function I processed each line from the file and created an object model which will be returned as Json which will make the rest of the processing much easier.
In the function it was easy for me to use some .net code to do a bit of logic on the data and also to do things like trying to identify the type of transaction.
The big positive is using the consumption plan for Functions this means the cost is again very very cheap.
One interesting thing to note was I had some encoding issues calling the function from the logic app using the CSV data. I didn’t really get to workout the root cause of this as I could call it fine in Postman but I think its something about how the Logic App and its function connector encapsulate the call to the function. Fortunately it was really easy to work around this because I could just call the function with the HTTP connector instead!
The only other interesting point is I made the loop sequential just to keep processing simple so I didn’t have to worry about concurrency issues.
Azure Function Parse Bank Data
In the Azure Function I chose to tackle the problem of the duplicate looking transactions. The main job of the function was to convert the CSV data to JSON but I did a little extra processing to simplify things. One feature I implemented was to add a row key field. This would be used to populate the title field in the sharepoint list. This means id have a unique key to look up any existing records to update.
When calculating the row key I basically used the text from the entire row which in most cases was unique. As I processed records I checked if there was a transaction which already had that key. If it did I would add a counter to the end of it so if there were 3 rows with a row key id add a -2 and -3 to the 2nd and 3rd instances of the for to make them unique.
This isn’t the nicest solution in the world but it does work and gets us past the limitation from the Barclays data.
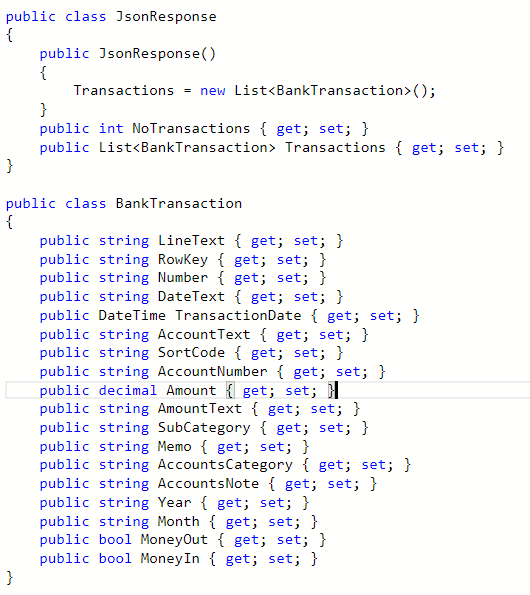
Response Object
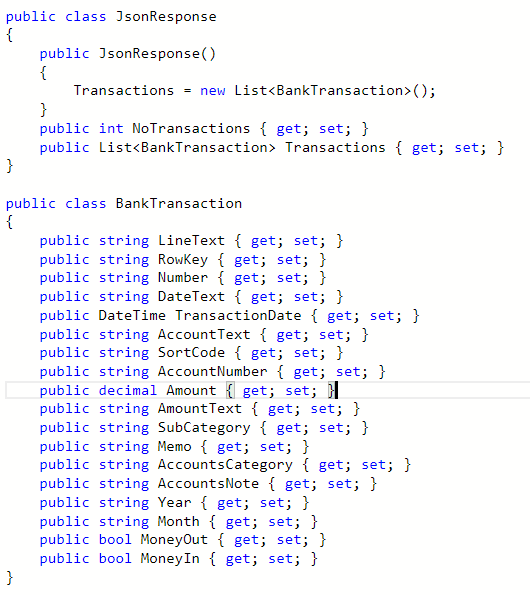
Below is an picture of the response object returned from the functions so you can see its just an object wrapping a list of transactions.
Logic App – Load Single Transaction
Once I have my data in a nice JSON format, the parent Logic App would loop the records and call the child Logic App for each record. Below is a picture of the child Logic App.
In this next section I am going to talk about how I implemented the solution. Please note that while this works, I did have a chat with Jeff Holland afterwards and he advised me on some optimisations which I am going to implement which will make this work a little nicer. I am going to blog this as a separate post but this is based on me working through how to get it to work with designer only features.
