by community-syndication | Dec 28, 2011 | BizTalk Community Blogs via Syndication
This is a second part of the BizTalk Naming Convention.
Part 1:biztalk: naming convention for the biztalk solutions
<Message> =:
msg_ + <ShortMessageType>
<Variable> =:
var_ + <Name>
<CorrelationSet> =:
cor_ + <Name>
<OrchestrationParameter> =:
par_ + < Name>
<RoleLink> =:
roleLink_ + <Name>
Note: These objects are special BizTalk objects. They are used in
different language context and sometime they use different language syntax. Prefixes
help to differentiate the objects in the XLang expressions.
<Port> =:
<prefix> + <Name>
where
|
Send
|
Receive
|
Send-Receive
(Solicit-Response)
|
Receive-Send
(Request- Response)
|
|
prefix
|
S_+
|
R_+
|
SR_+
|
RS_+
|
Notes:
%u00b7
The Port objects are the only objects which can
be seen outside orchestration. We see them while bind orchestration with Ports,
not the orchestration Ports but Ports created in the BizTalk Administration
Console. Sometimes the orchestration Ports are named as Logical Ports and the
Ports as the Physical Ports. Here
are some considerations about this ambiguity with Port names.
%u00b7
Send-receive prefixes help while Orchestration is
binding with Ports. Ports with different Communication pattern are using different
prefixes.
Example: S_ OrderAck.
Orchestration Object
Types
<ArtifactType> =:
<ArtifactName> + “_type”
Note:
We can see orchestration types in the Orchestration View window in Types. They
are: Port, Multi-part Message, Correlation and Role Link Types. We can use one
suffix the “_type” for all different types because different types are
seen only in the different lists and never mixed. For instance, we can never
see the port types together with message types.
Controversial: Suffixes for types work better than
prefixes, because types are mostly used in the drop-down lists not in the XLang
expressions.
Orchestration
Workflow Shapes
Problems with
orchestration shapes:
- %u00b7
Shapes are too small to display long names (only
12-18 characters are visible).
- %u00b7
We have to hover a mouse over a shape or click
shape to show Properties window to “understand” this shape, to
understand what message it is processed.
Useful features:
- %u00b7
Shapes have names, but names are not the “variable
names”, not identifiers. They are descriptions (excluding the Port shapes names,
which have not Name parameter but Identifier and Description parameters). Shape
names are used only for description not as XLang variable identifiers. Shape
names can be long and can include any symbols as spaces, dots, etc.
- %u00b7
Icons of shapes give us the useful information.
Do not repeat the “icon information” by words. For example, we can a name a
Construction shape as “Construct OrderAck” or as “OrderAck”. Last variant give
us more clear and short definition because we have the Construction icon +
name.
- %u00b7
Shape names are used mainly in Orchestration
Editor (excluding the Port shapes names). We don’t need the “well-sorted” names,
so we don’t need to use prefixes, because the main purpose of the prefixes is
creating well-sorted lists.
- %u00b7
Group shape is a scalable shape. Nesting other
shapes to a Group shape can make a long description visible. Group shape will
display as much text as you want. Group shapes add a lot of documentation value
to the orchestration.
Rules for shapes
- %u00b7
Whenever it is possible use the short
MessageType as a shape name.
- %u00b7
Do not repeat the type of shape icon by word.
- %u00b7
Feel free to use spaces and any other symbols inside
the shape names.
- %u00b7
Feel free to repeat the shape names.
Note: Purpose of the
orchestration and the most of the shapes is in processing the messages. We can
unambiguously describe the messages by the message type. A message type gives
us the main information about a message. That is why in the most cases using
the message type as the shape name gives us the main information about message
flow, about whole orchestration processing.
Example: Send shape with name “OrderAck” means “send OrcherAck
message”.
Controversial: When exception is thrown from a shape,
the error description includes a name of the shape. When we use MessageType as
a name of shapes, many shapes can get the same name. So, if we want to
differentiate shape names for debugging we could use numbers or single letters
in the end of names.
