
by Sandro Pereira | Sep 29, 2017 | BizTalk Community Blogs via Syndication
This is probably the quickest and smallest update that I made in my Microsoft Integration (Azure and much more) Stencils Pack: only 1 new stencil and I only do it for its importance, since it is definitely one of Microsoft’s fastest growing business these days, and the Ignite context: the new Azure logo.
 Stencils Pack: new Azure Logo")
This will be probably the first Visio pack containing this shape.
The Microsoft Integration (Azure and much more) Stencils Pack v2.6.1 is composed by 13 files:
- Microsoft Integration Stencils v2.6.1
- MIS Apps and Systems Logo Stencils v2.6.1
- MIS Azure Portal, Services and VSTS Stencils v2.6.1
- MIS Azure SDK and Tools Stencils v2.6.1
- MIS Azure Services Stencils v2.6.1
- MIS Deprecated Stencils v2.6.1
- MIS Developer v2.6.1
- MIS Devices Stencils v2.6.1
- MIS IoT Devices Stencils v2.6.1
- MIS Power BI v2.6.1
- MIS Servers and Hardware Stencils v2.6.1
- MIS Support Stencils v2.6.1
- MIS Users and Roles Stencils v2.6.1
That will help you visually represent Integration architectures (On-premise, Cloud or Hybrid scenarios) and Cloud solutions diagrams in Visio 2016/2013. It will provide symbols/icons to visually represent features, systems, processes and architectures that use BizTalk Server, API Management, Logic Apps, Microsoft Azure and related technologies.
- BizTalk Server
- Microsoft Azure
- · Azure App Service (API Apps, Web Apps, Mobile Apps and Logic Apps)
- API Management
- Event Hubs
- Service Bus
- Azure IoT and Docker
- SQL Server, DocumentDB, CosmosDB, MySQL, …
- Machine Learning, Stream Analytics, Data Factory, Data Pipelines
- and so on
- Microsoft Flow
- PowerApps
- Power BI
- Office365, SharePoint
- DevOpps: PowerShell, Containers
- And many more…
You can download Microsoft Integration (Azure and much more) Stencils Pack from:
 Microsoft Integration Stencils Pack for Visio 2016/2013 (11,4 MB)
Microsoft Integration Stencils Pack for Visio 2016/2013 (11,4 MB)
Microsoft | TechNet Galler
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc. He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community. View all posts by Sandro Pereira
by Praveena Jayanarayanan | Sep 27, 2017 | BizTalk Community Blogs via Syndication
Biztalk360 comes with a lot of exciting features in every release. One of the important functionalities in BizTalk360 is the monitoring with the autocorrect options. BizTalk360 is the one-stop monitoring solution for BizTalk server. We can not only monitor the artefacts, but also the SQL jobs. Yes, the SQL jobs present in the SQL server can also be monitored. We can also set the autocorrect (enable/disable) functionality for the SQL jobs.
There may be separate servers for BizTalk databases and BizTalk360 database or even single server hosting all the databases. The jobs in all these servers can be monitored via BizTalk360. But then, can all the users have access to monitor and autocorrect the SQL jobs? In this blog, I am going to explain about the permissions required by the users for monitoring SQL jobs and setting autocorrect functionality which we learnt from one of the support tickets.
Customer’s case:
Our support team often get some interesting tickets which do not directly deal with the functionality and features of BizTalk360. Some tickets may be related to performance, access permissions, AD users etc. Each ticket experience is a new learning for our support engineers. Let’s see one such case of a customer related to the access permission for the databases in the SQL server.
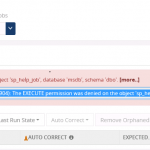
The customer got the below exception when they tried to set up monitoring for SQL jobs.
The sp_help_job is the stored procedure used to list the SQL jobs running in the server. This job returns information about jobs that are used by SQL Server Agent to perform automated activities in SQL Server. There are SQL jobs that get installed and scheduled automatically to maintain the health of the BizTalk environment.
BizTalk360 allows to set the threshold for SQL jobs (Monitoring -> Manage Mapping ->SQL Server Instances ->SQL Jobs) to list out those SQL jobs and perform the automatic operation this “sp_help_job” job is being used.
The exception in the above screenshot comes because of a missing permission for the BizTalk360 service account while accessing the SQL server. We have our support article in place which describes about the permissions for the SQL jobs. The customer has given the permission according to this article. But they were facing the error again when trying to enable autocorrect feature for SQL jobs.

In this error message, it says “Only members of sysadmin role are allowed to update or delete jobs owned by a different login”
This means that only if the service account has the SYSADMIN permission, then it can enable/disable the sql jobs from BizTalk360. But some of the customers would not prefer to provide SYSADMIN permission for the service account due to some security policies. So, what happens in such case? Let’s go ahead and check the resolution given. Before that lets have a quick glance at SQl jobs and permissions.
The SQL jobs:
A job is a series of operations performed by SQL Server Agent sequentially. A job can run on one local server or on multiple remote servers. The jobs are used to define administrative tasks that can be run one or more times and monitored for success or failure. SQL server agent runs these scheduled jobs. A job can be edited only by its owner or by the members of the sysadmin role.
The SQL job permissions:
SQL server has the following msdb database fixed roles through which the SQL server can be accessed and controlled. The roles from least to most privileged are:
- SQLAgentUserRole
- SQLAgentReaderRole
- SQLAgentOperatorRole
Can we have a brief look at each one of them?
SQLAgentUserRole:
This is the least privileged role. It has permissions on only operators, local jobs, and job schedules. Members of SQLAgentUserRole have permissions on only local jobs and job schedules that they own. They cannot use multi-server jobs (master and target server jobs), and they cannot change job ownership to gain access to jobs that they do not already own.
SQLAgentReaderRole:
This role includes all the SQLAgentUserRole permissions as well as permissions to view the list of available multi-server jobs, their properties, and their history. Members of this role can also view the list of all available jobs and job schedules and their properties, not just those jobs and job schedules that they own. SQLAgentReaderRole members cannot change job ownership to gain access to jobs that they do not already own.
SQLAgentOperatorRole:
This is the most privileged role which includes all the permissions of the above-mentioned roles. They have additional permissions on local jobs and schedules. They can execute, stop, or start all local jobs, and they can delete the job history for any local job on the server. They can also enable or disable all local jobs and schedules on the server. SQLAgentOperatorRole members cannot change job ownership to gain access to jobs that they do not already own.
The below table summarizes some of the properties for all these roles.
| Database Role |
Action – Create/modify/delete
Action – Enable/Disable
|
|
Local Jobs |
Multiserver jobs |
Job schedules |
| SQLAgentUserRole |
Yes
Yes
(Owned jobs)
|
No
No
|
Yes
Yes
(Owned schedules)
|
| SQLAgentReaderRole |
Yes
Yes
(Owned jobs)
|
No
No
|
Yes
Yes
(Owned schedules)
|
| SQLAgentOperatorRole |
Yes
Yes
|
No
No
|
Yes (Owned schedules)
Yes
|
Of all the above-mentioned SQL database roles, the SYSADMIN is the highest privileged role which has the administrator rights on the SQL server.
The resolution provided:
As mentioned earlier, the BizTalk360 service account would require the SYSADMIN permission to monitor and autocorrect the SQL jobs. But in some customer scenarios, they would not prefer to provide the SYSADMIN permissions. In that case, we need to see what is the minimum level of permission that we can provide to the service account for monitoring the SQL jobs.