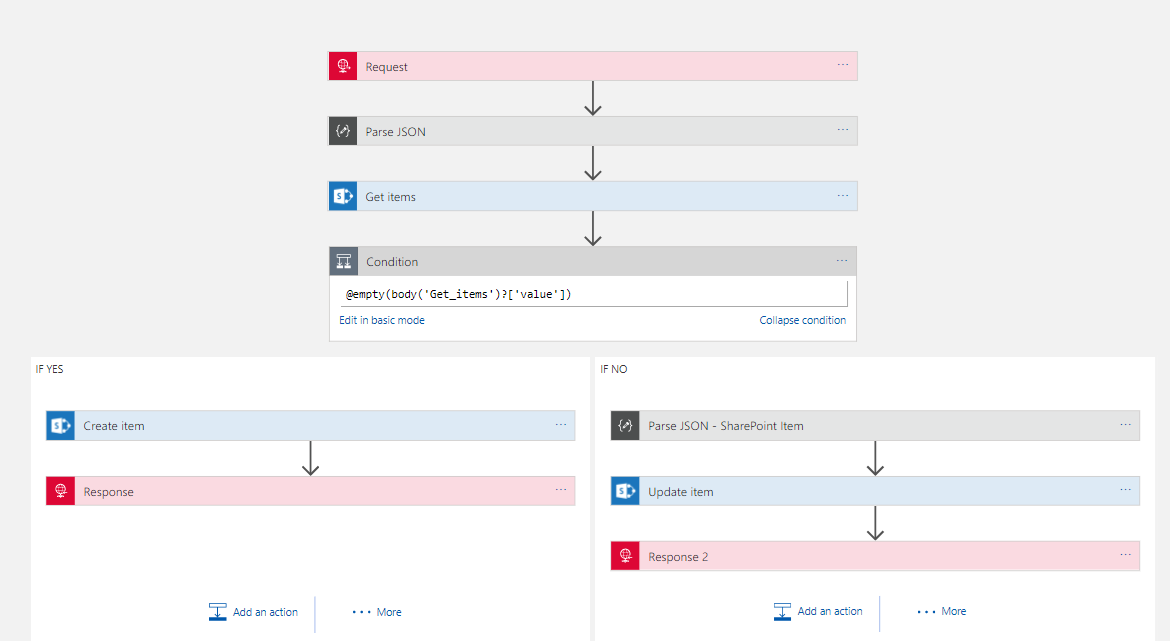
What’s interesting about this Logic App was the hoops to do the upsert style functionality. First off I needed to use the SharePoint Get Items with a query expression to “Title eq ‘#Row Key#’”. This would take the row key parameter passed in and then get any matches. I also used the return max records 1 setting as there would only be 1 match.
I also initialized a variable which I then counted the number of records in the logic app array that was returned. In my condition I could check the record could to see if there was a match in the query of SharePoint which would direct me to insert or update.
From here the Insert Item action was very straight forward but the Update Item was a little more fiddly. Because get items was an array I needed to put the Update inside a loop even though I know there is only 1 row. In the upsert I could use either fields from the input object or the queried item depending if I want to change values or not.
At this point I now had a working solution which took me about 2-3 hours to implement and test and I now have migrated my bank transaction processing into Office 365. The Azure upfront cost for the solution was zero and the running costs is about 50 pence each time I process a file.
Summary
As you can see this integration solution is viable for a small business. The main expense is manpower to develop the solution. I now have a nice sandboxed integration solution in a resource group in my companies Azure subscription. Its easy to run and monitor/manage. The great thing is these kind of solutions can grow with my business.
If you think about it this could be a real game changer for some small businesses. When you think about B2B business, often its about how smoothly and well integrated two business can be that is the differentiator between success and failure. Typically big organisations are able to automate these B2B processes but now with Azure integration a very small business could be able to implement an integration solution on the cloud which could massively disrupt the status quo of how B2B integration works in their sector. When you consider that those smaller business also don’t have the slow moving processes and people/politics of big business this must create so many opportunities for forward thinking SME organisations.
by michaelstephensonuk | Jun 29, 2017 | BizTalk Community Blogs via Syndication
When Logic Apps was first announced at the Integrate summit in Seattle a few years ago one of my first comments was that I felt that this could be an integration game changer for small business in due course. The reason I said this was if you look across the vendor estate for integration products you have 2 main areas. The first is the traditional integration broker and ESB type products such as BizTalk, Oracle Fusion, Websphere and others. The 2nd area is the newer generation of iPaas such as Mulesoft, Dell Boomi, etc. While the technicalities of how they solve problems has changed and their deployment models are different they all have 1 key thing in common. They all view integration as a high value premium thing that customers will pay a lot of money to do well.
This has always rules them out of the equation for small business and meant that over the years many SME companies will typically implement integration solutions with custom code from their small development teams. This was often their only choice and made it difficult because as they grow they would reach a point where they got to a certain size yet their integration estate would be a mess of custom scripts, components and other things.
What excites me with Logic Apps is that Microsoft have viewed the cost model in a different way. While it is possible to spend a lot of money on some premium features it is also possible to create complex integration solutions that have zero up front cost and a running cost of less than a cup of coffee. This mindset that integration is a commodity not a premium service can be put forward by Microsoft because they have a wide cloud platform and offering low cost integration will increase the compute usage by customers across their cloud platform. Other than the big cloud players such as AWS and Google its much harder for them to think of integration in this way because the vendor doesn’t have the other cloud features to offer. Likewise AWS and Google who do have the platform play don’t have any integration heritage so this puts
Outside of the integration companies, small business has looked at products like Zapier and IFTTT for a few years but these products can only go so far in terms of complexity of processes you want to implement.
Microsoft in a unique position where they have an integration offering with something for the biggest enterprise right down the scale to something for a one man band.
In Microsoft world if you’re a small company the likelihood is your using Office 365, there are some great features available on that platform and for my own small business ive been an Office 365 user for years. One example of how I use it is for my accounts and business finance. While I use it a lot, I do have one legacy solution in place from my pre-office 365 days. I had a Microsoft Access database which I wrote a small console app which would load transactions from the CSV files from my bank into it so I could process them and keep my accounts up to date. Ive hated this access solution for years but it did the job.
I have decided that now is a good opportunity to migrate this to Office 365 along with the rest of my accounts and finance info and this will let me get rid the console app.