Example: “OrderAck 2”
by community-syndication | Dec 25, 2011 | BizTalk Community Blogs via Syndication
A sample demonstrates the PGP Encryption/Decryption in pipelines.
You can download a code here.
A sample is based on a sample by Brian Jones See original code here
The main additions to original code:
%u00b7
Single pipeline component was separated to two Encrypt and Decrypt pipeline components. It simplifies the pipeline configurations.
%u00b7
Configuration parameters are stored in SSO, which, I hope, improves security.
%u00b7
File names for temporary files are regenerated randomly each time. That eliminates errors in case when temporary file names are based on the inbound file names and pipelines are working simultaneously in several ports.
To build pipeline components you have to download a BouncyCastle.Crypto.dll assembly from
http://www.bouncycastle.org/csharp
.
The solution includes two pairs of the PGP keys. You can generate yours pairs using, for example, PortablePGP utility
http://primianotucci.com
Configuration includes a config file for a SSO Config Store utility created by Richard Seroter.
The test pipeline project includes four pipelines:
%u00b7
Send and Receive pipelines for Encryption
%u00b7
Send and Receive pipelines for Decryption.
To test these pipelines I’ve created four receive ports and four send ports. They create four test workflows:
%u00b7
Encryption on a Receive port:
RP::GLD.Samples.Pipelines.Encrypt.Encode ( PgpEncryptReceive pipeline )
%u00e8
SP:: GLD.Samples.Pipelines.Encrypt.PassThru
%u00b7
Encryption on a Send port:
RP::GLD.Samples.Pipelines.Encrypt.PassThru
%u00e8
SP:: GLD.Samples.Pipelines.Encrypt.Encode ( PgpEncryptSend pipeline )
%u00b7
Decryption on a Receive port:
RP:: GLD.Samples.Pipelines.Decrypt.Decode ( PgpDecryptReceive pipeline )
%u00e8
SP:: GLD.Samples.Pipelines.Decrypt.PassThru
%u00b7
Decryption on a Send port:
RP:: GLD.Samples.Pipelines.Decrypt.PassThru
%u00e8
SP:: GLD.Samples.Pipelines.Decrypt.Decrypt ( PgpDecryptSend pipeline )
To test pipelines:
%u00b7
Use test text files in a Tests\TestData folder
%u00b7
To test encryption:
1.
Copy test files to a Tests\Encrypt\In folder
2.
Encrypted files are created in a Test\Encrypt\Out folder.
%u00b7
To test decryption:
3.
Copy test encrypted files from a Test\Encrypt\Out folder to a Tests\Decrypt\In folder
4.
Decrypted files are created in a Test\Decrypt\Out folder.
by community-syndication | Dec 22, 2011 | BizTalk Community Blogs via Syndication
First: A Disclaimer. Do NOT attempt this in your production environment.You risk loosing data.
We had an issue in a test environment where the Backup BizTalk job was not configured and had caused the log files to fill the disk to it's limit. The data in the environment wasn't important and destroying a coherent backup chain and point in time restore was not a big deal. We just needed to get the environment back fast to allow test to continue.
I quickly wrote and ran the script below that does the job of truncating BizTalk Servers log files to make the environment functional again. Be aware that this will break the coherence of the log backup chain. To get a point in time that you can restore to you could opt to take a full backup immediatly following this operation if that is important to you. Before running this script you should stop all services that uses the database and make sure that all connections are closed if you want to make sure that your databases are left in a transactionally coherent state.