Our support team did an extensive testing to check for various scenarios and permissions for the service account. The outcome of the testing is given below:
As the table summarizes, when the BizTalk360 service account is given the permissions as SQLAgentUserRole or SQLAgentReaderRole, it can only view the SQL jobs and cannot perform any operations on them. But when the SQLAgentOperatorRole is given for the service account, the auto correct functionality will work for the SQL jobs. The SYSADMIN permission is not required for this. This role is the highest privileged role next to the SYSADMIN.
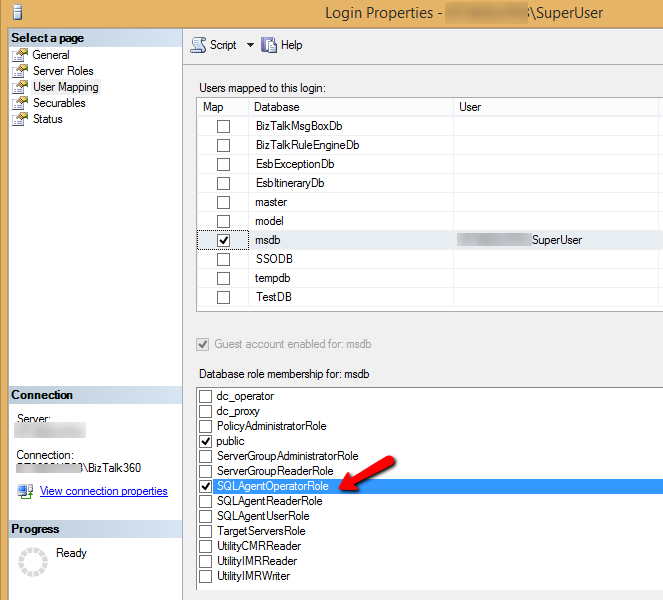
Conclusion:
Hence, for setting the autocorrect functionality (enable/disable) the SQL jobs, the BizTalk360 service account needs to be given the SQLAgentOperatorRole permission to the system database, if SYSADMIN permission is not preferred to be given.
PS: BizTalk360 will not do any operation by itself until monitoring has configured for any of the available SQL Jobs and enable the Auto-correction ability. In case, you don’t wish to monitor the SQL jobs you can avoid the permissions shown in the above image.
If you have any questions, contact us at support@biztalk360.com. Also, feel free to leave your feedback in our forum.
Author: Praveena Jayanarayanan
I am working as Senior Support Engineer at BizTalk360. I always believe in team work leading to success because “We all cannot do everything or solve every issue. ‘It’s impossible’. However, if we each simply do our part, make our own contribution, regardless of how small we may think it is…. together it adds up and great things get accomplished.” View all posts by Praveena Jayanarayanan
by Sriram Hariharan | Sep 27, 2017 | BizTalk Community Blogs via Syndication
This episode of Azure Logic Apps Monthly Update comes to us directly from #MSIgnite. It is one of those episodes with a special guest and this episode featured Sarah Fender from the Azure Security Center team. The Pro Integration team are at #MSIgnite that’s happening between September 25-29, 2017 at Orlando, FL. I’ll try to give you a very crisp recap of the proceedings during the event and the important announcements from the #MSIgnite event.
Azure Security Center
Sarah started off talking about the Azure Security Center feature. Security Center provides unified security management and threat protection for Azure workloads, workloads running on-premises and on other cloud platforms. It basically assesses the security of the cloud and on-premise workloads and offers out of the box insights. In addition, Security Center offers some built in security controls such as Just in Time VM access that will help to lock down access to virtual machines, and Adaptive Access Controls that help to lock down on machines to prevent any malware execution. Security Center also monitors the hybrid cloud using advanced concepts like Machine Learning and provides rich graphical data to administrators.
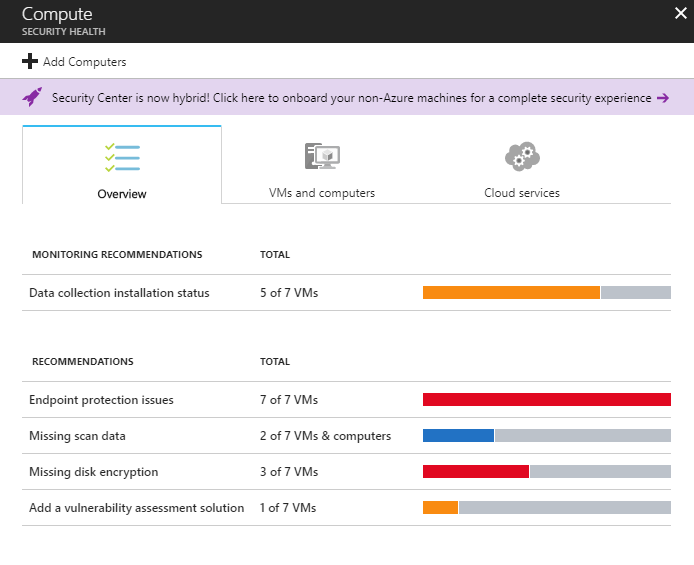
Security Center keeps a look into all the different incidents in the environment such as SQL Injection, security incidents, suspicious processes and so on and provides insights which will be very helpful for IT teams to keep a track of the issues in the environment.
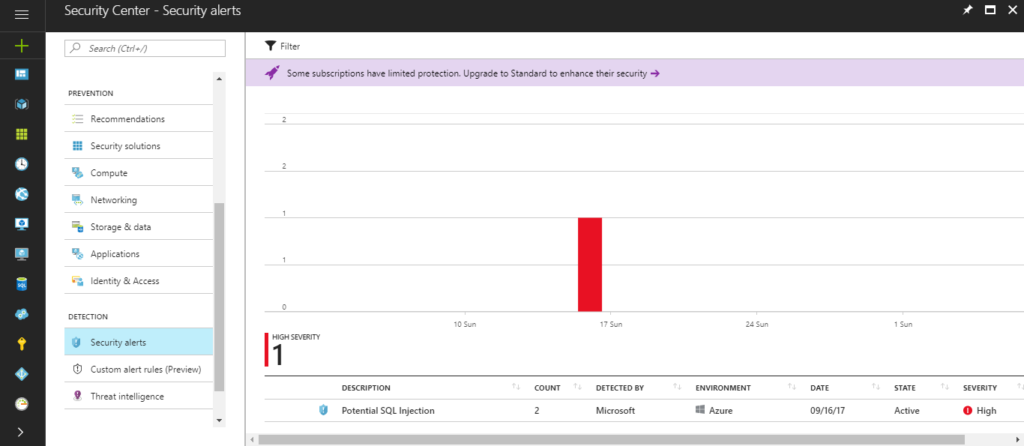
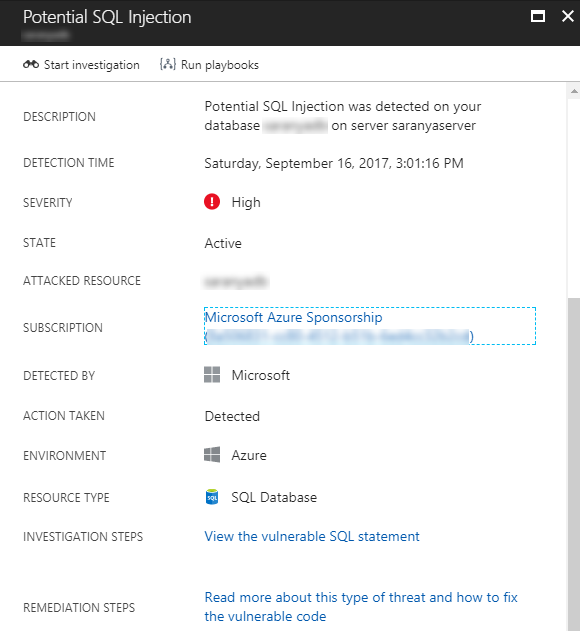
At #MSIgnite, the Azure Security Center team introduced the new experience of Investigation Dashboard. With this feature, organizations can easily respond to the incident and understand the intricate details about the security incident. The investigation path defines the attack path and the graphical view displays the detailed information such as severity of the attack, attack detected by information and so on. The investigation dashboard also lists the entities and now supports the Playbooks that are nothing but Logic Apps being triggered from Security Center when a certain alert is fired.