The plan for this new interface was to use Logic Apps to pick up the csv file I can download from my bank and then load the transactions into an Office 365 SharePoint list and then copy the file into a SharePoint document library for back up.
At a high level the architecture will look like the below picture.
While this integration may seem relatively straightforward there were a few hoops to jump through so I thought it might be interesting to share the journey.
Issues with Barclays File
First off the thing to think about would be the Barclays file. I will always have to download this manually (it would be nice if I could get them to deliver it to be monthly). The file was a pretty typical CSV file but a couple of things to consider.
First there is no unique id for each transaction!! – I found this very strange but the problem it causes is each time I download the file the same transaction may be in multiple files. A file would typically have around 3 months data in it. This means I need to check for transactions which have already been processes.
2nd there is a number field in the file but this is not populated so ill ignore this for now.
3rd and most awkwardly is that its possible to have 2 or more rows in the file which would be exactly the same but refer to different transactions. This happens if you pay the same place 2 or more times with the same amount on the same day. Id have to figure out how to handle this.
Logic App – Load Bank Transactions
I was going to implement the solution with 2 logic apps. The first one will collect the file, it will then process the file and do a loop over each record but each record will be processed individually by a separate Logic App. I like this separation as it makes it easier to test the Logic Apps.
Before I get into the details of the logic apps, the below picture shows what the logic app looks like.
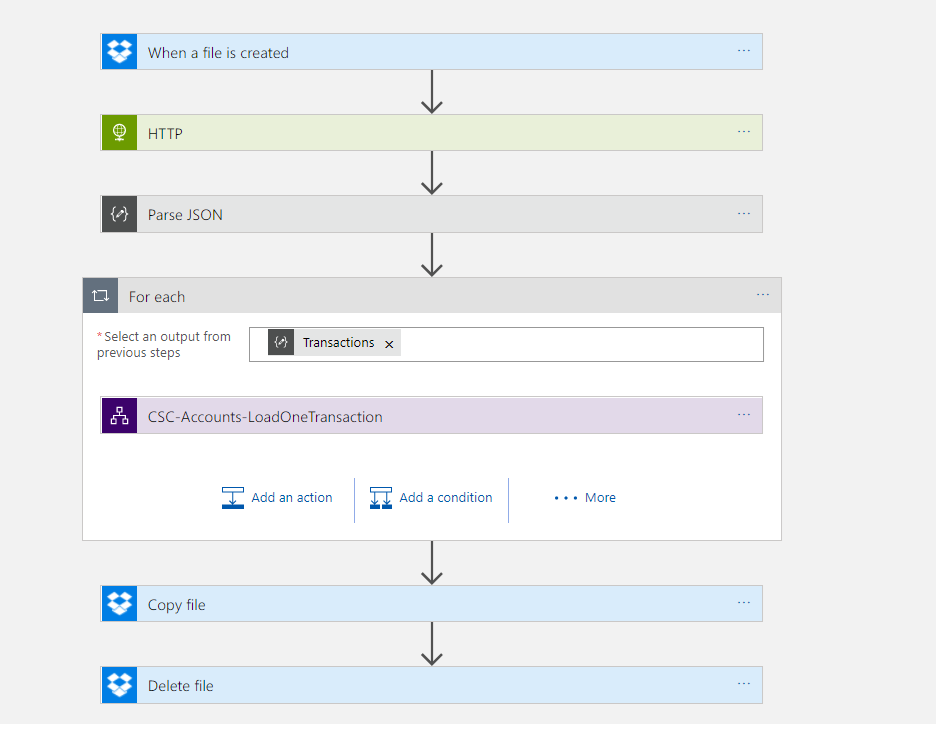
The main bit that is interesting in this Logic App is the parsing of the csv file. With Logic Apps if you have plenty of money to spend you can get an Enterprise Integration Account which includes flat file parsing capability. Unfortunately however I am a small business so I cant justify this cost. Instead I took advantage of the Azure Functions. In the Logic App I pass the file content to a function and then in the function I processed each line from the file and created an object model which will be returned as Json which will make the rest of the processing much easier.
In the function it was easy for me to use some .net code to do a bit of logic on the data and also to do things like trying to identify the type of transaction.
The big positive is using the consumption plan for Functions this means the cost is again very very cheap.
One interesting thing to note was I had some encoding issues calling the function from the logic app using the CSV data. I didn’t really get to workout the root cause of this as I could call it fine in Postman but I think its something about how the Logic App and its function connector encapsulate the call to the function. Fortunately it was really easy to work around this because I could just call the function with the HTTP connector instead!
The only other interesting point is I made the loop sequential just to keep processing simple so I didn’t have to worry about concurrency issues.
Azure Function Parse Bank Data
In the Azure Function I chose to tackle the problem of the duplicate looking transactions. The main job of the function was to convert the CSV data to JSON but I did a little extra processing to simplify things. One feature I implemented was to add a row key field. This would be used to populate the title field in the sharepoint list. This means id have a unique key to look up any existing records to update.
When calculating the row key I basically used the text from the entire row which in most cases was unique. As I processed records I checked if there was a transaction which already had that key. If it did I would add a counter to the end of it so if there were 3 rows with a row key id add a -2 and -3 to the 2nd and 3rd instances of the for to make them unique.
