
by Saravana Kumar | Dec 29, 2017 | BizTalk Community Blogs via Syndication
Well, it’s almost time to say goodbye to what’s been a fascinating and fantastic year (2017) for BizTalk360 as an organization. It’s now become a tradition to cover the highlights from the year as a blog post. Check out our previous year recap stories: 2016, 2015, 2014, 2013, 2012, 2011
I noticed a pattern — as a product company our activities fall under few big buckets like product development, community activities, conferences, and culture. I’ve structured this post reflecting the major activities in 2017 based on these categories.
Writing this blog gives us the reality of what we have achieved as a team in 2017. Here is the top level summary
- BizTalk360 – 7 releases; (4 major releases + 3 patch releases)
- ServiceBus360 – 13 releases
- BizTalk360 Blogs – 154 Published
- ServiceBus360 Blogs – 44 Published Blogs
- Integration Monday sessions – 40 sessions with ~3500 video views
- Middleware Friday sessions – 46 sessions with ~6500 video views
- New Products: AtomicScope, Document360 (launch Q1 2018)
- Conferences (attended/organized) – Techorama, Microsoft Inspire, Igloo, Global Integration Bootcamp, Global Azure Bootcamp, AI Bootcamp, INTEGRATE UK, INTEGRATE USA, CloudBurst, Azure Day Gurgaon (2 times in 2017)
January 2017
Community: We introduced the Middleware Friday initiative — an idea similar to the Integration Monday initiative that we have been organizing for the past 3 years to bring more value to the integration community. Middleware Friday episodes started off with Kent Weare bringing a video blog on specific integration focused concepts every Friday. Until September, Kent was running a single man show after which Steef-Jan Wiggers joined him and both started to deliver sessions alternatively every week. It’s been a perfect start for Middleware Friday in 2017 — 46 episodes with approximate 6500+ video views of the episodes.
Product update (ServiceBus360): We released an enhanced version of ServiceBus360 with a major overhaul to the pricing model and added new capabilities to the product such as the ability to send events to Azure Event Hubs, Governance and Audit capability, ability to edit and save entity properties, and enhancements to few existing features. You can check out the release notes here.
February 2017
Community: On behalf of our TechMeet360 initiative, we organized a couple of events on Microsoft Integration Technologies at Coimbatore and Microsoft Azure Day in Gurgaon at Microsoft campus. We also covered the updates from the Azure Logic Apps team who came in live from Australia (Microsoft Ignite).
Product update (ServiceBus360): ServiceBus360 got few more new updates this month — a Home dashboard that displays the different namespaces and their configuration information, ability to perform CRUD operations on the Service Bus with more improvements to the existing features.
Product update (BizTalk360): We released version 8.3 of BizTalk360 that included enhancements to the existing Electronic Data Interchange (EDI) capabilities of BizTalk360 such as the EDI Reporting Manager, EDI Reporting Dashboard and EDI Functional Acknowledgement status, new ESB reporting capability with dashboard, introduction of Logic Apps operational capabilities and the Webhook notification channel.
March 2017
Community: As a part of TechMeet360, we organized a meetup to watch Microsoft Visual Studio 2017 launch in our Coimbatore office. This month the team also organized and executed the maiden Global Integration Bootcamp event across two locations – Bengaluru, India and London, United Kingdom. Both the locations had a good turnout attendance for this event.
Culture: This month we extended our UK office with extra space and complete redecoration with playing area for pool/table tennis and table football.