USE master
ALTER DATABASE BizTalkMgmtDb SET RECOVERY SIMPLE WITH NO_WAIT
ALTER DATABASE BizTalkDTADb SET RECOVERY SIMPLE WITH NO_WAIT
ALTER DATABASE BizTalkMsgBoxDb SET RECOVERY SIMPLE WITH NO_WAIT
GO
Use BizTalkMgmtDb
DBCC SHRINKFILE (N'BizTalkMgmtDb_log' , 0, TRUNCATEONLY)
GO
Use BizTalkDTADb
DBCC SHRINKFILE (N'BizTalkDTADb_log' , 0, TRUNCATEONLY)
GO
Use BizTalkMsgBoxDb
DBCC SHRINKFILE (N'BizTalkMsgBoxDb_log' , 0, TRUNCATEONLY)
GO
USE master
ALTER DATABASE BizTalkMgmtDb SET RECOVERY FULL WITH NO_WAIT
ALTER DATABASE BizTalkDTADb SET RECOVERY FULL WITH NO_WAIT
ALTER DATABASE BizTalkMsgBoxDb SET RECOVERY FULL WITH NO_WAIT
GO
Keep in mind that this is just a sample, add and deduct databases as needed, change the name of log files etc. Once done restart the BizTalk Services and you should be good to go.
You really should, as a first, second and third option, configure the Backup BizTalk job to stop unchecked log file growth. The backup job will make sure that log files don't grow out of control. You will however need to set something up to clear away the backup files created instead. Here is one option for doing that.
There is also something you can do to reduce the size of the log files – enable compression. You can read more about that here.
This log file growth happens because BizTalk Servers databases by default uses the FULL recovery mode. Setting the BizTalk Server databases in SIMPLE mode permanently is a so-so idea. If you really do not need and will never do backups and understand that restore or recover in this case will mean re-install and start from scratch, then ok. If that is not the case, then SIMPLE mode is a bad idea. You can read more about why here. I'll give a hint though – DTC transactions.
HTH
/Johan
Blog Post by: Johan Hedberg
by community-syndication | Dec 22, 2011 | BizTalk Community Blogs via Syndication
This is just a log post of a script I put together. When setting up a plattform we are not always certain what hosts and handlers the customer wants. We usually set it up according to common requirements and best practices. In that case it's also interesting to see what hosts are indeed used and not used once the solution is deployed, so you know which ones can be removed if requested. This is a sql script for that. Although this information can be found out using the Administration Console these kind of reports are not easy to get out and there is no one view for it. It's much easier to access the database BizTalkMgmtDb directly for these things.
select h1.Name from adm_Host h1 where h1.Name not in(
select distinct h.Name as Host –, a.Name as Adapter, rp.nvcName as Port
from adm_host h
join adm_receivehandler rh on h.id = rh.HostId
join adm_receivelocation rl on rl.ReceiveHandlerId = rh.Id
join bts_receiveport rp on rp.nID = rl.ReceivePortId
join adm_adapter a on a.id = rh.AdapterId
UNION
select distinct h.Name as Host –, a.Name as Adapter, sp.nvcName as Port
from adm_Host h
join adm_SendHandler sh on h.Id = sh.HostId
join bts_sendport_transport spt on spt.nSendHandlerID = sh.Id
join bts_sendport sp on sp.nID = spt.nSendPortID
join adm_Adapter a on sh.AdapterId = a.Id
UNION
select distinct h.Name as Host –, '*Orchestration' as Adapter, o.nvcName as Port
from adm_Host h
join bts_orchestration o on h.Id = o.nAdminHostID
–UNION
–select distinct h.Name as Host, * –, '*Tracking' as Adapter, NULL as Port
–from adm_Host h
–where h.HostTracking = 1
)
HTH
/Johan
Blog Post by: Johan Hedberg
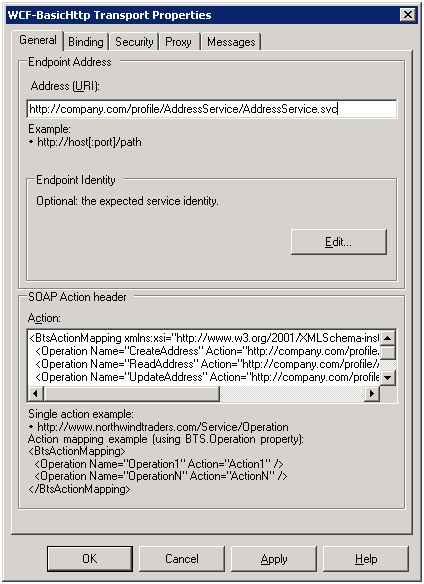
by community-syndication | Dec 21, 2011 | BizTalk Community Blogs via Syndication
One area here is not so well documented.