This isn’t the nicest solution in the world but it does work and gets us past the limitation from the Barclays data.
Response Object
Below is an picture of the response object returned from the functions so you can see its just an object wrapping a list of transactions.
Logic App – Load Single Transaction
Once I have my data in a nice JSON format, the parent Logic App would loop the records and call the child Logic App for each record. Below is a picture of the child Logic App.
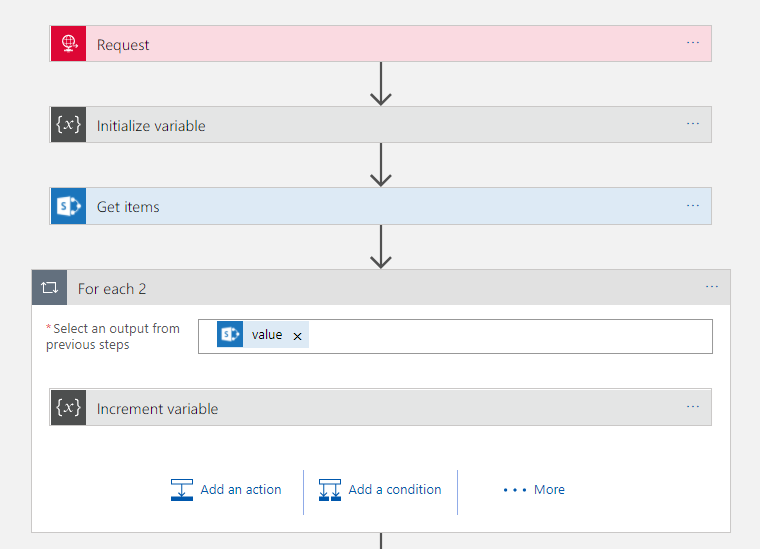
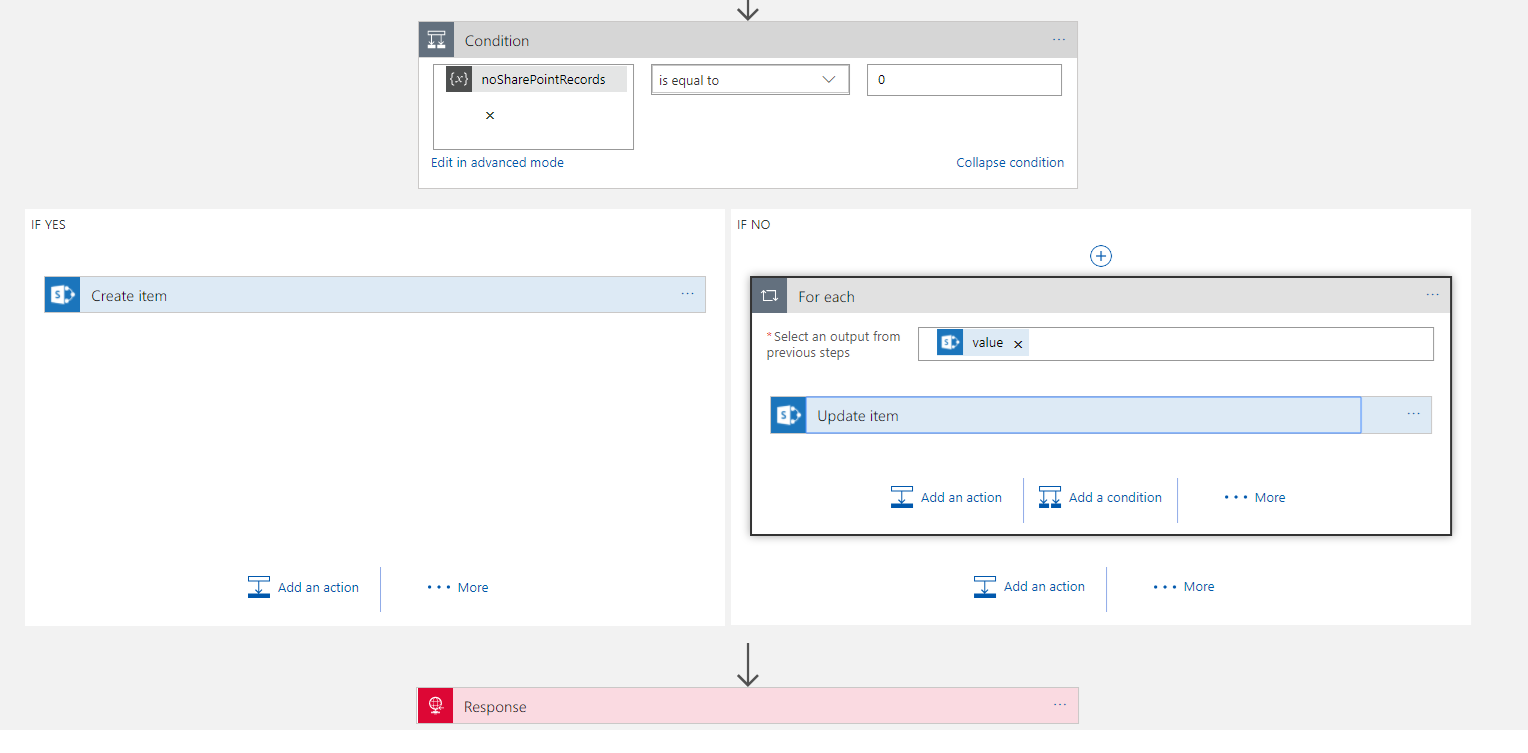
In this next section I am going to talk about how I implemented the solution. Please note that while this works, I did have a chat with Jeff Holland afterwards and he advised me on some optimisations which I am going to implement which will make this work a little nicer. I am going to blog this as a separate post but this is based on me working through how to get it to work with designer only features.