April 2017
BizTalk Server Feature Pack 1: Microsoft BizTalk Server team announced the availability of Microsoft BizTalk Server 2016 Feature Pack 1. We wrote some in-depth blog articles covering the features. Azure Application Insight for Tracking, Advanced Scheduler for Receive Locations Service Window, ALM Continuous Deployment Support with VSTS via Visual Studio, Rest Management API’s, Power BI Operational Template.
Community: Our team organized and executed the Global Azure Bootcamp event at a local college in Coimbatore. We had speakers from the Escalation team at Microsoft, Bangalore for this event. This gave a good chance for our BizTalk360 support staff to have an interaction with the Escalation team and understand how they take customer support and happiness as their top priority.
Product update (BizTalk360): We released version 8.4 of BizTalk360 that included capabilities such as data monitoring for Azure Logic Apps, Folder Monitoring, FTP/FTPS/SFTP monitoring, IBM MQ monitoring, BizTalk Health Monitor (BHM) Integration.
Product update (ServiceBus360): The feature set in ServiceBus360 also gradually increased with the capability to import namespaces entities from Service Bus Explorer, ability to resubmit dead-letter messages from Queues and topics and the relay endpoint monitoring capability. The ServiceBus360 team also got the opportunity to meet Paolo Salvatori at Microsoft, Bengaluru and discuss the road-map for the product.
May 2017
Conference: This month saw the team from Kovai Limited (both India and UK) making their way to Antwerp, Belgium for the Techorama conference.
June 2017
Community: We hit the 100 mark on Integration Monday — 100 sessions in about 30 months! This is quite an achievement from the team given that organizing a session every week is not an easy task. Finding the right speakers, slotting them on the calendar, accommodating last minute schedule changes, sending out newsletters for every week’s event and lot’s more, the team behind has been doing a fantastic job in keeping the integration community active under the Integration User Group banner. For the 100th episode, we wanted to make it really special — the team from the Microsoft Product Group at an open Q&A session with the community.
Conference: Our flagship annual conference INTEGRATE 2017, spanning across 3 full days, had a tremendous response with about 380+ attendees from 50+ countries around the world. We followed up the events with blog posts from all the three days. Here are the links to the articles, in case you missed it. Day 1 blog | Day 2 blog | Day 3 blog
Here’s a short video from our videographer Nigel Camp —
[embedded content]
We also gave away the BizTalk360 Product Specialist and Partner of the Year awards (as with the previous years) during the event. The event finished off in great style, as we announced the US version of INTEGRATE 2017 in October.
Product update (ServiceBus360): We added Analytics of dead letter statistics in Queues, additional notification channel (Microsoft Teams), ability to resubmit and delete messages in Topics, activity configuration for dead letter messages (resubmit, resubmit & delete, delete the message).
July 2017
Conference: July also saw our team from India and UK travel to Washington D.C. for the Microsoft Inspire event. We took a booth at Inspire 2017 to showcase our BizTalk360 and ServiceBus360 product offerings to potential Microsoft partner companies from all over the world.

Community: As part of TechMeet360 initiative, we organized a workshop series on “Getting started with Azure” a Microsoft Technologies Roadshow along with Sri Eshwar College of Engineering. We established our collaboration with Sri Eshwar College of Engineering by setting up a Center of Excellence (CoE) lab that will benefit students to keep them up-to-date on Microsoft Technologies.
Hiring: After 2 days of the rigorous screening process, we were able to offer placement to 5 students from Sri Eshwar College of Engineering.
Culture: As an internal practice, we started conducting quarterly meet-up events to reward the best performers from every team. Being a small company, it’s very important to appreciate the hard work put in by each employee.

Product update (BizTalk360): We released BizTalk360 version 8.5 with new interesting features — BizTalk server host throttling monitoring, flexible email template engine, BizTalk server availability monitoring, Integration account integration within BizTalk360. Read what our partner Integration Team had to say about this release.
Product update (ServiceBus360): For ServiceBus360, this month was really special as we extended our customer base to 6 paid customers (3 new customers). The product started to gain traction in the market and we could definitely see the increase in numbers MoM.
August 2017
Conference: Our team from India (about 6 employees) attended the Design Thinking Summit 2017 at IIM, Bengaluru as part of our learning and improvement program.
Community: We organized a joint webinar with NServiceBus team on the topic “Introducing messaging in your design should not hurt so much“. Saravana Kumar and Sean Feldman delivered the session talking about how you can introduce messaging effectively into your design.
On behalf of TechMeet360, we executed the Microsoft Azure Day event in Gurgaon. An additional feather in the cap moment — TechMeet360 was officially recognized as a community with Microsoft!
Product update (ServiceBus360): We added a couple of new features to ServiceBus360 — the ability to transfer the account ownership to a super user and a new Operations Management Suite (OMS) notification channel. We also engaged with an external firm to work on a Product Discovery Workshop (PDW) to come up with a brand new UI/UX for the ServiceBus360 portal.
September 2017
BizTalk Server: September saw an important update from Microsoft regarding Microsoft BizTalk Server heading in the open source direction. This was definitely a welcome change from Microsoft in the entire 17 years history of BizTalk Server.
Community: The team organized and executed the first global *.ai Bootcamp 2017 at Coimbatore. The topics included AI, Bots, Cognitive Services and Machine Learning.
Conferences: I’ve attended Integration Bootcamp event in Charlotte, North Carolina. A two days event which gave the opportunity to mingle with the product group.
Product update (ServiceBus360): The feature set in ServiceBus360 started to go deeper and deeper with the addition of Logic Apps Management and Monitoring capabilities, Data Monitoring capability, activities to process dead-letter messages from Topic Subscription, Endpoints Monitoring, and advanced User Access Policy.
I also wrote an article on LinkedIn about the challenges of managing a distributed cloud application and the future of ServiceBus360, the direction we were taking to make ServiceBus360 a better product in the market.
October 2017
Culture: We had the quarterly meet for Q3 and in the second week of October. Mid October, about 20 people from our India and UK office traveled to Dubai for the company retreat to honour the efforts of our long-standing employees. It was 4-days of complete fun and frolic, and the team came together to have lots of fun! Here’s a short video of the moments from the trip —.
[embedded content]
Conference: Immediately after the team retreat, our UK team flew across the pond to organize and execute the INTEGRATE 2017 USA event. Scott Guthrie, Executive Vice President at Microsoft, presented the keynote on Day 1 at INTEGRATE 2017 USA event. In case you missed the event updates, you can read the recaps here Day 1 Blog | Day 2 Blog | Day 3 Blog