When we are filling in the Transport properties for WCF adapter, we see the SOAP Action header section.
What is it? Where we could take the values for Operations and Actions?
If we use the Consume WCF Service wizard, this section is filled up automatically. But sometimes we have to fill it in manually.
NP
Open a WSDL for the Web-service and search for a binding section. If you add the “?wsdl” to the Web-service URL, usually the Web-service WSDL is opened.
That’s how operations and actions in the WCF parameters and WSDL are mapping:

Hope it helps.
by community-syndication | Dec 21, 2011 | BizTalk Community Blogs via Syndication
| Here are a few links about Windows Azure Platform performance |
Voici quelques liens sur les performances dans la plateforme Windows Azure |
| NB: this post contains screen shots for the links. Please follow the links to get the most recent and up to date information. |
NB: ce billet comprend des copies d’%u00e9crans mais pour les liens. Il est conseill%u00e9 de cliquer sur les liens pour avoir les informations les plus %u00e0 jour. |
| This list is not exhaustive. Please feel free to provide additional valuable links by commenting this post. |
La liste n’est pas exhaustive. N’h%u00e9sitez pas %u00e0 fournir d’autres liens importants en laissant un commentaire. |
Windows Azure, SQL Azure
http://azurescope.cloudapp.net/ by an MS Research group contains a lot of micro benchmarks.
Note that this site should be shut down quite soon as the results are quite old and performance characteristics may have changed since then. |
http://azurescope.cloudapp.net/ cr%u00e9%u00e9 par un group de MS Research contient un bon nombre de r%u00e9sultats de performances atomiques.
Il est %u00e0 noter que ce site devrait %u00eatre ferm%u00e9 bient%u00f4t puisque les r%u00e9sultats sont assez vieux et pourraient %u00eatre diff%u00e9rents aujourd’hui. |
Windows Azure Compute
Windows Azure Storage
| The Windows Azure Storage team wrote a blog post on their former blog (they now have merged with the Windows Azure blog) about their scalability targets. |
L’%u00e9quipe du stockage Windows Azure a %u00e9crit un billet sur son ancien blog (qui a maintenant fusionn%u00e9 avec celui de Windows Azure) %u00e0 propos de leurs cibles en termes de passage %u00e0 l’%u00e9chelle. |
| They also wrote on how to get the most out of Windows Azure Tables. |
Ils ont aussi %u00e9crit sur la fa%u00e7on de tirer au mieux parti des tables Windows Azure
|
SQL Azure
| SQL Azure Performance and Elasticity Guide on TechNet Wiki provides information about optimizing an application developed against SQL Azure. |
Le guide de performance et d’%u00e9lasticit%u00e9 de SQL Azure sur le Wiki TechNet fournit des informations sur l’optimisation d’une application qui utilise SQL Azure. |
| The following case study is about using many SQL Azure databases to sell 150 000 tickets within 10 seconds. |
Le t%u00e9moignage suivant est sur l’utilisation d’un grand nombre de bases SQL Azure pour vendre 150 000 tickets en 10 secondes. |
Service Bus
| Service Bus is typically an asset that needs to handle a given number of messages per seconds. This and other performance characteristics are to be taken into account. This is described in this guidance page in MSDN Library. |
Le bus de service est typiquement un composant qu’on utilise avec un certain nombre de messages par secondes en t%u00eate. Cela ainsi que d’autres caract%u00e9ristiques de performance sont %u00e0 prendre en compte. Cela est d%u00e9crit dans le guide sur le sujet, dans la documentation MSDN. |
Caching
Tests
| At the end of the day, it is important to get an idea of how your application behaves on the platform. For that , load tests are an important step to consider. Load tests injection can be done by the cloud itself as explained in MSDN library |