What’s interesting about this Logic App was the hoops to do the upsert style functionality. First off I needed to use the SharePoint Get Items with a query expression to “Title eq ‘#Row Key#’”. This would take the row key parameter passed in and then get any matches. I also used the return max records 1 setting as there would only be 1 match.
I also initialized a variable which I then counted the number of records in the logic app array that was returned. In my condition I could check the record could to see if there was a match in the query of SharePoint which would direct me to insert or update.
From here the Insert Item action was very straight forward but the Update Item was a little more fiddly. Because get items was an array I needed to put the Update inside a loop even though I know there is only 1 row. In the upsert I could use either fields from the input object or the queried item depending if I want to change values or not.
At this point I now had a working solution which took me about 2-3 hours to implement and test and I now have migrated my bank transaction processing into Office 365. The Azure upfront cost for the solution was zero and the running costs is about 50 pence each time I process a file.
Summary
As you can see this integration solution is viable for a small business. The main expense is manpower to develop the solution. I now have a nice sandboxed integration solution in a resource group in my companies Azure subscription. Its easy to run and monitor/manage. The great thing is these kind of solutions can grow with my business.
If you think about it this could be a real game changer for some small businesses. When you think about B2B business, often its about how smoothly and well integrated two business can be that is the differentiator between success and failure. Typically big organisations are able to automate these B2B processes but now with Azure integration a very small business could be able to implement an integration solution on the cloud which could massively disrupt the status quo of how B2B integration works in their sector. When you consider that those smaller business also don’t have the slow moving processes and people/politics of big business this must create so many opportunities for forward thinking SME organisations.
by michaelstephensonuk | May 10, 2017 | BizTalk Community Blogs via Syndication
Every now and then as an architect you would get a request to be able to expose a mapping service for another application to consume and the requirement was preferred if the map was exposed over HTTP so it could be called in real time without the message box over head from executing the map internally to BizTalk.
There were a number of solutions which evolved to do this, even the ESB toolkit offered some of these kind of features.
At the same time on Azure, the integration offerings were dabbling with different ways of implementing a map as a service feature. There were new designers which would be interesting for a while but then never kept up to date with visual studio. More recently the Integration Account on Azure is offering mapping capability as part of a premium costing package if your customer is making a heavy bet on Logic Apps.
I was playing around recently and wondering if I could just run a BizTalk map in a Function?
The answer was yes I could
How do I do it?
To start with I created an input and output schema and a simple map as shown in the picture below.
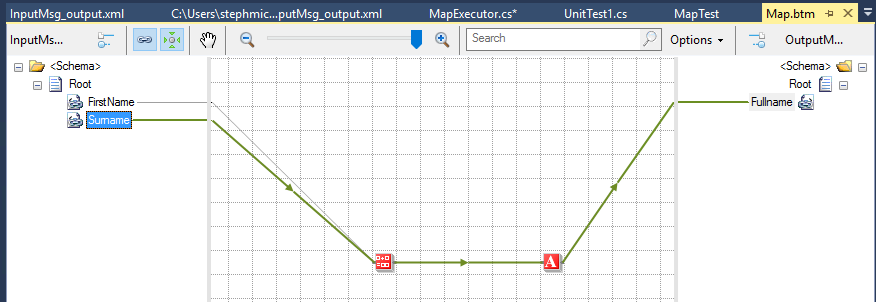
There is nothing complex here and we know from unit testing that we can test a map by calling it directly in C# using the XslCompiledTransform class.
I compiled the BizTalk artefacts in the BizTalk project and left them at that.
Next up I created an Azure function in the normal way and then in the settings I went into the AppService Advanced Editor which allows me to upload stuff to the function. See picture below.
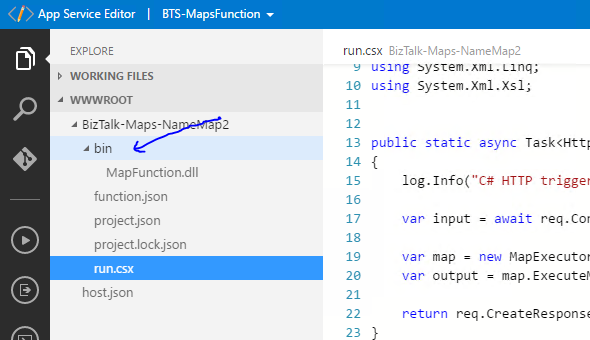
In the function I created a bin directory and uploaded the MapFunction.dll output from my BizTalk project. I also uploaded a number of the BizTalk runtime assemblies (or you can possibly grab these via nuget in the function if its easier).