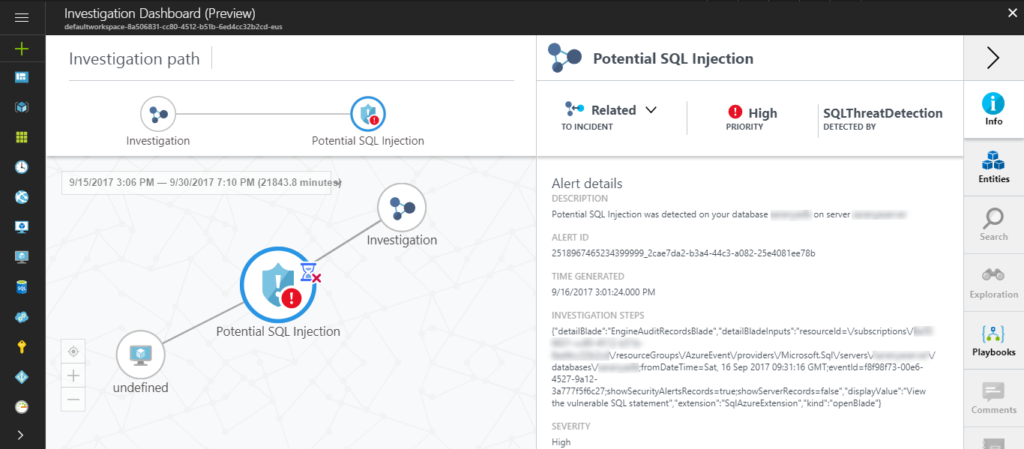
You can run a Playbook from the Security Center through the integration with Azure Logic Apps. Users can pre-define a Logic App that will actually take a corrective action when there is an attack you can allow the investigation dashboard to automatically execute that particular Logic App (through Playbook) to execute the corrective action. For e.g., when a vulnerability attack is detected with a very high severity, post a message on the slack channel for the users to get notified.
After all these updates from Sarah, it was time for the Logic Apps trio comprising of Jeff Hollan, Kevin Lam and Jon Fancey to provide the latest updates on Logic Apps. Kevin Lam started off by giving the latest updates-
What’s New in Azure Logic Apps?
- Custom Connectors – Enables the option to extend your endpoints and register them as connectors in Logic Apps.
- Large Message Support – This functionality is now available in the designer. Using this functionality, you can move large files up to 1 GB (between) for specific connectors (blob, FTP).
- Variables append to array – append capability to aggregate data within loops in the designer. Kevin Lam gave a pro tip here for all users –
Remember to turn on sequential for for-each to achieve this scenario.
- Nested foreach and do-until – is now available in the designer.
- Enable high throughput scenarios – You can configure the number of scale units within the code view to enable the high throughput scenarios. Say, you can take one Logic App definition that runs in a scale unit and span it across 16/32/64 scale units to get increased throughput. This is called ludicrous mode (as Kevin had it on the PPT).
- Maximum retries count (Custom Retry Policy) has been increased from 4 to 10.
- Now you can export (Publish) Logic Apps to PowerApps and Flow
- Emit correlation tracking id from the trigger to OMS – This gives full traceability across the process that’s happening across the Logic App.
- Expression intellisense – This is now available in the designer. When you are typing an expression, you will see the same intelligent view that you see when you are typing in Visual studio.
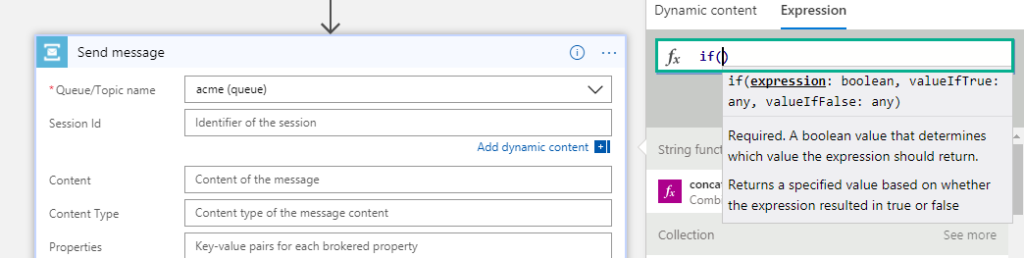
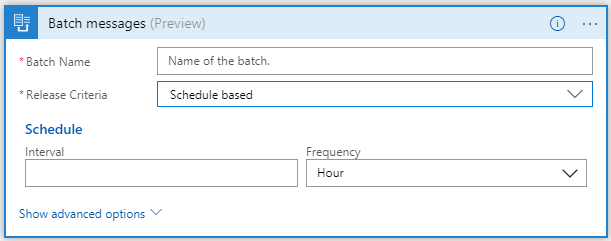
- Schedule based batching – In addition to batching based on message count, you can batch messages based on the schedule.
New Connectors
- Azure Security Center Trigger
- Log Analytics Data Collector – add information to Log Analytics from Log Analytics
- ServiceNow – create tickets, read & write into ServiceNow
- DateTime Actions
- Azure Event Grid Publish
- Adobe Sign – This was a big announcement from Microsoft at #MSIgnite – collaboration with Adobe
- O365 Groups
- Skype for Business
- LinkedIn
- Apache Impala
- FlowForma
- Bizzy
What’s in Progress?
- Concurrency Control (code-view live) – Say, your Logic App is executing in a faster way than you want it to actually work. In this case, you can make Logic Apps to slow down (restrict the number of Logic Apps running in parallel). This is possible today in the code-view where you can define say, only 10 Logic Apps can execute at a particular time in parallel. Therefore, when 10 Logic Apps are executing in parallel, the Logic Apps logic will stop polling until one of the 10 Logic Apps finish execution and then start polling for data.
- SOAP – Native SOAP support to consume cloud and on-premise SOAP services. This is one of the most requested features on UserVoice.
- Expression Tracing – You can actually get to see the intermediate values for complex expressions
- Foreach failure navigation – If there are lots of iterations in the foreach loop and few of them failed; instead of having to look for which one actually failed, you can navigate to the next failed action inside a for each loop easily to see what happened.
- Functions + Swagger – You can automatically render the Azure functions annotated with Swagger. This functionality will be going live by end of August.
- HTTP OAuth with Certificates
- Complex Conditions within the designer
- Bulk resubmit in OMS
- Batch configuration in Integration Account
- Connectors
- Workday
- Marketo
- Compute
- Containers
Watch the recording of this session here
[embedded content]
Community Events Logic Apps team are a part of
- INTEGRATE 2017 USA – October 25 – 27, 2017 at Redmond. Register for the event today. Scott Guthrie, Executive Vice President at Microsoft will be delivering the keynote speech. You can also avail Day Passes for the event (available for Wednesday and Thursday).
- ServerlessConf – 2 days of sessions on Serverless with Hackathon during October 2017
- Workday Rising – October 9 – 12 at Chicago
- CONNECT 2017 on October 9, 2017 at DeFabrique, Utrecht
Feedback
If you are working on Logic Apps and have something interesting, feel free to share them with the Azure Logic Apps team via email or you can tweet to them at @logicappsio. You can also vote for features that you feel are important and that you’d like to see in logic apps here.