Au final, il est important que vous ayez une id%u00e9e de la fa%u00e7on dont votre application se comporte sur la plateforme. Pour cela, les tests de charge sont une %u00e9tape importante %u00e0 prendre en compte. L’injection des tests de charge peuvent se faire depuis le cloud comme expliqu%u00e9 dans la librairie MSDN. |
| Here are a few additional links: |
Voici quelques liens compl%u00e9mentaires |
Benjamin
Blog Post by: Benjamin GUINEBERTIERE
by community-syndication | Dec 19, 2011 | BizTalk Community Blogs via Syndication
| A preview version of Hadoop on Windows Azure is available. The details of that availability is at |
Une pr%u00e9-version d’Hadoop sur Azure est disponible. Les d%u00e9tails de cette disponibilit%u00e9 sont %u00e0 |
availability-of-community-technology-preview-ctp-of-hadoop-based-service-on-windows-azure.aspx
| A good introduction to what Hadoop and Map Reduce are is available at |
Une bonne introduction %u00e0 ce que sont Hadoop et Map/Reduce est %u00e0 |
http://developer.yahoo.com/hadoop/tutorial/module4.html
As a developer using Hadoop, you write a mapper function, a reducer function, and Hadoop does the rest:
– distribute code to the nodes where data resides
– execute code on the nodes
– provide reducers with all the same keys generated by the mappers |
En tant que d%u00e9veloppeur utilisant Hadoop, on %u00e9crit des fonctions de mapper et de reducer, et Hadoop fait le reste:
– distribuer le code aux noeuds o%u00f9 la donn%u00e9e se trouve
– ex%u00e9cuter le code sur tous les noeuds
– fournir aux reducers les ensembles de m%u00eames clefs g%u00e9n%u00e9r%u00e9es par les mappers |
| One of the often used examples is the WordCount example. |
Un des exemples les plus utilis%u00e9s est le comptage de mots (WordCount). |
In this WordCount example,
– the mapper function emits each word found as a key, and 1 as the value.
– the reducer function adds the values for the same key
– Thus, you get each word and the number of occurrences as a result of the map/reduce.
This sample can be found in different places, including: |
Dans cet exemple WordCount,
– la fonction mapper %u00e9met chaque mot trouv%u00e9 en tant que clef, et 1 en tant que valeur.
– la fonction reducer ajoute les valeurs pour la m%u00eame clef
– Ainsi, on obtient comme r%u00e9sultat du map/reduce chaque mot et le nombre d’occurrences pour ce mot.
Cet exemple peut se trouver %u00e0 diff%u00e9rents endroits dont |
http://wiki.apache.org/hadoop/WordCount
http://hadoop.apache.org/common/docs/r0.20.2/mapred_tutorial.html
| Lets’s try this on an Hadoop On Azure cluster, after having changed the code to get only words with letters a to z, and having 4 letters or more |
Essayons cela sur un cluster Hadoop sur Azure, apr%u00e8s avoir modifi%u00e9 le code pour avoir uniquement les mots avec les lettres a %u00e0 z, et ayant au moins 4 lettres |
| Here is the code we have |
Voici le code |
package com.benjguin.hadoopSamples;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
public class WordCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
String[] wordsToCount = Utils.wordsToCount(tokenizer.nextToken());
for (int i=0; i<wordsToCount.length; i++) {
if (Utils.countThisWord(wordsToCount[i])) {
word.set(wordsToCount[i]);
output.collect(word, one);
}
}
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
et
package com.benjguin.hadoopSamples;
public class Utils {
public static String[] wordsToCount(String word) {
return word.toLowerCase().split("[^a-zA-Z]");
}
public static boolean countThisWord(String word) {
return word.length() > 3;
}
}