Product update (Atomic Scope): At INTEGRATE 2017 USA, we made the announcement of our third product – Atomic Scope. Atomic Scope is an end to end Business Activity Tracking and Monitoring tool for hybrid integration solutions involving Microsoft BizTalk Server & Azure Logic Apps. We started working with some of our partners as an early adapter, the product will hit the market in Jan 2018 (public beta and release).
November 2017
November started off quite well, as for me personally, I was invited to Buckingham Palace as part of the Silicon Valley to UK program recognizing “50 scale-up CEO’s” in London (in a segment).

Product update (ServiceBus360): We launched a revamped version of the product (v2.0) with a revamped website as well with new capabilities such as Composite Applications, and bunch of new capabilities such as Management Stack (Azure Service Bus Queues, Topics, Relays, Event Hubs), enhancements to the existing user access policy to cater to the new composite applications concept, ability to repair and resubmit the messages back to queue or topic, and a revised pricing model.
Product update (BizTalk360): Towards the end of November 2017, we also released BizTalk360 version 8.6 with new features such as Reporting Manager (Analytics), event log data monitoring, Microsoft Teams notification channel, BAM related activities and documents and enhancements to existing features as requested by our customers.
December 2017
Product update (Document360): I published an article on LinkedIn about my ambitious idea to build a product in 14 days. We decided to build Document360 (a SaaS product; a self-service knowledge base product for software projects and products) — our fourth product in a hackathon mode in December where we planned to bring the entire company together to work on a single mission — get a minimum viable product (MVP) in 14 days that can be taken to the market. I traveled to India to stay close to the team during the development phase.
So, what did we achieve in 14 days? To answer your question, I compiled this blog post giving a summary of our progress with Document360.
What’s in store for 2018?
2017 has been fabulous for us at Kovai Limited — started off with 2 products (that are pretty much mainstream today) and 2 new products scheduled for GA in Q1 2018. We are continuing to invest in our mainstream products BizTalk360 and ServiceBus360, while at the same time increase the number of products that will solve specific user problems.
We already started planning for INTEGRATE 2018. The event venue is already secured; further announcements related to this event will follow shortly. We will get involved in Global Azure Bootcamp and Global Integration Bootcamp events similar to 2017, so keep a watch out for updates on these events. We have also sorted out the Integration Monday speaker line up for the first 2 months of 2018. We will continue ramping up India focused events like TechMeet360 to build awareness in Integration space.
Thank You! Wishing you a Prosperous New Year 2018
All of the above achievements by us over the last 12 months wouldn’t have been possible without the support from families, friends, employees, customers, and partners. I would like to thank everyone for the support and being a part of the successful journey. Wish you all a Happy and Prosperous New Year 2018!!!
Author: Saravana Kumar
Saravana Kumar is the Founder and CTO of BizTalk360, an enterprise software that acts as an all-in-one solution for better administration, operation, support and monitoring of Microsoft BizTalk Server environments.
View all posts by Saravana Kumar

by Saravana Kumar | Dec 29, 2017 | BizTalk Community Blogs via Syndication
One of the main thing on my agenda on the last working day of the year is to make a donation to GOSH (Great Ormand Street Hospital) charity. I started doing this since we launched BizTalk360 back in 2011.
Here is the summary of what we have contributed to GOSH in the last 5 years with the links to the articles.
bringing the total contribution to ~$36,000.