The Logic Apps team are currently running a survey to know how the product/features are useful for you as a user. The team would like to understand your experiences with the product. You can take the survey here.
If you ever wanted to get in touch with the Azure Logic Apps team, here’s how you do it!
Previous Updates
In case you missed the earlier updates from the Logic Apps team, take a look at our recap blogs here –
Author: Sriram Hariharan
Sriram Hariharan is the Senior Technical and Content Writer at BizTalk360. He has over 9 years of experience working as documentation specialist for different products and domains. Writing is his passion and he believes in the following quote – “As wings are for an aircraft, a technical document is for a product — be it a product document, user guide, or release notes”. View all posts by Sriram Hariharan

by Steef-Jan Wiggers | Sep 27, 2017 | BizTalk Community Blogs via Syndication
September 2017, the last month at Macaw and about to onboard on a new journey at Codit Company. And I looking forward to it. It will mean more travelling, speaking engagements and other cool things. #Cyanblue is the new blue.
Below a picture of Tomasso, Eldert, me, Dominic (NoBuG), and Kristian in Olso (top floor or Communicate office).

I did a talk about Event Grid at NoBug wearing my Codit shirt for the first time.
Month September
September was a month filled with new challenges. I onboarded the Middleware Friday team and released two episodes (31 and 33):
Moreover, I really enjoyed doing these type of videos and looking forward to create a few more as I will be presenting an episide every alternating week. Subsequently, Kent will continu with episodes focussed around Microsoft Cloud offerings such as Microsoft Flow. And my focus will be integration in general.
In September I did a few blog posts on my own blog and BizTalk360 blog:
This month I only read one book. Yet it was a good book called: The Subtle Art of Not Giving a F*ck from Mark Manson.

Music
My favorite albums in September were:
- Chelsea Wolfe – Hiss Spun
- Satyricon – Deep Calleth Upon Deep
- Cradle Of Filth – Cryptoriana: The Seductiveness Of Decay
- Enter Shikari – The Spark
- Myrkur – Mareridt
- Arch Enemy – Will To Power
- Wolves In The Throne Room – Thrice Woven

Running
In September I continued with training and preparing for next months half marathons in London and Amsterdam.
October will be filled with speaking engagements ranging from Integration Monday to Integrate US 2017 in Redmond.
Cheers,
Steef-Jan
Author: Steef-Jan Wiggers
Steef-Jan Wiggers is all in on Microsoft Azure, Integration, and Data Science. He has over 15 years’ experience in a wide variety of scenarios such as custom .NET solution development, overseeing large enterprise integrations, building web services, managing projects, designing web services, experimenting with data, SQL Server database administration, and consulting. Steef-Jan loves challenges in the Microsoft playing field combining it with his domain knowledge in energy, utility, banking, insurance, health care, agriculture, (local) government, bio-sciences, retail, travel and logistics. He is very active in the community as a blogger, TechNet Wiki author, book author, and global public speaker. For these efforts, Microsoft has recognized him a Microsoft MVP for the past 7 years. View all posts by Steef-Jan Wiggers
by Steef-Jan Wiggers | Sep 25, 2017 | BizTalk Community Blogs via Syndication
A couple of weeks ago Azure Event Grid service became available in public preview. This service enables centralized management of events in a uniform way. Moreover, it scales with you when the number of events increases. This is made possible by the foundation the Event Grid relies on Service Fabric. Not only does it auto scale you also do not have to provision anything besides an Event Topic to support custom events (see the blog post Routing an Event with a custom Event Topic).
Event Grid is serverless, therefore you only pay for each action (Ingress events, Advanced matches, Delivery attempts, Management calls). Moreover, the price will be 30 cents per million actions in the preview and will be 60 cents once the service will be GA.
Azure Event Grid can be described as an event broker that has one of more event publishers and subscribers. Furthermore, Event publishers are currently Azure blob storage, resource groups, subscriptions, event hubs and custom events. Finally, more will be available in the coming months like IoT Hub, Service Bus, and Azure Active Directory. Subsequently, there are consumers of events (subscribers) like Azure Functions, Logic Apps, and WebHooks. And on the subscriber side too more will be available with Azure Data Factory, Service Bus and Storage Queues for instance.
To view Microsoft’s Roadmap for Event Grid please watch the Webinar of the 24th of August on YouTube.
Event Grid Preview for Azure Storage
Currently, to capture Azure Blob Storage events you will need to register your subscription through a preview program. Once you have registered your subscription, which could take a day or two, you can leverage Event Grid in Azure Blob Storage only in Central West US!

The Microsoft documentation on Event Grid has a section “Reacting to Blob storage events”, which contains a walk-through to try out the Azure Blob Storage as an event publisher.
Scenario
Having registered the subscription to the preview program, we can start exploring its capabilities. Since the landing page of Event Grid provides us some sample scenarios, let’s try out the serverless architecture sample, where one can use Event Grid to instantly trigger a Serverless function to run image analysis each time a new photo is added to a blob storage container. Hence, we will build a demo according to the diagram below that resembles that sample.
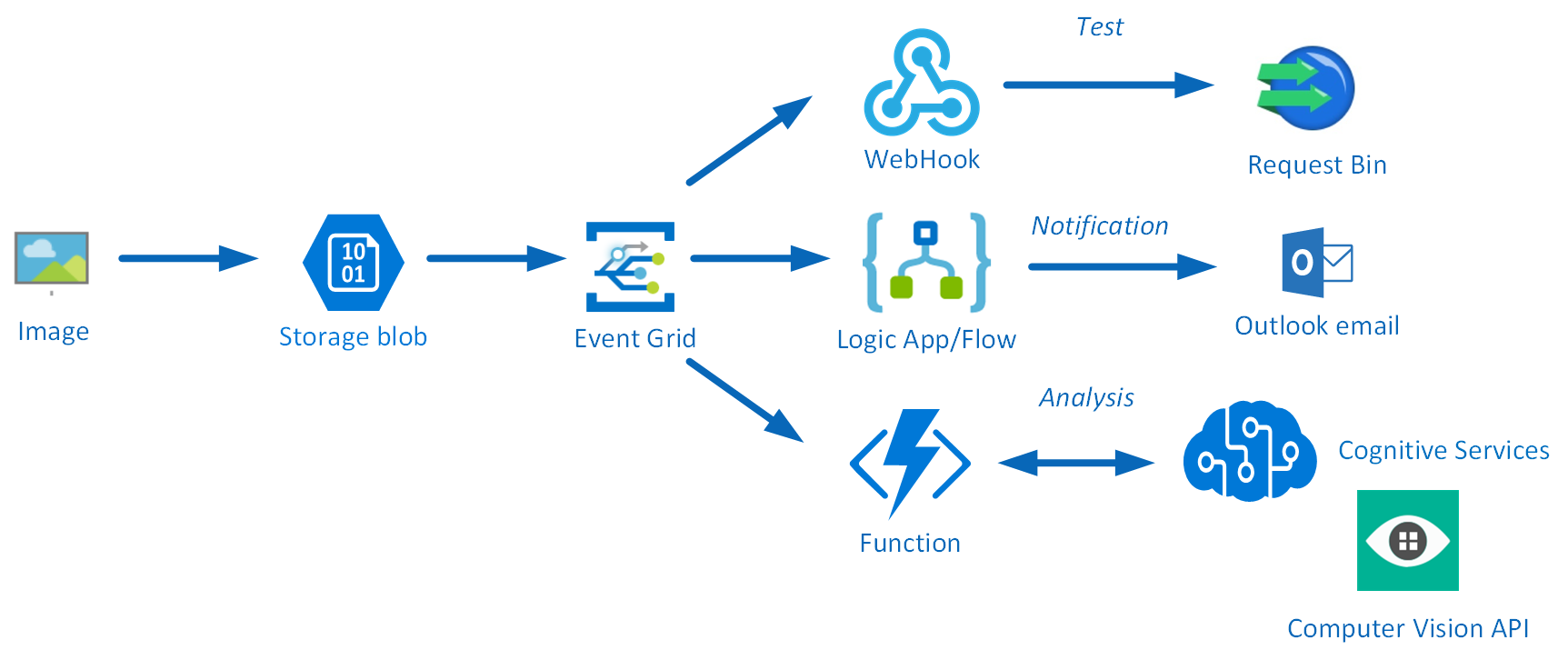
An image will be uploaded to a Storage blob container, which will be the event source (publisher). Subsequently, the Storage blob container belongs to a Storage Account containing the Event Grid capability. And finally, the Event Grid has three subscribers, a WebHook (Request Bin) to capture the output of the event, a Logic App to notify me a blob has been created and an Azure Function that will analyze the image created in the blob storage, by extracting the URL from the event message and use it to analyze the actual image.