| The first step is to compile the code and generate a JAR file. This can be done with Eclipse for instance: |
La premi%u00e8re %u00e9tape est de compiler le code et de g%u00e9n%u00e9rer un fichier JAR. Cela peut %u00eatre fait depuis Eclipse par exemple: |
| We also need to have some data. For that, it is possible to download a few books from the Gutenberg project. |
On a %u00e9galement besoin de donn%u00e9es. On peut par exemple t%u00e9l%u00e9charger quelques livres du projet Gutenberg. |
| Then, an Hadoop on Azure cluster is requested as explained there: |
Ensuite, on demande la cr%u00e9ation d’un cluster Hadoop sur Azure, comme expliqu%u00e9 %u00e0: |
http://social.technet.microsoft.com/wiki/contents/articles/6225.aspx
| Let’s upload the files to HDFS (Hadoop’s distributed file system) by using the interactive JavaScript Console: |
Ensuite, on charge les donn%u00e9es en HDFS (syst%u00e8me de fichier distribu%u00e9 d’Hadoop) en utilisant la console interactive JavaScript: |
| NB: for large volumes of data, FTPS would be a better option. Please refer to How To FTP Data To Hadoop on Windows Azure. |
NB: pour de grands volumes de donn%u00e9es, FTPS est pr%u00e9f%u00e9rable. cf How To FTP Data To Hadoop on Windows Azure. |
| Let’s create a folder and upload the 3 books into that HDFS folder |
On cr%u00e9e un r%u00e9pertoire HDFS et on y charge les 3 livres. |
| Then it is possible to create the job |
Puis il est possible de cr%u00e9er un job |
11/12/19 17:51:27 INFO mapred.FileInputFormat: Total input paths to process : 3
11/12/19 17:51:27 INFO mapred.JobClient: Running job: job_201112190923_0004
11/12/19 17:51:28 INFO mapred.JobClient: map 0% reduce 0%
11/12/19 17:51:53 INFO mapred.JobClient: map 25% reduce 0%
11/12/19 17:51:54 INFO mapred.JobClient: map 75% reduce 0%
11/12/19 17:51:55 INFO mapred.JobClient: map 100% reduce 0%
11/12/19 17:52:14 INFO mapred.JobClient: map 100% reduce 100%
11/12/19 17:52:25 INFO mapred.JobClient: Job complete: job_201112190923_0004
11/12/19 17:52:25 INFO mapred.JobClient: Counters: 26
11/12/19 17:52:25 INFO mapred.JobClient: Job Counters
11/12/19 17:52:25 INFO mapred.JobClient: Launched reduce tasks=1
11/12/19 17:52:25 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=57703
11/12/19 17:52:25 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
11/12/19 17:52:25 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
11/12/19 17:52:25 INFO mapred.JobClient: Launched map tasks=4
11/12/19 17:52:25 INFO mapred.JobClient: Data-local map tasks=4
11/12/19 17:52:25 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=18672
11/12/19 17:52:25 INFO mapred.JobClient: File Input Format Counters
11/12/19 17:52:25 INFO mapred.JobClient: Bytes Read=1554158
11/12/19 17:52:25 INFO mapred.JobClient: File Output Format Counters
11/12/19 17:52:25 INFO mapred.JobClient: Bytes Written=186556
11/12/19 17:52:25 INFO mapred.JobClient: FileSystemCounters
11/12/19 17:52:25 INFO mapred.JobClient: FILE_BYTES_READ=427145
11/12/19 17:52:25 INFO mapred.JobClient: HDFS_BYTES_READ=1554642
11/12/19 17:52:25 INFO mapred.JobClient: FILE_BYTES_WRITTEN=964132
11/12/19 17:52:25 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=186556
11/12/19 17:52:25 INFO mapred.JobClient: Map-Reduce Framework
11/12/19 17:52:25 INFO mapred.JobClient: Map output materialized bytes=426253
11/12/19 17:52:25 INFO mapred.JobClient: Map input records=19114
11/12/19 17:52:25 INFO mapred.JobClient: Reduce shuffle bytes=426253
11/12/19 17:52:25 INFO mapred.JobClient: Spilled Records=60442
11/12/19 17:52:25 INFO mapred.JobClient: Map output bytes=1482365
11/12/19 17:52:25 INFO mapred.JobClient: Map input bytes=1535450
11/12/19 17:52:25 INFO mapred.JobClient: Combine input records=135431
11/12/19 17:52:25 INFO mapred.JobClient: SPLIT_RAW_BYTES=484