There are some incredible stories what GOSH has done to young people with challenges like Moment 16-month-old boy hears sound for the first time, Gift of life for little Elliott after long-awaited heart transplant
There are times in life when “thank you” doesn’t seem enough. There are some great people out there doing some incredible things, this is our way of giving little support to them. We hope to do more in the future.
Let the new year brings joy and happiness to everyone.
Author: Saravana Kumar
Saravana Kumar is the Founder and CTO of BizTalk360, an enterprise software that acts as an all-in-one solution for better administration, operation, support and monitoring of Microsoft BizTalk Server environments.
View all posts by Saravana Kumar

by Steef-Jan Wiggers | Dec 22, 2017 | BizTalk Community Blogs via Syndication
The year 2017 almost has come to an end. A year I traveled a lot and spent many hours sitting in planes. In total, I have made close to 50 flights. A bonus at the end of this year is that I have reached gold status with the KLM. Thus I can enjoy the benefit sitting in the lounge like some of my friends. The places I visited in 2017 are Sydney, Auckland, Brisbane, Gold Coast, Melbourne, London, Lisbon, Porto, Olso, Stockholm, Gothenburg, Zurich, Seattle, Rotterdam, Dublin, Prague, Bellevue, Redmond, Adliswil, Ghent, Mechelen, and Montréal (France).

Public speaking in 2017
In 2017 I have spoken at various conferences in the Netherlands and abroad. The number of attendees varied from 20 to 400. My sessions were on the following topics:
– Logic Apps
– Functions
– Cosmos DB
– Azure Search
– Cognitive Services
– Power BI
– Event Grid
– Service Bus
– API Management
– Web API

Besides speaking at local user groups and conferences, I created videos, webinars, blog posts and news articles. The blog posts are available on my blog and the BizTalk360 blog. The news articles for InfoQ, for which I became an editor in November. The latter is something I consider as a great accomplishment.
Middleware Friday 2017
Together with Kent, we put out almost 50 episodes for Middleware Friday. In the beginning, Kent published various videos and later asked me to join the effort. The topics for Middleware Friday in 2017 were:
– Logic Apps
– Functions
– Microsoft Flow
– Cognitive Services: Text, Face, and BOTS
– Operation Management Suite (OMS)
– Event Grid
– Service Bus
– API Management
– Cosmos DB
– Azure Data Lake
– Azure Active Directory
– BizTalk Server
– Event Hubs
– SAP Integration
Creating episodes for Middleware Friday or vlogs was a great experience. It is different than public speaking. However, in the past and also this year I did a few Integration Monday sessions. Therefore, recording for a non-visible audience was not new for me.

Global Integration Bootcamp
Another highlight in 2017 was the first integration boot camp, which I organized with Eldert, Glenn, Sven, Rob, Martin, Gijs and Tomasso. Over 16 locations worldwide join in a full Saturday of integration joy spending time on labs and sessions. The event was a success, and we hope to repeat that in 2018.

Integrate London and US
BizTalk360 organized two successful three-day integration conferences in London and Redmond. At both events, I spoke about Logic Apps discussing its value for enterprises, the developer experience, and cloud-native nature. On stage for a big audience was quite the experience, and I delivered my message.

Personal accomplishments, top five books, and music
Personally, I found 2017 an exciting year with visits to Australia and New-Zealand, completing the Rotterdam Marathon, Royal Parks Half and the many speaking opportunities. Looking forward to my next two marathons in Tokyo and Chicago in 2018 and new speaking engagements.