Intelligent routing
The screenshot below depicts the subscriptions on the events on the Blob Storage account. The WebHook will subscribe to each event, while the Logic App and Azure Function are only interested in the BlobCreated event, in a particular container(prefix filter) and type (suffix filter).

Besides being centrally managed Event Grid offers intelligent routing, which is the core feature of Event Grid. You can use filters for event type, or subject pattern (pre- and suffix). Moreover, the filters are intended for the subscribers to indicate what type of event and/or subject they are interested in. When we look at our scenario the event subscription for Azure Functions is as follows.
- Event Type : Blob Created
- Prefix : /blobServices/default/containers/testcontainer/
- Suffix : .jpg
The prefix, a filter object, looks for the beginsWith in the subject field in the event. And in addition the suffix looks for the subjectEndsWith in again the subject. Consequently, in the event above, you will see that the subject has the specified Prefix and Suffix. See also Event Grid subscription schema in the documentation as it will explain the properties of the subscription schema. The subscription schema of the function is as follows:
<pre>{
"properties": {
"destination": {
"endpointType": "webhook",
"properties": {
"endpointUrl": "https://imageanalysisfunctions.azurewebsites.net/api/AnalyseImage?code=Nf301gnvyHy4J44JAKssv23578D5D492f7KbRCaAhcEKkWw/vEM/9Q=="
}
},
"filter": {
"includedEventTypes": [ "<strong>blobCreated</strong>"],
"subjectBeginsWith": "<strong>/blobServices/default/containers/testcontainer/</strong>",
"subjectEndsWith": "<strong>.jpg</strong>",
"subjectIsCaseSensitive": "true"
}
}
}</pre>
Azure Function Event Handler
The Azure Function is only interested in a Blob Created event with a particular subject and content type (image .jpg). This will be apparent once you inspect the incoming event to the function.
<pre>[{
"topic": "/subscriptions/0bf166ac-9aa8-4597-bb2a-a845afe01415/resourceGroups/rgtest/providers/Microsoft.Storage/storageAccounts/teststorage666",
"<strong>subject</strong>": "<strong>/blobServices/default/containers/testcontainer/</strong>blobs/NinoCrudele.<strong>jpg</strong>",
"<strong>eventType</strong>": "<strong>Microsoft.Storage.BlobCreated</strong>",
"eventTime": "2017-09-01T13:40:33.1306645Z",
"id": "ff28299b-001e-0045-7227-23b99106c4ae",
"data": {
"api": "PutBlob",
"clientRequestId": "206999d0-8f1b-11e7-a160-45670ee5a425",
"requestId": "ff28299b-001e-0045-7227-23b991000000",
"eTag": "0x8D4F13F04C48E95",
"contentType": "image/jpeg",
"contentLength": 32905,
"blobType": "<strong>BlockBlob</strong>",
"url": "https://teststorage666.blob.core.windows.net/testcontainer/NinoCrudele.jpg",
"sequencer": "0000000000000AB100000000000437A7",
"storageDiagnostics": {
"batchId": "f11739ce-c83d-425c-8a00-6bd76c403d03"
}
}
}]</pre>
The same intelligence applies for the Logic App that is interested in the same event. The WebHook subscribes to all the events and lacks any filters.
The scenario solution
The solution contains a storage account (blob), a registered subscription for Event Grid Azure Storage, a Request Bin (WebHook), a Logic App and a Function App containing an Azure function. The Logic App and Azure Function subscribe to the BlobCreated event with the filter settings.
The Logic App subscribes to the event once the trigger action is defined. The definition is shown in the picture below.
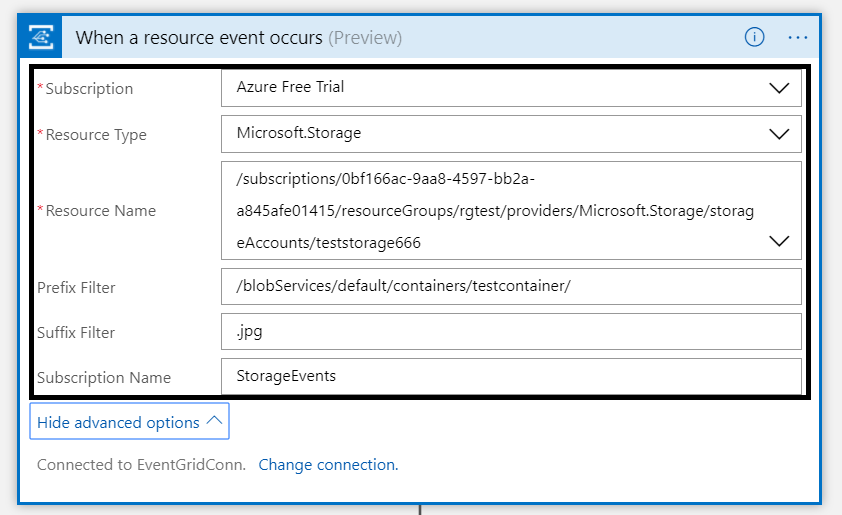
Note that the resource name has to be specified explicitly (custom value) as the resource type Microsoft.Storage has been set explicitly too. The resource types currently available are Resource Groups, Subscriptions, Event Grid Topics and Event Hub Namespaces, while Storage is still in a preview program. Therefore, registration as described earlier is required. As a result with the above configuration, the desired events can be evaluated and processed. In case of the Logic App, it is parsing the event and sending an email notification.
Image Analysis Function
The Azure Function is interested in the same event. And as soon as the event is pushed to Event Grid once a blob has been created, it will process the event. The URL in the event https://teststorage666.blob.core.windows.net/testcontainer/NinoCrudele.jpg will be used to analyse the image. The image is a picture of my good friend Nino Crudele.

This image will be streamed from the function to the Cognitive Services Computer Vision API. The result of the analysis can be seen in the monitor tab of the Azure Function.