Next up I used a modified version of the helper class I usually use to test maps when unit testing. This class would instantiate an instance of the map based and then be passed a string which it would use as the input xml for the map and it would return xml.
| public class MapExecutor<TMap>
{
private TransformBase _bizTalkMap;
public MapExecutor()
{
var map = (TMap)Activator.CreateInstance(typeof(TMap));
_bizTalkMap = map as TransformBase;
}
public string ExecuteMap(string input)
{
string outputText = string.Empty;
if (_bizTalkMap == null)
throw new ApplicationException(“The map is null, check it inherits from TransformBase”);
//Save input to disk ready to run map
using (var outputStream = new MemoryStream())
{
var outputWriter = XmlWriter.Create(outputStream);
using (var inputStream = new MemoryStream())
{
var writer = new StreamWriter(inputStream);
writer.Write(input);
writer.Flush();
inputStream.Flush();
inputStream.Seek(0, SeekOrigin.Begin);
var inputReader = XmlReader.Create(inputStream);
//Run the map
XslCompiledTransform transform = new XslCompiledTransform();
XsltSettings setting = new XsltSettings(false, true);
transform.Load(XmlReader.Create(new StringReader(_bizTalkMap.XmlContent)), setting, new XmlUrlResolver());
transform.Transform(inputReader, outputWriter);
outputWriter.Flush();
outputStream.Flush();
outputStream.Seek(0, SeekOrigin.Begin);
var outputReader = new StreamReader(outputStream);
outputText = outputReader.ReadToEnd();
}
}
return outputText;
}
public XsltArgumentList GetExtensionObjects(XDocument extObjects)
{
XsltArgumentList arguments = new XsltArgumentList();
foreach (XElement node in extObjects.Descendants(“ExtensionObject”))
{
string assembly_qualified_name = String.Format(“{0}, {1}”, node.Attribute(“ClassName”).Value, node.Attribute(“AssemblyName”).Value);
object extension_object = Activator.CreateInstance(Type.GetType(assembly_qualified_name));
arguments.AddExtensionObject(node.Attribute(“Namespace”).Value, extension_object);
}
return arguments;
}
}
|
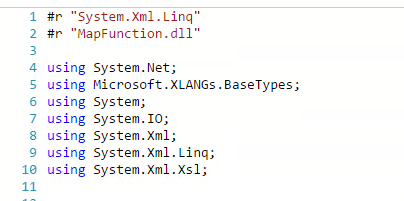
The helper class was pasted directly into the function (or you could put this in a dll if you really wanted) and then I added some using statements for the function and referenced some assemblies in the function like in the below picture.
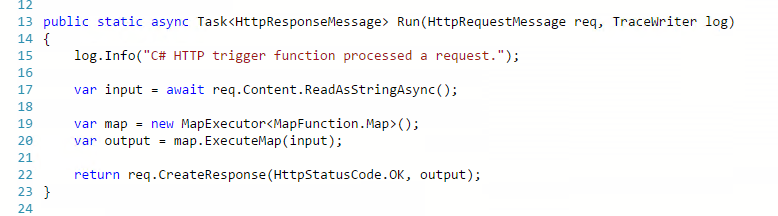
I then modified the method body for a function which is executed over HTTP so that I can read the body as a string, execute my map then return the response. The picture below shows how simple it is to execute the map.
Now we need to test it so fortunately I can use the testing capability in the Azure portal. I added some sample xml for the input to the function and clicked POST
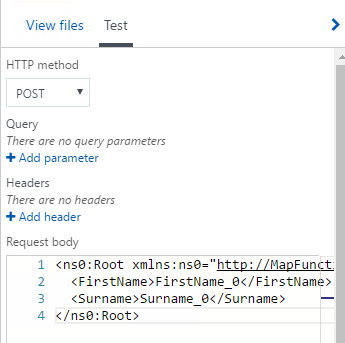
In the function console I can see my map executes and in the test response I can see my output xml.
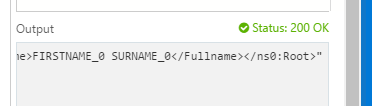
In this case my map has successfully been executed
Finally consuming the mapping function is really easy. Above I used to test function capabilities in the portal but I can execute the function over HTTP using code or something like postman. I simply need the url for the function and a key from the portal, then im good to go.
What about helper assemblies?
I haven’t tried this scenario yet, but Im pretty sure it should work. If your map references a custom .net dll you could just upload it to the function and it should just run the same as we do in unit testing in c#.
Are there limitations?
Im sure there will be a number of limitations to this approach, for example some of the functoids in a map will be unusable. An example would be if you wanted to use the database connector functoids they will obviously not have line of sight to the database. Any functoids which don’t have external dependencies should work.
I think if you can get it to work with a C# unit test then you should be able to make it work in a function.
I know I can, but should I?
I think the problem with this approach however is you are almost definitely going to be in a grey area around licensing. I know there are some cases where having a BizTalk Enterprise license allows you to use BizTalk artefacts on non BizTalk servers. Im thinking the BizTalk WCF LOB Adapters and I think there is also a scenario with the rules engine too.
With respect to the developer SDK and runtime its probably more of a grey area and im sure the initial answer would probably be that you cant do this.
What would we like to see?