The top five books in 2017 are:
– The subtle art of not giving a fuck!
– Sapiens – A Brief History of Humankind
– The Gene – An Intimate History
– Blockchain Basics, a non-technical introduction in 25 steps
– The Phoenix Project
The top five metal albums are:
– Mastodon – Emporer of the Sand
– Pallbearer – Heartless
– Caligula’s Horse – In contact
– Enslaved – E
– Leprous – Malina
Thanks everyone for your support in either reading my blogs, articles and or attending my sessions and online videos. Enjoy the winter holidays and merry Christmas and happy new year!
P.S. I might have forgotten a thing or two, but that’s why I created Stef’s monthly update.
Cheers,
Steef-Jan
Author: Steef-Jan Wiggers
Steef-Jan Wiggers is all in on Microsoft Azure, Integration, and Data Science. He has over 15 years’ experience in a wide variety of scenarios such as custom .NET solution development, overseeing large enterprise integrations, building web services, managing projects, designing web services, experimenting with data, SQL Server database administration, and consulting. Steef-Jan loves challenges in the Microsoft playing field combining it with his domain knowledge in energy, utility, banking, insurance, healthcare, agriculture, (local) government, bio-sciences, retail, travel, and logistics. He is very active in the community as a blogger, TechNet Wiki author, book author, and global public speaker. For these efforts, Microsoft has recognized him a Microsoft MVP for the past 8 years.
View all posts by Steef-Jan Wiggers
by Rochelle Saldanha | Dec 21, 2017 | BizTalk Community Blogs via Syndication
In case you haven’t been on social media lately, you may have missed out on the fact that nearly everyone is sharing a photo collage of the past year.
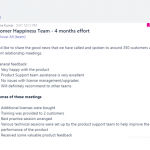
So here’s a blog talking about my past year in BizTalk360 where I (Rochelle) work as a Customer Support Agent as well as being part of the Client Relationship Team.
Support Technical Training
The year started off with a bang, with technical training provided to the Support team so they would understand better the internal workings of the product and furthermore helped them get a better insight into the various troubleshooting steps carried out by Developers during calls.
Support has been a large part of my daily activity, where the team advises customers regarding their technical issues. Besides these, we also do a Best Practice Installation for new customers which helps them set up the product in a 2-hour slot and gets them up and running.
Client Relationship(CR) Team was formed in BizTalk360
This is a new initiative in BizTalk360 to reach the end customers, to understand their pain points and to improve business relationships. It has been a really rewarding experience to actually speak to the customer rather than the typical email chains we actually get to know them better.
Just a few months after starting the program, we expanded the 2-person team to 4 and reached almost 350 customers. We celebrated in the office with a nice cake!
Our team is now in regular contact with most of our customers. Quite a few of the scenarios we faced were customers having minor niggling issues with the product and didn’t know that they could be easily resolved. Moreover, a few of our customers were unaware of the Tracking Manager feature introduced in v8.2 onwards, which could really be helpful to them. We listened to their usage of the product and then identified and suggested possible solutions or workarounds.
Proud to be part of this fun team as well!
INTEGRATE 2017
My first INTEGRATE @BizTalk360. It was an amazing event with so many interesting speakers and the scale was so large. We had 400 participants from all over the world!

We were all given the opportunity to introduce ourselves and a few of the speakers in the events.

We met many of our existing customers and it was wonderful to finally put a face to all the email exchanges we’ve had via Support and the CR teams. BizTalk360 Customers and Partners from all over the world arrived. The 3 days were packed with so many activities – besides organizing and setting up the event, we also took testimonials from our customers on the product BizTalk360 and the entire INTEGRATE experience as well. Can’t wait for next year’s event in June 2018!

Here is one of our customer quotes.
BizTalk360 has made INTEGRATE one of the must attend integration events of the year.
Customer Site visit
BizTalk360 has a lot of features which can be quite overwhelming for someone new. Many companies appreciate an in-depth intensive BizTalk360 training provided by our BizTalk360 Experts. I was given the opportunity to join our BizTalk Administrator/Export on his training session. It was a learning experience to actually see the product being used in action at the customer site and all the possible issues they face when trying to set up the integration environments and monitoring with BizTalk360.
I also joined our Business Development Manager – Duncan to present the product to one of the UK’s leading estate agents in Central London. We hope to make this a more regular occurrence to personally present to companies interested in BizTalk360.
Fun Fridays in the Office
This year we also started Fun Fridays wherein the lunch hour, we have some fun and games. I have organized a few of the team building sessions and everyone really enjoyed them. We played games like HeadsUp(similar to dumb charades) and also had a secret team mission in the office (which was to place an object on another team’s desk without them noticing for a certain period of time).

Christmas Celebrations in the BizTalk360 before the Hackathon begins in India (December)
We celebrated Christmas in style by having a number of events to mark the festive holiday. We had a magician to show us some spectacular tricks, celebrated Secret Santa, and had a lovely meal in a local restaurant.