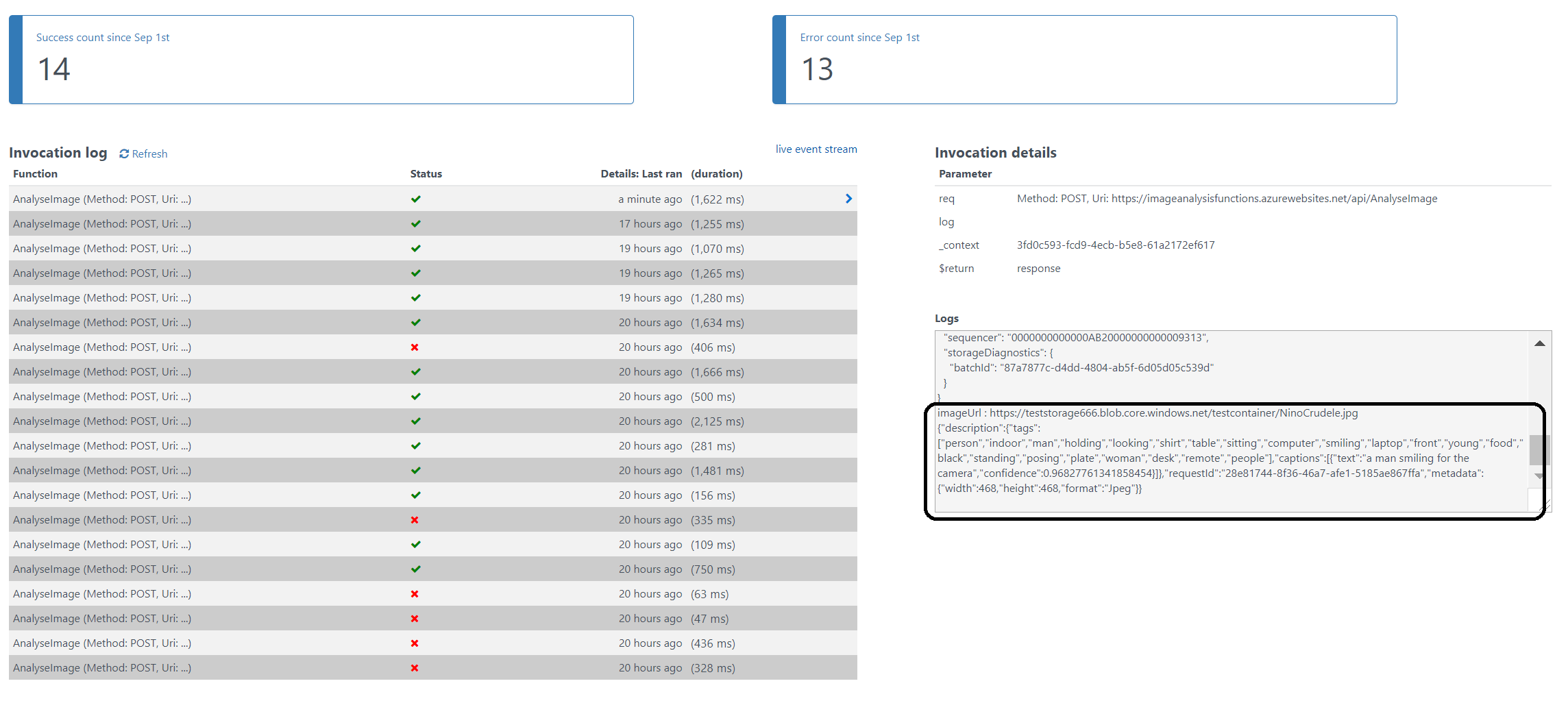
The result of the analysis with high confidence is that Nino is smiling for the camera. We, as humans, would say that this is obvious, however do take into consideration that a computer is making the analysis. Hence, the Computer Vision API is a form of Artificial Intelligence (AI).
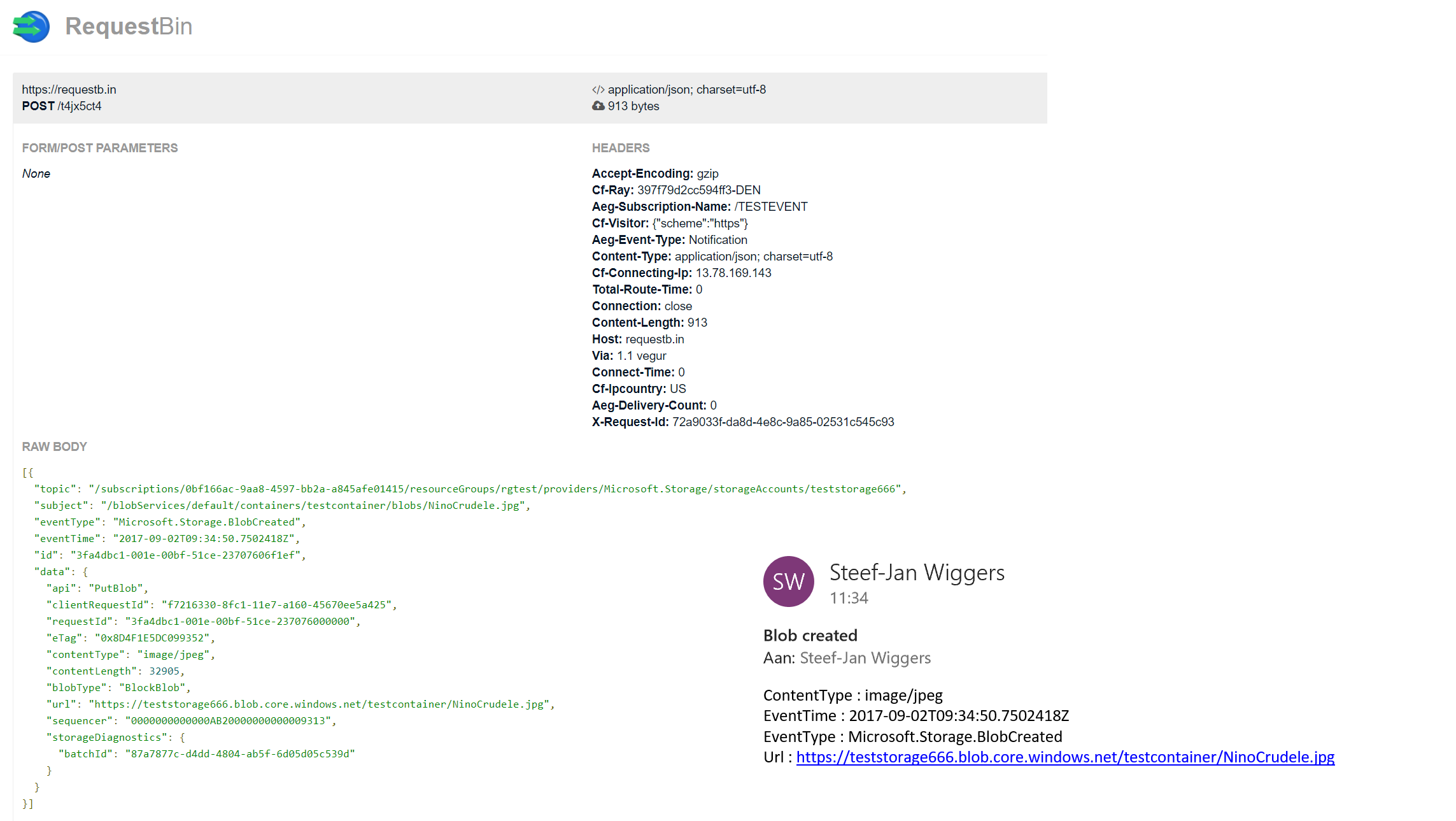
The Logic App in our scenario will parse the event and sent out an email. The Request Bin will show the raw event as is. And in case I, for instance, delete a blob, then this event will only be caught by the WebHook (Request Bin) as it is interested in any event on the Storage account.
Summary
Azure Event Grid is unique in its kind as now other Cloud vendor has this type of service that can handle events in a uniform and serverless way. Although it is still early days as this service is in preview a few weeks. However, with expansion of event publishers and subscribers, management capabilities and other features it will mature in the next couple of months.