11/12/19 17:52:25 INFO mapred.JobClient: Reduce input records=30221
11/12/19 17:52:25 INFO mapred.JobClient: Reduce input groups=17618
11/12/19 17:52:25 INFO mapred.JobClient: Combine output records=30221
11/12/19 17:52:25 INFO mapred.JobClient: Reduce output records=17618
11/12/19 17:52:25 INFO mapred.JobClient: Map output records=135431
| go back to the interactive JavaScript console. |
On retourne dans la console interactive JavaScript |
| This generates another Map/Reduce job that will sort the result. |
Cela cr%u00e9e un autre job Map/Reduce qui va trier le r%u00e9sultat |
()
| Then, it is possible to get the data and show it in a chart |
Puis, il est possible de r%u00e9cup%u00e9rer la donn%u00e9e et de la montrer sous forme de graphique |
| It is also possible to have a more complete console by using Remote Desktop (RDP). |
Il est %u00e9galement possible d’avoir une console plus compl%u00e8te en se connectant au bureau %u00e0 distance. |
Benjamin
Blog Post by: Benjamin GUINEBERTIERE
by community-syndication | Dec 19, 2011 | BizTalk Community Blogs via Syndication
I've uploaded a new version of the bLogical.BizTalkManagement restore powershell commandlets originally posted by Mikael. The updates are minor and adress the parsing of filenames and cleanup of the code to get rid of some god intentions that never became more then intentions, aka unused code.
If you have no idea what I am talking about, feel free to read the original article and give them a try. We are using these heavily for customers instead of log shipping and it really makes the whole process of restoring your databases easy.
Blog Post by: Johan Hedberg
by community-syndication | Dec 18, 2011 | BizTalk Community Blogs via Syndication
In this blog post we are going look at how to manage routing in the new Azure ServiceBus EAI CTP.
As a scenario, I’m going to send a request for information (RFI) to some of my fellow MVP’s. To do that, I’m going to create a One-Way Xml Bridge, to receive the messages. After receiving the RFI message I tend to route it to one of three queues.
1. Create a ServiceBus project
If you haven’t already downloaded the SDK, you can do this here. After you’ve installed the SDK, you can sign in to the labs environment using a Windows Live ID.
Open Visual Studio 2010, and select Create Project. In the list of project templates, select ServiceBus, and Enterprise Application Integration. Give it a name and click Ok.
2. Create a Message Type
Right-click the project and select Add->New Item. At this time there are two types of artifacts you can add; Schemas and Maps. Select Schema and sett an appropriate name. In my case I set the name to RFI.xsd. Continue building up your schema. Notice, you don’t have to promote any nodes as you’d have to do in BizTalk.
3. Designing the Bridge
Double-click the BridgeConfiguration.bcs and drag a Xml One-Way Bridge from the toolbox to the canvas. This is going to be your entry point to your process, similar to a Receive Location in BizTalk. Set the name appropriately, and notice the Router Address which is going to be your endpoint in Azure ServiceBus.
4. Add Queues
As stated before, the incoming RFI message is going to be routed to any of the three queues. You might not your message relayed to a queue, and could there for use any of the other Destinations such as Relay– or External Service EndPoints. Either way, the principle of routing is the same.
Connect the Bridge with all Destinations.
5. Configure the Bridge
Next we’ll define the incoming message type(s). Double-click your Bridge (ReceiveRFI in my case). Click the plus button in the Message Types stage. Select the Message Type you created earlier, and click the arrow button on the right.