So that was a quick tour of 2017 in the BizTalk360 Office. As Facebook says
Because a year is made of more than just time,
It’s made of all the people you spent that time with
Author: Rochelle Saldanha
Rochelle Saldanha is currently working in the Customer Support & Client Relationship Teams at BizTalk360. She loves travelling and watching movies.
View all posts by Rochelle Saldanha

by Sandro Pereira | Dec 20, 2017 | BizTalk Community Blogs via Syndication
HO HO HO, is that time of the year, again?… it’s just me or times seems to fly by so fast! My favorite holiday season is back, as well the tradition: my Christmas blog post. If I told in the past that “it was a year of radical changes in my life”, I was lying! Nothing will compare to this last 5 months of the year and with the upcoming year because family is growing this time with a baby boy and I’m currently moving to a brand new a bigger house… exciting times! You may notice that the number of blog posts published in my blog has been decreasing but I promise that this behavior will change when I’m definitely living in my new home (at least until the child is born hehe).
Is time to look the past and plan the future, forget the worst that happens, look into the future and embracing it with hope and full of goals and new challenges. Time to remember your dreams that are lying dormant in a box and, at least try to concretize them, even that you fail! Better try and fail than never having the courage to try. For me, family and friendship are the best we have and I intend to have them around and enjoy their company.
To all my readers, friends, coworkers, to all Microsoft Integration Community (BizTalk Server, Logic Apps, API Management, Service Bus and so on) and Visio Community, MSFT Product Groups, all the Portuguese Communities, my MVP “family” and of course to my family, my sincere wishes for a Merry Christmas and a Happy New Year!
Thanks in advance for all the support and encouragement given throughout this year and hope that the next will be a year filled with new articles, I promise that I will continue to share knowledge hoping that they can help someone.

And in my native language (Portuguese):
HO HO HO, é sim… é aquela época do ano no qual podemos nos tornar crianças de novo! E como já se tornou habitual nesta época do ano, é como uma espécie de tradição agora… A todos os meus leitores, amigos, família e para todas as comunidades, os meus sinceros votos de um Bom Natal, um Feliz Ano Novo e um 2018 cheio de bons negócios, muita saúde, felicidade e claro muitas integrações.
É hora de olhar para o passado e planear o futuro. Esquecer o pior que acontecer, olhar para o futuro e abraçá-lo com esperança e cheio de novos desafios e novos objectivos. Tempo para recordar seus sonhos que estão adormecidos numa caixa qualquer e, pelo menos, tentam concretizá-los, mesmo que falhe! Pois é sempre melhor tentar e falhar do que nunca ter a coragem de tentar. Para mim, a família e as amizades são o melhor que temos e pretendo tê-los ao redor e desfrutar da sua companhia.
Desde já obrigado por todo o apoio e incentivo dado ao longo deste ano e que o próximo seja um ano recheado de novos artigos, da minha parte fica a promessa que irei continuar a partilhar conhecimento na esperança de poder sempre ajudar alguém.
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc.
He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community.
View all posts by Sandro Pereira
by Sandro Pereira | Dec 18, 2017 | BizTalk Community Blogs via Syndication
In the sequence of one of my last blog posts, I notice that in the same project also while trying to open a BizTalk pipeline inside Visual Studio, again, normally a simple and easy double-click operation to open this time the BizTalk Pipeline Editor, the resource didn’t open with the correct editor: BizTalk Pipeline Editor, instead, it opened with the XML (Text) Editor

I’m used to seeing this behavior ins orchestration but it is the first time, that I can remember, to see the same happening with pipelines. Again, this has a quick workaround but it becomes annoying after a few times.
Cause
Well, again and similar to the orchestrations, I don’t know exactly what can cause this problem but I suspect that this behavior happens more often when we migrate projects, or when we try to open previous BizTalk Server versions projects in recent versions of Visual Studio, special if we skip one or more versions, for example: from BizTalk Server 2010 to 2013 R2.
And may happen because of different configurations inside the structure of the “<BizTalk>.btproj” file.
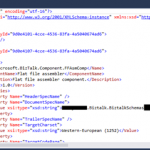
The cause of this strange behavior is without a doubt related to a mismatched setting inside the structure of the “<BizTalk>.btproj” file in the Pipeline nodes (each pipeline inside your project will reflect one Pipeline node specifying the name of the file, type name, and namespace. Normally it has this aspect in recent versions of BizTalk Server:
<ItemGroup>
<Pipeline Include="SendOrReceivePipelineName.btp">
<Namespace>MyProjectName.Pipelines</Namespace>
<TypeName>SendOrReceivePipelineName</TypeName>
</Pipeline>
</ItemGroup>
But sometimes we will find an additional element:
<ItemGroup>
<Pipeline Include="SendOrReceivePipelineName.btp">
<Namespace>MyProjectName.Pipelines</Namespace>
<TypeName>SendOrReceivePipelineName</TypeName>
<SubType>Designer</SubType>
</Pipeline>
</ItemGroup>
When the SubType element is present, this strange behavior of automatically open the pipeline with the XML (Text) Editor.
Solution
First, once again let’s describe the easy workaround for this annoying problem/behavior:
- On the solution explorer, right-click on the pipeline name and then select “Open With…” option