The service is currently only available in, West Central US and West US. However, over the course of time it will become available in every region. And once it will become GA the price will increase.
Working with Storage Account as a source (publisher) of events unlocked new insights in the Event Grid mechanisms. Moreover, it shows the benefits of having one central service in Azure for events. And the pub-sub and push of events are the key differentiators towards the other two services Service Bus and Event Hubs. Therefore, no longer do you have to poll for events and/or develop a solution for it. To conclude the Service Bus Team has completed the picture for messaging and event handling.
Author: Steef-Jan Wiggers
Steef-Jan Wiggers has over 15 years’ experience as a technical lead developer, application architect and consultant, specializing in custom applications, enterprise application integration (BizTalk), Web services and Windows Azure. Steef-Jan is very active in the BizTalk community as a blogger, Wiki author/editor, forum moderator, writer and public speaker in the Netherlands and Europe. For these efforts, Microsoft has recognized him a Microsoft MVP for the past 5 years. View all posts by Steef-Jan Wiggers
by BizTalk Team | Sep 25, 2017 | BizTalk Community Blogs via Syndication
If you missed the chance to attend INTEGRATE 2017 in London this year, now is your chance to participate in INTEGRATE 2017 USA at the Microsoft Redmond Campus. Come see Scott Guthrie, Executive Vice President for the Cloud and Enterprise division, deliver the keynote address. Have a chance to network with Microsoft employees along with Microsoft Integration MVPs.
Further details and registration information can be found at https://www.biztalk360.com/integrate-2017-usa/
by BizTalk Team | Sep 25, 2017 | BizTalk Community Blogs via Syndication
If you missed the chance to attend INTEGRATE 2017 in London this year, now is your chance to participate in INTEGRATE 2017 USA at the Microsoft Redmond Campus. Come see Scott Guthrie, Executive Vice President for the Cloud and Enterprise division, deliver the keynote address. Have a chance to network with Microsoft employees along with Microsoft Integration MVPs.
Further details and registration information can be found at https://www.biztalk360.com/integrate-2017-usa/
by Gautam | Sep 24, 2017 | BizTalk Community Blogs via Syndication
Do you feel difficult to keep up to date on all the frequent updates and announcements in the Microsoft Integration platform?
Integration weekly update can be your solution. It’s a weekly update on the topics related to Integration – enterprise integration, robust & scalable messaging capabilities and Citizen Integration capabilities empowered by Microsoft platform to deliver value to the business.
If you want to receive these updates weekly, then don’t forget to Subscribe!
On-Premise Integration:
Cloud and Hybrid Integration:
Feedback
Hope this would be helpful. Please feel free to let me know your feedback on the Integration weekly series.
by Sandro Pereira | Sep 19, 2017 | BizTalk Community Blogs via Syndication
I decided to update my Microsoft Integration (Azure and much more) Stencils Pack with a set of 24 new shapes (maybe the smallest update I ever did to this package) mainly to add the Azure Event Grid shapes.
One of the main reasons for me to initially create the package was to have a nice set of Integration (Messaging) shapes that I could use in my diagrams, and during the time it scaled to a lot of other things.
With these new additions, this package now contains an astounding total of ~1311 shapes (symbols/icons) that will help you visually represent Integration architectures (On-premise, Cloud or Hybrid scenarios) and Cloud solutions diagrams in Visio 2016/2013. It will provide symbols/icons to visually represent features, systems, processes, and architectures that use BizTalk Server, API Management, Logic Apps, Microsoft Azure and related technologies.
- BizTalk Server
- Microsoft Azure
- Azure App Service (API Apps, Web Apps, Mobile Apps and Logic Apps)
- API Management
- Event Hubs & Event Grid
- Service Bus
- Azure IoT and Docker
- SQL Server, DocumentDB, CosmosDB, MySQL, …
- Machine Learning, Stream Analytics, Data Factory, Data Pipelines
- and so on
- Microsoft Flow
- PowerApps
- Power BI
- Office365, SharePoint
- DevOpps: PowerShell, Containers
- And much more…
The Microsoft Integration (Azure and much more) Stencils Pack v2.6 is composed by 13 files:
- Microsoft Integration Stencils v2.6
- MIS Apps and Systems Logo Stencils v2.6
- MIS Azure Portal, Services and VSTS Stencils v2.6
- MIS Azure SDK and Tools Stencils v2.6
- MIS Azure Services Stencils v2.6
- MIS Deprecated Stencils v2.6
- MIS Developer v2.6
- MIS Devices Stencils v2.6
- MIS IoT Devices Stencils v2.6
- MIS Power BI v2.6
- MIS Servers and Hardware Stencils v2.6
- MIS Support Stencils v2.6
- MIS Users and Roles Stencils v2.6
These are some of the new shapes you can find in this new version:
 Stencils Pack v2.6 for Visio 2016/2013")
- Azure Event Grid
- Azure Event Subscriptions
- Azure Event Topics
- BizMan
- Integration Developer
- OpenAPI
- APIMATIC
- Load Testing
- API Testing
- Performance Testing
- Bot Services
- Azure Advisor
- Azure Monitoring
- Azure IoT Hub Device Provisioning Service
- Azure Time Series Insights
- And much more
You can download Microsoft Integration (Azure and much more) Stencils Pack from:
Microsoft Integration Stencils Pack for Visio 2016/2013 (11,4 MB)
Microsoft | TechNet Gallery
Author: Sandro Pereira
Sandro Pereira lives in Portugal and works as a consultant at DevScope. In the past years, he has been working on implementing Integration scenarios both on-premises and cloud for various clients, each with different scenarios from a technical point of view, size, and criticality, using Microsoft Azure, Microsoft BizTalk Server and different technologies like AS2, EDI, RosettaNet, SAP, TIBCO etc. He is a regular blogger, international speaker, and technical reviewer of several BizTalk books all focused on Integration. He is also the author of the book “BizTalk Mapping Patterns & Best Practices”. He has been awarded MVP since 2011 for his contributions to the integration community. View all posts by Sandro Pereira
by Sivaramakrishnan Arumugam | Sep 19, 2017 | BizTalk Community Blogs via Syndication
In my previous blog, I spoke about one of the issues we encountered during our support. In this blog, I will specifically be talking about the custom widgets in BizTalk360, which a lot of our customers use to display data that is important to them. Users are able to create custom widgets and associate them with a dashboard. Custom widgets allow integration with BizTalk360’s own API’s, as well as third-party API’s.
The below code in a custom widget shows analytical data in graphical form. In recent times, we received a support case where the customer was trying to create a custom widget referencing the blog. Following should be the result of the custom widget in the dashboard.