6. Enrich the Message
This is the interesting step, where we are going to promote some fields in the payload so that we can route on these in the next step.
First open your schema and select the node you care to use for routing (in my case Receive). Copy the Instance XPath from the Property window.
Then double-click the Bridge, select either of the Enrich stages, and then click the Property Definition button in the Property window. There are two Enrich stages, as you might be using a Transformation, in which case you might want to promote fields from either the original message or the transformed message.
For more information about transformations, have a look at Kent’s post.
Set the Type to XPath, and paste the XPath expression in the Identifier text box. Select the Message Type and set the name of the property. Finish be setting the data type and click the Add button (+). Close the dialog by clicking the Ok button.
7. Set the routing conditions
As you have promoted your property (or properties), you’re now ready to set the Filter Conditions on each of the Connectors. Select one of the selectors and type the Filter in the Property window. Eg. receiver=’SteefJan’ or customerId=1234.
8. Create the Queues
Before we deploy the solution, you need to create the queues. There are several tools for this, but with the samples comes a MessageReceiver project you can use.
Type MessageReceiver.exe <Your namespace> owner <Your issuer key> <Queue name> Create
After creating the queues verify they are created in the portal.
9. Deploy your solution
Right-click the project and select Deploy. Supply the secret.
10. Test the solution
Along with the MessageReceiver tool, you’ll find a MessageSender project as well. Just type:
MessageSender.exe <Your namespace> <Your issuer key> <Your endpoint> <Path to sample file> application/xml
Use the MessgeReceiver to get the messages from the queues:
HTH
Blog Post by: wmmihaa
by community-syndication | Dec 18, 2011 | BizTalk Community Blogs via Syndication
There are a lot of reasons why the 2011 holiday season is a great time to take a look at Azure development. There are a number of offers and releases that allow you to start to explore cloud-based development on the Microsoft platform, best of all; they are all pretty much free to take advantage of.
$0 Spending Limit on Azure Trial & MSDN Accounts
Ever since the introduction of billing for Windows Azure it has always been an issue for many developers wanting to learn Azure that, if you are not careful, you can easily run up charges on the trial accounts when going above the free quotas.
With the “$0 spending limit” available on 90 day trial and MSDN accounts Azure development developers can start to explore the Azure platform without fear of an unexpected bill at the end of the month. You will, however, have to enter credit-card details.
It is great to see this option available, I know it is something that developers have been clamoring for ever since billing was introduced on the platform. Hopefully this will be extended to a fixed-price limit on Azure billing at some point in the future.
Details of the trail offers are
here
.
No Charge for Azure Service Bus until April 2012
The Azure Service bus provides brokered and relayed messaging capabilities hosted in Windows Azure datacenters. Launched in CTP in 2007 under the name of “BizTalk Services”, then re-branded to “.NET Services”, “AppFabric Service Bus”, and now “Azure Service Bus” the messaging services are a great way to explore the capabilities of Azure when creating hybrid (part cloud, part on-premise) applications.
I’ve spent a lot of time exploring the brokered messaging capabilities of the service bus and am very impressed with the functionality provided. With four months of being above to use the services for free (data transfer charges still apply), now is a perfect time to gain some experience of using the technologies, or even create a small proof-of-concept application in your organization.
You may like to check out my free e-book on the brokered messaging capabilities of the service bus “The Developer’s Guide to AppFabric”. It’s available
here
.
As “AppFabric” has been dropped from these branding of the service bus I’ll be re-branding the title of the book in the next release.
Details of the offer are
here
.
CTP of Azure Service Bus Integration Services
If, like me, you have been following the long and winding roadmap of BizTalk Server, and want to get an early insight into what “BizTalk vNext” will look like, now is your chance.
The first CTP of Microsoft’s cloud-based integration capabilities has been released and is available to use in the AppFabric Labs environment. As the technology is in developer-preview mode, it’s free to use, no credit card required!
Details of the CTP are
here
.