- On the “Open with …” window, select “BizTalk Pipeline Editor” option and click “OK”.

Once again, this will force Visual Studio to actually open the pipeline with the Pipeline Editor. But again, this will be a simple workaround because next time you try to open the pipeline inside Visual Studio it will open again with the XML (Text) Editor.
Similar to the orchestration behavior, force to “Set as Default” inside the “Open with …” window:
- Select “BizTalk Pipeline Editor” option, click “Set as Default”
- And then click “OK”.
It will not solve the problem, once again, if you notice in the picture above it is actually already configured as the default viewer.
So, to actually solve once and for all this annoying behavior, once again you need to adjust the configurations inside the btproj file, by:
- Open the “<BizTalk>.btproj” (or project) file(s) that contain the pipeline(s) with this behavior with Notepad, Notepad++ or other text editors of your preference.
- Remove the <SubType>Designer</SubType> line
- Save the file and reload the project inside Visual Studio
If you then try to open the pipeline it will now open with the BizTalk Pipeline Editor.
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc.
He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community.
View all posts by Sandro Pereira
by Gautam | Dec 17, 2017 | BizTalk Community Blogs via Syndication
Do you feel difficult to keep up to date on all the frequent updates and announcements in the Microsoft Integration platform?
Integration weekly update can be your solution. It’s a weekly update on the topics related to Integration – enterprise integration, robust & scalable messaging capabilities and Citizen Integration capabilities empowered by Microsoft platform to deliver value to the business.
If you want to receive these updates weekly, then don’t forget to Subscribe!
Feedback
Hope this would be helpful. Please feel free to provide your feedback on the Integration weekly series.
by Jeroen | Dec 16, 2017 | BizTalk Community Blogs via Syndication
IBM Websphere MQ can be an overwhelming product to use as a message broker if you have worked in the past with Microsft’s MSMQ or the Azure Service Bus. The best way to learn and understand a product is to have your local lab environment, that you can recreate when needed.
With this post I share with you some links how you can setup your own local IBM MQ 9 installation for development purposes.
Step 1: Download IBM MQ Advanced for Developers
Direct link: IBM MQ 9.0.3 for Windows
Step 2: Setting up a development WebSphere MQ server