The use case is a valid use case and has been around for years. I would like to see Microsoft offer BizTalk Enterprise customers something like this simply because BizTalk mapper is really mature and is one of the better mappers out there and if they included a feature in Visual Studio where you could develop a map and just right click and deploy as an Azure Function which generated all of the boiler plate code above, this would be a really simple way to build a reusable mapping service with almost no complex overhead. The map could then be consumed by BizTalk, Logic Apps or any other service as its just an HTTP call.
by michaelstephensonuk | May 5, 2017 | BizTalk Community Blogs via Syndication
Recently I had a requirement to extend one of our BizTalk solutions, this solution was around user synchronisation. We have 2 interfaces for user synchronisation, one supporting applications which require a batch interface and one which supports messaging. In this case the requirement was to send a daily batch file of all users to a partner so they could setup access control for our users to their system. This is quite a common scenario when you use a vendors application which doesn’t support federation.
In this instance I was initially under the impression that we would need to send the batch as a file over SFTP but once I engaged with the vendor I found we needed to upload the file to a bucket on AWS S3. This then gave me a few choices.
- Logic Apps Bridge
- Use 3rd Party Adapter
- Look ad doing HTTP with WCF Web Http Adapter
- Azure Function Bridge
Knowing that there is no out of the box BizTalk adapter, my first thought was to use a Logic App and an AWS connector. This would allow the logic app to sit between BizTalk and the S3 bucket and to use the connector to save the file. To my surprise at time of writing there aren’t really any connectors for most of the AWS services. That’s a shame as with the per-use cost model for Logic Apps this would have been a perfect better together use case.
My 2nd option was to consider a 3rd party BizTalk adapter or a community one. I know there are a few different choices out there but in this particular project we only had a few days to implement the solution from when we first got it. Its supposed to be a quick win but unfortunately in IT today the biggest blocker I find on any project is IT procurement. You can be as agile as you like, but the minute you need to buy something new things grind to a halt. I expected buying an adapter would take weeks for our organisation (being optimistic) and then there is the money we will spend discussing and managing the procurement, then there would be the deployment across all environments etc. S3 is not a strategic thing for us, it’s a one off for this interface so we ruled out this option.
My 3rd considered option was remembering Kent Weare’s old blog post http://kentweare.blogspot.co.uk/2013/12/biztalk-2013integration-with-amazon-s3.html where he looked at using the Web Http adapter to send messages over HTTP to the S3 bucket. While this works really well there is quite a bit of plumbing work you need to do to deal with the security side of the S3 integration. Looking at Kents article I would need to write a pipeline component which would configure a number of context properties to set the right headers and stuff. If we were going to be sending much bigger files and making a heavier bet on S3 I would probably have used this approach but we are going to be sending 1 small file per day so I don’t fancy spending all day writing and testing a custom pipeline component, id like something simpler.
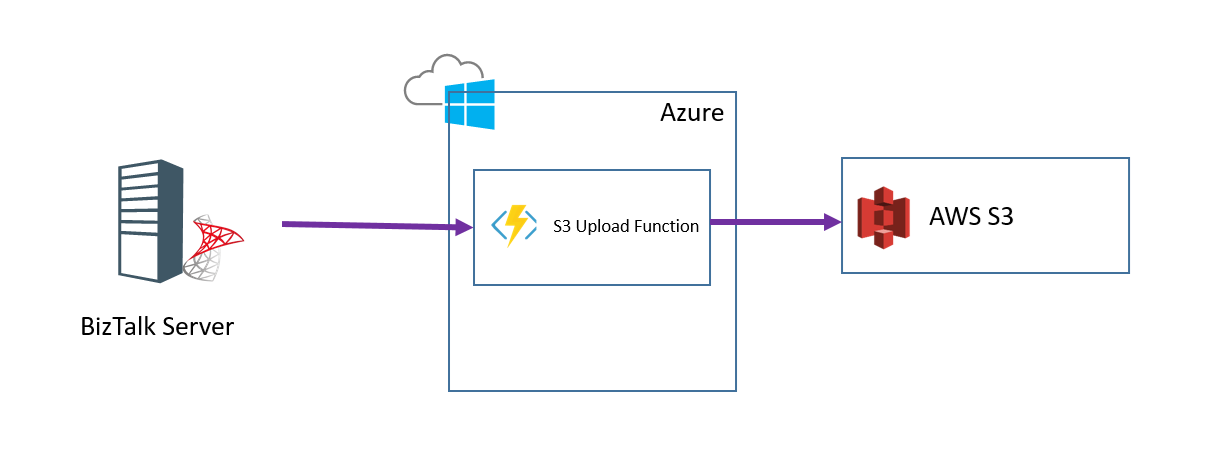
Remembering my BizTalk + Functions article from the other day I thought about using an Azure Function which would receive the message over HTTP and then internally it would use the AWS SDK to save the message to S3. I would then call this from BizTalk using only out of the box functionality. This makes the BizTalk to function interaction very simple. The AWS save also becomes very simple too because the SDK takes care of all of the hard work.