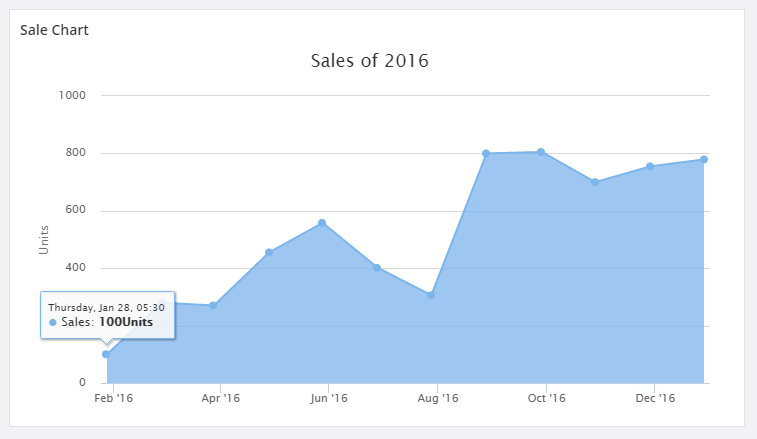
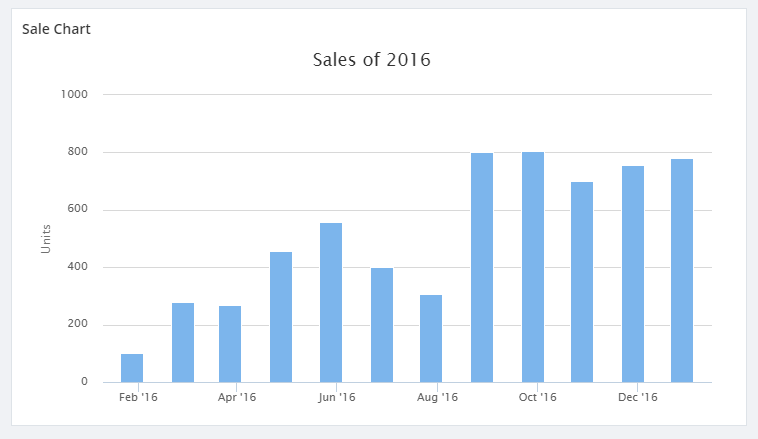
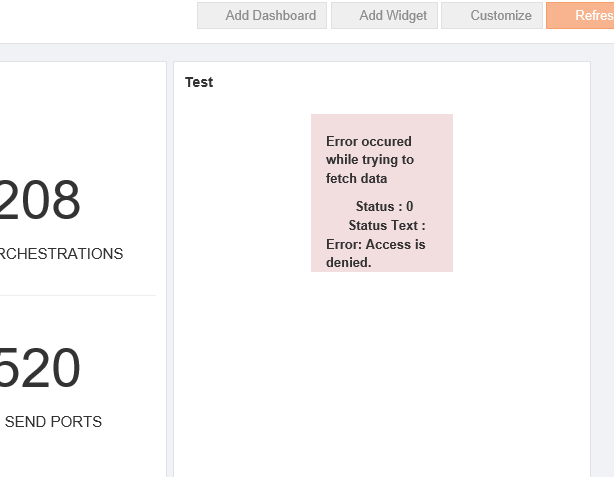
But the customer ended up with the below error after integrating the custom widget.
A script for the custom widget:
<script>
//URL used to get JSON Data for the Charts
this.URL = 'http://rawgit.com/cyberkingvb/CustomWidgetWithChart/master/sales2016.json';
//Refresh interval in milliseconds 60000 milliseconds = 60 seconds
this.REFRESH_INTERVAL = 60000;
//flag to check if widget should auto Refresh
this.AUTO_REFRESH_ENABLED = true;
//Highcharts Options
this.HIGHCHART_OPTIONS = {
chart: {
type: 'line',
zoomType: 'x'
},
exporting: {
enabled: false
},
credits: {
enabled: false,
title: '',
style: {
display: 'none'
}
},
title: {
text: 'Sales of 2016'
},
xAxis: {
type: 'datetime'
},
yAxis: {
min:0,
title: {
text: 'Units'
},
},
tooltip: {
crosshairs: true,
shared: true,
valueSuffix: 'Units'
},
legend: {
enabled: false
},
series: [{
name: 'Sales',
data: []
}]
};
this.widgetDetails = ko.observable();
this.error = ko.observable(null);
var _this = this;
var getdata = function()
{
$.getJSON(_this.URL, function (data)
{
_this.HIGHCHART_OPTIONS.series[0].data = data;
_this.widgetDetails(_this.HIGHCHART_OPTIONS);
_this.error(null);
}).fail(function(errorObject,error)
{
console.log(errorObject);
_this.error(errorObject);
});
}
//loading data for the first time
getdata();
//handles auto refresh
if(this.AUTO_REFRESH_ENABLED)
setInterval(getdata, this.REFRESH_INTERVAL);
</script>
<!-- ko if: error() == null -->
<div data-bind="highCharts: widgetDetails()" style="height:380px; width:700px"></div>
<!-- /ko -->
<!-- ko if: error() != null -->
<div class="row">
<div class="col-md-offset-4 col-md-4 bg-danger">
<b>
<p>Error occured while trying to fetch data </p>
<span>Status : </span><span data-bind="text:error().status"></span><br>
<span>Status Text : </span><span data-bind="text:error().statusText"></span>
</b>
</div>
</div>
<!-- /ko -->
Script Explained
This code consists of 4 configuration variables.
URL
URL variable will allow you configure the API URL from where you fetch the JSON data. Based on the High charts options, the formatting for the data may also change. Here in the above example, the API returns the data as JSON array and date-time stamp as a Unix Timestamp.
AUTO_REFRESH_ENABLED
This flag determines if your widget should be auto-refreshed or not. For instance, if the service call that feeds your chart is very expensive and you don’t want to call that every now and then, then you can probably disable this flag or set the refresh interval to a higher value.
REFRESH_INTERVAL
Refresh interval lets you configure the interval after which the widget data should be refreshed. Note that the interval is in milliseconds. So, if you want it to refresh every one minute then you should set the refresh interval to 60000. Note that for an auto-refresh to work, AUTO_REFRESH_ENABLED flag must be set to true.
HIGHCHART_OPTIONS
BizTalk360 uses High charts for all data analytics. We already have the underlying binding handler framework to apply the options and this makes analytic widget creation a lot easier. To modify the charts, you simply need to update the HIGHCHART_OPTIONS. In this example,
the “data” property inside series array (where the data is supposed to be) is left as an empty array intentionally. It will be filled with the data that is retrieved from the URL that you have specified. High charts support a variety of charts and you can follow this link to get the type of chart that you want to bring into your custom widget.
The line chart that we have created here can be converted into an Area chart or a Column chart by simply changing “type” under “charts” options in HIGHCHART_OPTIONS.
Investigation of the Issue
Initially, we suspected that the customer might not be able to fetch the JSON data using the http://rawgit.com/cyberkingvb/CustomWidgetWithChart/master/sales2016.json URL. When we asked to browse the URL and they could browse and view the results. So, the next step was to isolate the case at the customer end. Whenever such a situation arises we require more information about the customer’s environment, we would go for a web meeting with a screen sharing session. We went for the screen sharing session and we started with the basic troubleshooting steps like checking the configuration, environment etc.
At last, we found that the customer is using https://localhot/biztalk360 and he is trying to monitor http://rawgit.com/cyberkingvb/CustomWidgetWithChart/master/sales2016.json.
Using HTTPS, there is a security code being generated and shared to accept the information between computers. (Say, in client and server architecture). This keeps the information safe from the hackers.
They use the “code” on a Secure Sockets Layer (SSL), sometimes called Transport Layer Security (TLS) to send the information back and forth.
Resolution Provided
When the HTTP is used inside the HTTPS URL, the HTTPS expected a “code” from HTTP. When the response from the widget URL was coming without the code it threw the error message “Access is denied” on the widget.
Hence, It is not possible to create custom widgets with the cross-domain URL. If the HTTPS is used, all the related URL must use the HTTPS.
If you have any questions, contact us at support@biztalk360.com. Also, feel free to leave your feedback in our forum.
Author: Sivaramakrishnan Arumugam
Sivaramakrishnan is our Support Engineer with quite a few certifications under his belt. He has been instrumental in handling the customer support area. He believes Travelling makes happy of anyone. View all posts by Sivaramakrishnan Arumugam

 Stencils Pack v2.6 for Visio 2016/2013")