This very well written blog posts explain how you can setup a queue manager, configure a channel and create a queue.
(Skip step 10 as it isn’t the best way to disable security)
Step 3: Disable MQ Security
The default installation of IBM MQ has security turned on. Without disabling this you won’t be able to use your .NET client application or the BizTalk Adapter to send/receive messages. Be aware that you should only do this on your development environment!
Step 4: Add a firewall exclusion rule
If you are planning to host your local IBM MQ setup in a seperate VM, you will most likely need to setup a firewall exlusion rule so you can access the queue manager from another machine. (If you install IBM MQ as a service it will listen by default on all IP addresses)
Simply add an exclusion rule to allow inbound TCP traffic for the port your queue manager is running on (default is 1414).
Optional: .NET Sample Applications
by Jeroen | Dec 11, 2017 | BizTalk Community Blogs via Syndication
During a smoke test of a new BizTalk Server 2016 (with HIS 2016 and the IBM MQ 8.0.0.8 client) we stubled upon the following exception:
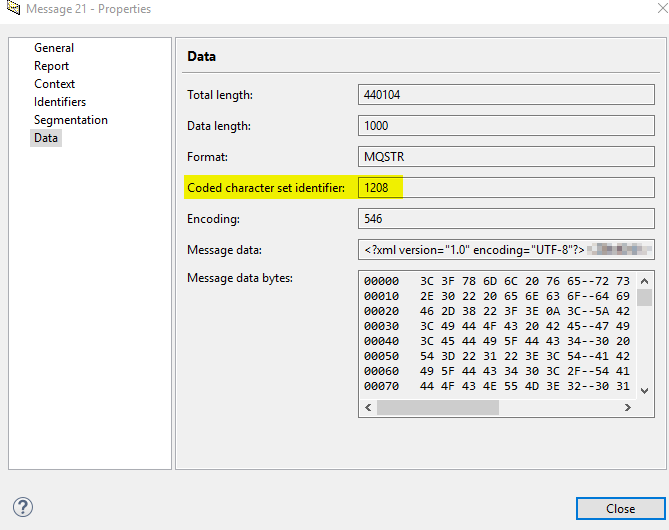
“The program ended because, either the source CCSID ‘1208’ or the target CCSID ‘437’ is not valid, or is not currently supported.”
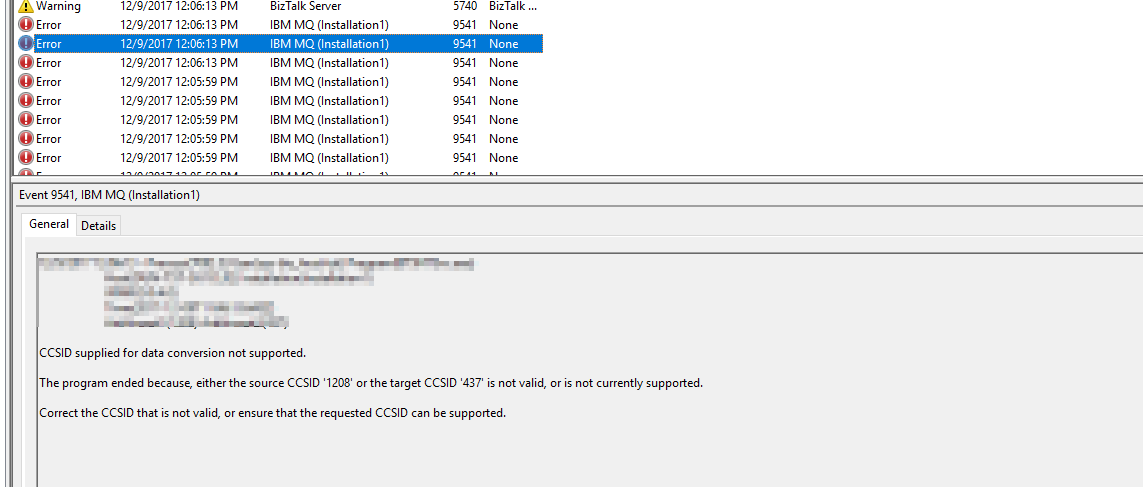
In this simple test we were sending and receiving messages to/from a queue with a couple of ports, and dit not yet use a pipeline component to set IBM MQ Series Context Properties.
But wait, we needed a way to set the CCSID to 1208!
Luckily, you can set an Environmet Variable to specify the desired CCSID globally:
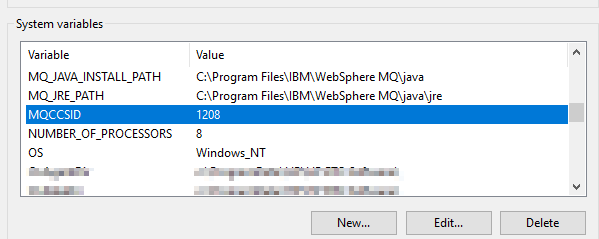
MQCCSID: Specifies the coded character set number to be used and overrides the native CCSID of the application. (IBM Knowledge Center)
After applying this, the messages were sent using the correct CCSID:
by Gautam | Dec 10, 2017 | BizTalk Community Blogs via Syndication
Do you feel difficult to keep up to date on all the frequent updates and announcements in the Microsoft Integration platform?
Integration weekly update can be your solution. It’s a weekly update on the topics related to Integration – enterprise integration, robust & scalable messaging capabilities and Citizen Integration capabilities empowered by Microsoft platform to deliver value to the business.
If you want to receive these updates weekly, then don’t forget to Subscribe!
Feedback
Hope this would be helpful. Please feel free to let me know your feedback on the Integration weekly series.