The below diagram shows what this looks like:
To implement this solution I took the following steps:
Step 1
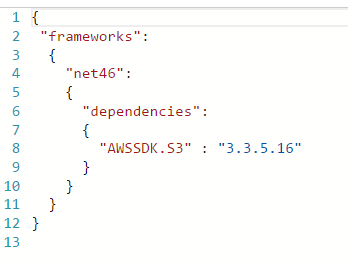
I created an Azure Function and added a file called project.json file in the Azure function I modified the json to import the AWS SDK like in the below picture:
Step 2
In the function I imported the Amazon namespaces
Step 3
In the function I added the below code to read the HTTP request and to save it to S3
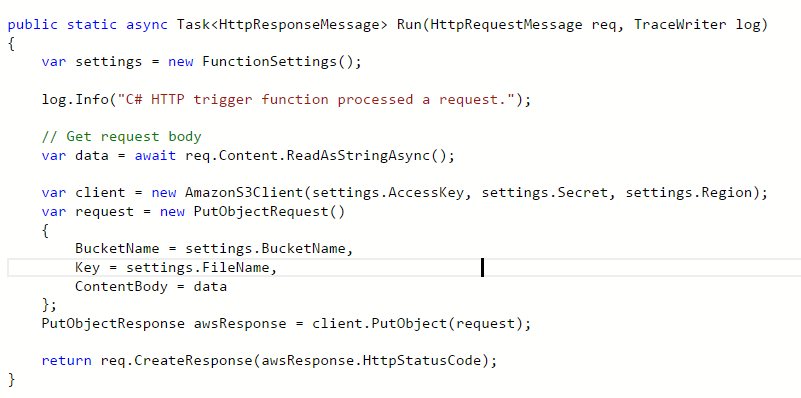
Note that I have a helper class called FunctionSettings which contains some settings like the key and bucket name etc. I am not showing these on the post but you can use the various options for managing config with a function depending upon your preference.
At this point I could now test my function and ensuring my settings are correct it should create a file in S3 when you use the test function option in the Azure Portal.
Step 4
In BizTalk I now added a one way Web Http send port using the address for my function
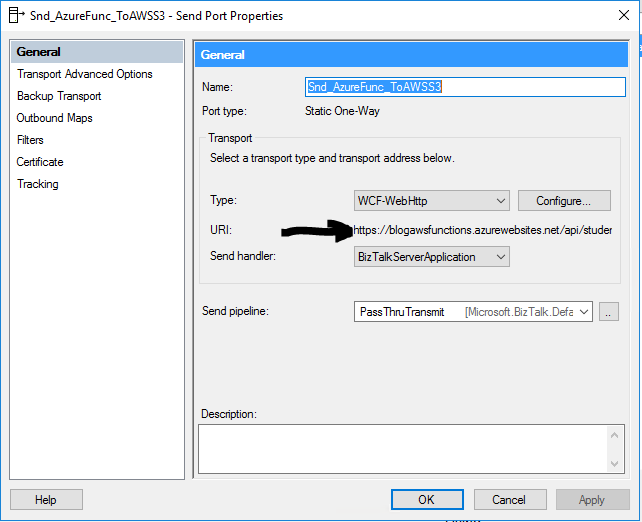
The function address url I can get from the Azure Portal and provides the location to execute my function over HTTP. In the adapter properties I have specified to use the POST http method.
In the message tab for the adapter I have chosen to use the x-functions-key header and have set a key which I generated in the Azure Portal so BizTalk has a dedicated key for calling the function.
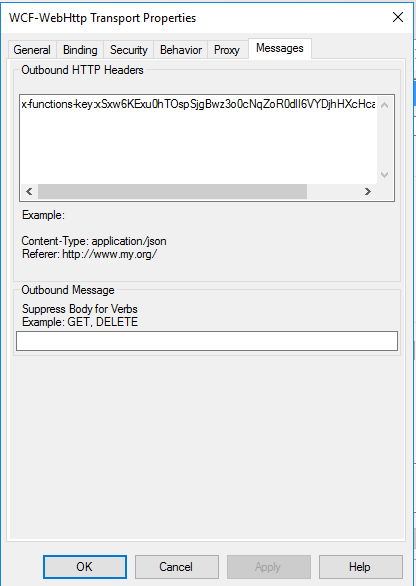
Note you may also need to modify some of the WCF time out and message size parameters.
Step 5
Next I can configure my send port to use the flat file assembler and a map so my canonical message of users is transformed to the appropriate csv flat file format for the B2B partner. At runtime the canonical message is sent to the send port and converted to csv. The csv message is then sent over http to the function and the function will save it to the S3 bucket.
Conclusion
In this particular case I had a simple quick win interface which we wanted to develop but unfortunately one of the requirements we couldn’t handle out of the box with the adapter set we had (S3). Because the business value of the interface wasn’t that high and we wanted this done quickly and cheaply this was a great opportunity to take advantage of the ability to extend BizTalk by calling an Azure Function. In this particular solution I was able to develop the entire solution in a couple of hours and get this into our test environments. The Azure Function was the perfect way to allow us to just get it done and get it shipped so we can focus on more important things.
While some of the other options may have been a prettier architecture or buy rather than build the beauty of the function was that its barely 10 lines of code and its easy to move to one of the other options later if we need to invest more in integration with S3.
by michaelstephensonuk | May 3, 2017 | BizTalk Community Blogs via Syndication
Recently at the Global Integration Bootcamp I talked about a BizTalk 2016 migration and discussed some of the architecture and technical considerations that you might have to consider.
The slides from this are here